that indicates that something with the DEM is wrong. It depends on your study area if Ellipsoid correction is sufficient for accurate geolocation. If you have much topography, your product will probably not be geocoded well.
Are you sure you have installed all updates (Help > check for updates) and selected SRTM 1Sec (AutoDownload)?
Alternatively, you can manually download a DEM and use it as an external DEM during the terrain correction.
Ok thank you ABraun
Hi ABraun
I have applied Grey level co-occurrence matrix on sentinel 1 preprocessed image and the value of the result is very high.I have attached hereunder Dissimilarity as example.Is there a standard interval number to represent these values? or is it correct value?
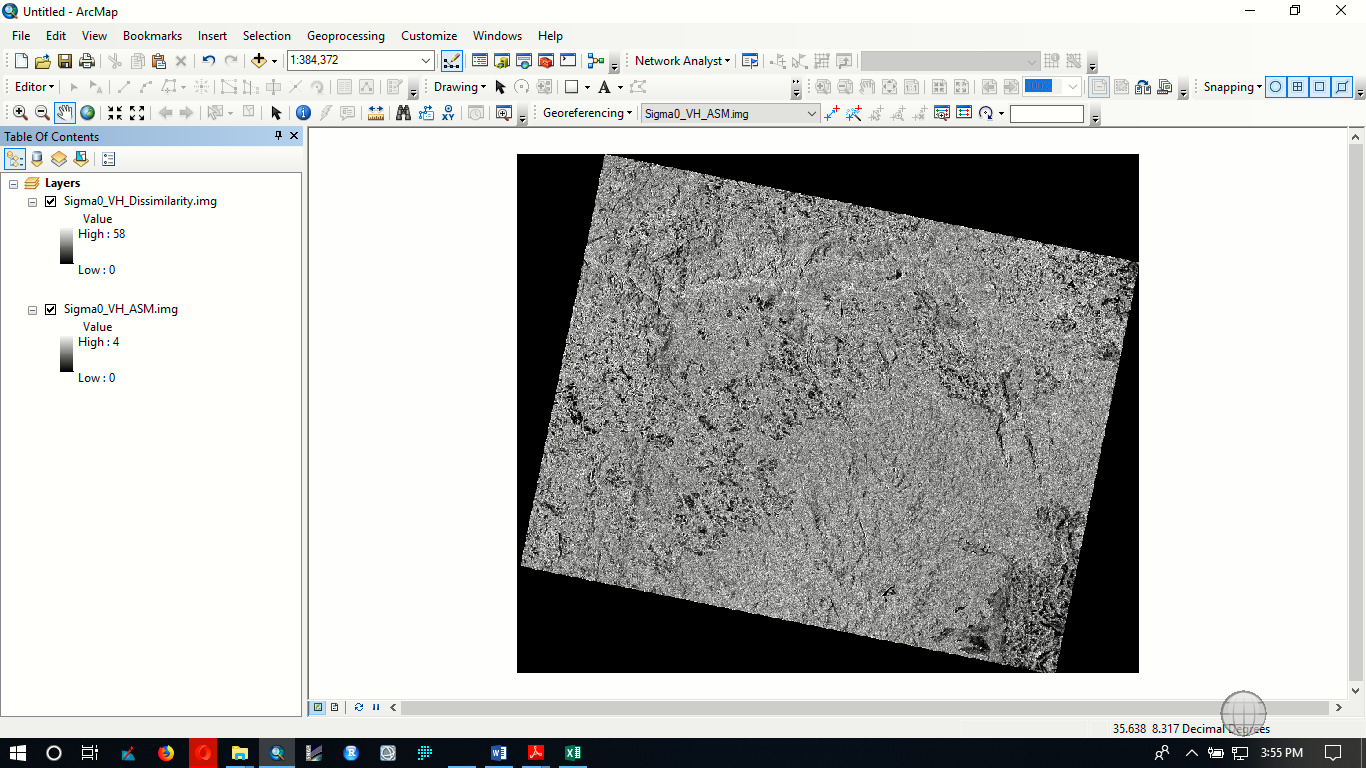
did you convert the data to dB before calculating the GLCM?
Sigma0 has a quite imbalanced histogram, so high values cause stronger dissimilarities than in log-scaled data.
power scale
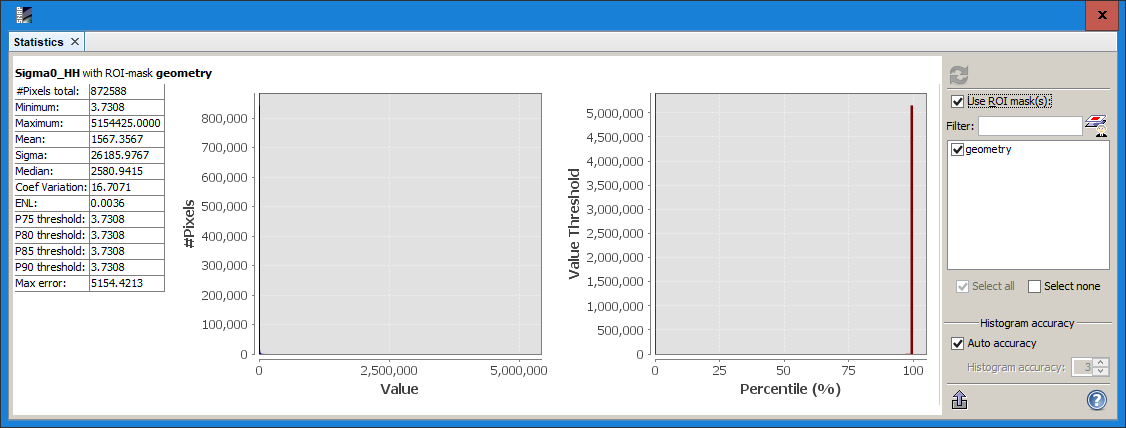
dB scale
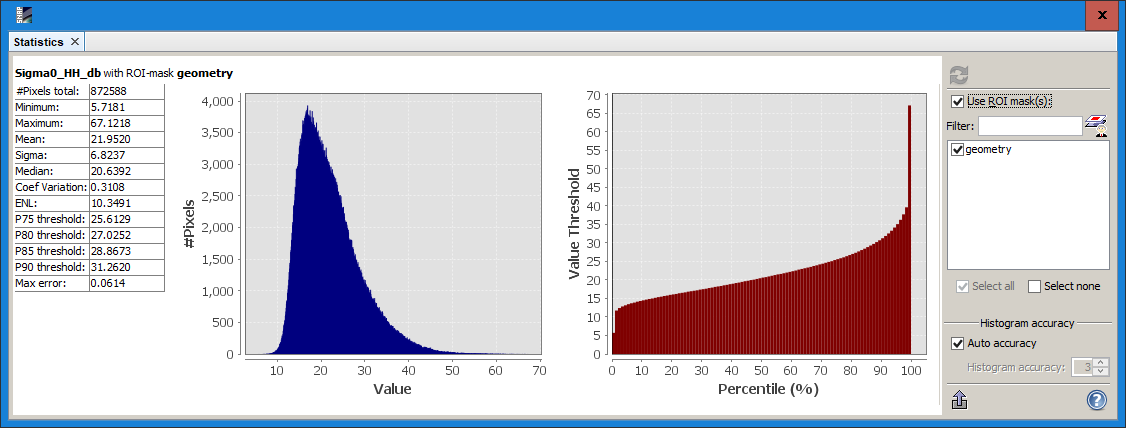
power scale (left) vs log scale (right)

1 Like
No I did not converted it but done it now and the result is increased as you can see in the following picture.I have seen on one paper that the value extracted from GCM must be between 0 and 1,is this true?
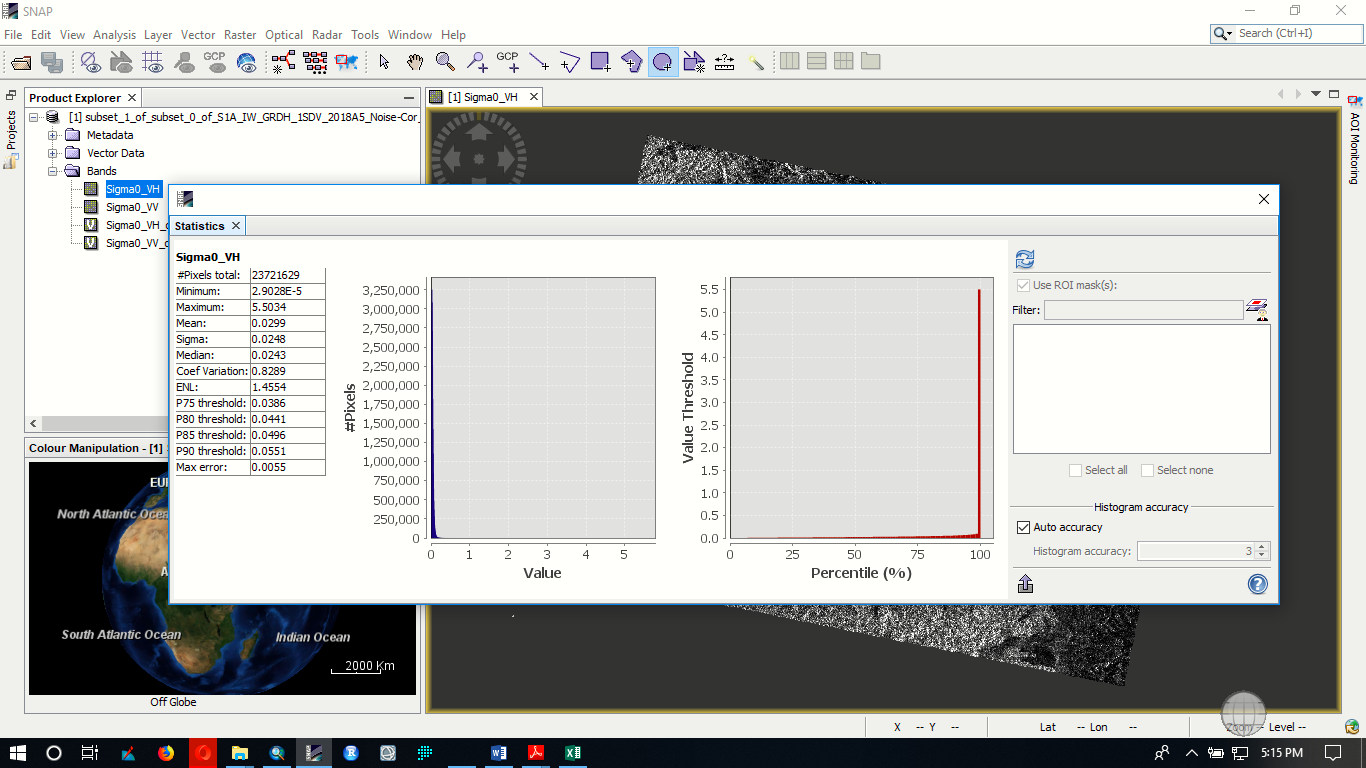
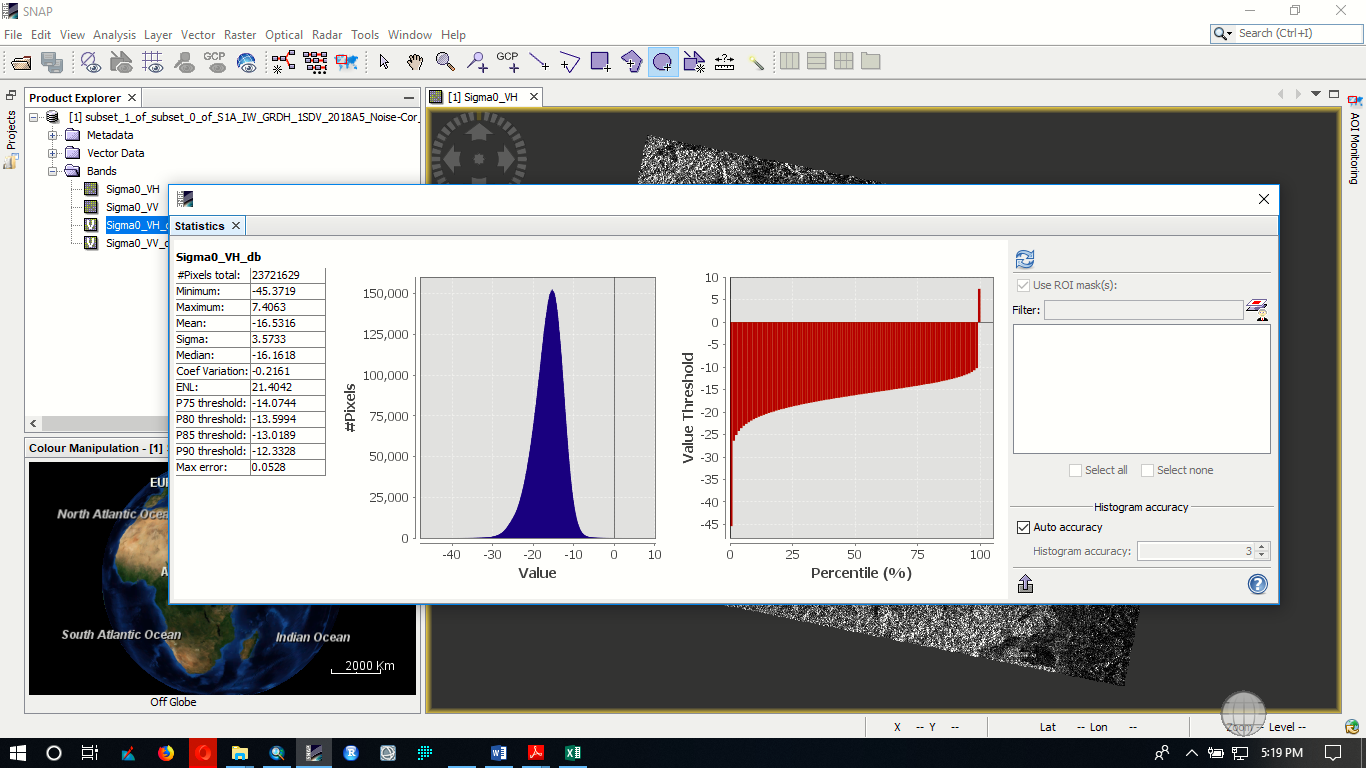
Has the value range of the GCLM changed after conversion to dB?
Your screenshots only show Sigma0
I don’t think all of the texture measures will lead to [0-1] ranges. At least in my case the often differed.
Yes it is changed but increased
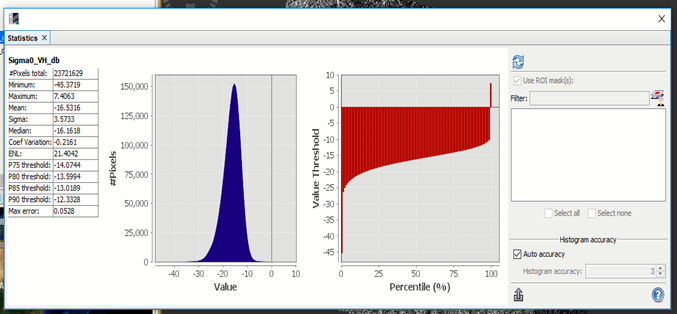

can you please show a histogram of the heterogeneity calculated on the Sigma0db data?
Hi. Could any one please help me what is the preprocessing steps for GLCM feature extraction from Sentinel-1 data GRD format data?
Basically these without speckle filtering: Radiometric & Geometric Correction Workflow
Actually calculation of textures should come before terrain correction, but this requires more space than doing it afterwards.
I also want to mention that the result of the textures is strongly depending on the parameters. So carefully testing and comparing results is advisable, also because some of the textures are quite redundant, so there might be no need to compute all of them.
Should I implement multilooking step too?
Not really, unless your data or scale id too large