Does anyone know how to replace empty values by a given number (e.g. -999) when using the “Pixel Extrac Values” in SNAP? I don’t want empty cells in the text file provided by the pixEx tool…
you can change them before extracting in the band maths:
IF band == -999 THEN 0 ELSE band
where band stands for your raster and -999 stands for your NoData values. In my example, they are replaced by 0. Afterwards you can extract the pixels from the generated raster.
Thanks for your response, but I think this is not what I really need (may be I didn’t explain it right). When I use the pixel extraction tool in SNAP to extract values for a given pixel for a series of images, the output text file includes just an empty space when a value is not extracted for a given band. To later process the text file with a number of rows and columns, this implies that different rows has different number of columns. What I want is just an output text file with some value instead of an empty space.
I see, sorry.
Would it help to uncheck the nodata value in the properties before extracting?
Also the valid pixel expression could be cleared so a value is left in any pixel.
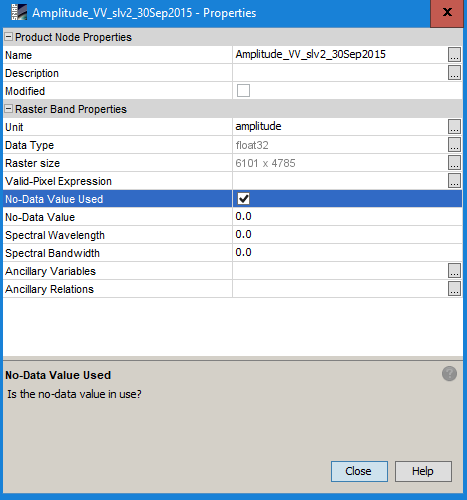
I will try… but I need to avoid to change the properties image by image, because I have a huge amount of files. I guess the best solution would be a kind of option in the “extract values” tool (e.g. to assign a given value when no-data is found)
Why can’t you work with the empty fields? It should be easy to fill those empty fields in Excel or a text editor with ‘search and replace’.
We could write ‘NaN’ or something like this instead of the empty field, but this wouldn’t help you further I guess.
Your suggestion to provide a single value for such cases is not sufficient. Because for the one band it might be outside of the valid range but for other it might be inside. Actually you would need to specify for each band a replacement for the ‘empty value’.
Yes, in fact I use excel to replace empty fields with another value (-999). But I would like to avoid this “manual” step. For example, I am using IDL to read the text file. Let’s say that I have the following matrix:
10 20 33 45
21 14 e 78
(where “e” means empty value). If I read the first row, IDL identifies a vector with 4 components, and the value for column 3 will be 33. When I read the second row, IDL identifies a vector with 3 components, and the value for column 3 will be 78. May be the issue is how to identify empty values with IDL…