I’ve successfully built an executable jar of a java maven project which uses the SNAP software. This runs fine on a Windows machine, on a Mac machine, etc.
We’re now running it on a Google Cloud virtual machine which we’ve given 50 Go of RAM with 8 processors. We expected our processing to run much more quickly, because usually we run it on a 16Go 8 core computer. But it’s taking quite a while, and monitoring shows that the processing is using only one core at 100% and the RAM at only 5 Go.
Adding the arguments below push the RAM usage to max 15Go.
I am collaborating on this work. To answer your question, it is the same code that we used on out desktop computers that we run on our VM. Once it gets to the K-Means processing, all efforts are then directed to one core, whatever the machine we run it onto. RAM usage reaches a comparable max usage for both desktops and the VM, which makes us think the issue may not actually be related to memory.
Okay, I had another look: Some parts of the KMeansOp is parallelized, but there is a part that is not that might take some of the work. In this case, the parallelization would only occur at the end of the processing. Is that the case? Or is there really just the one core used all the time?
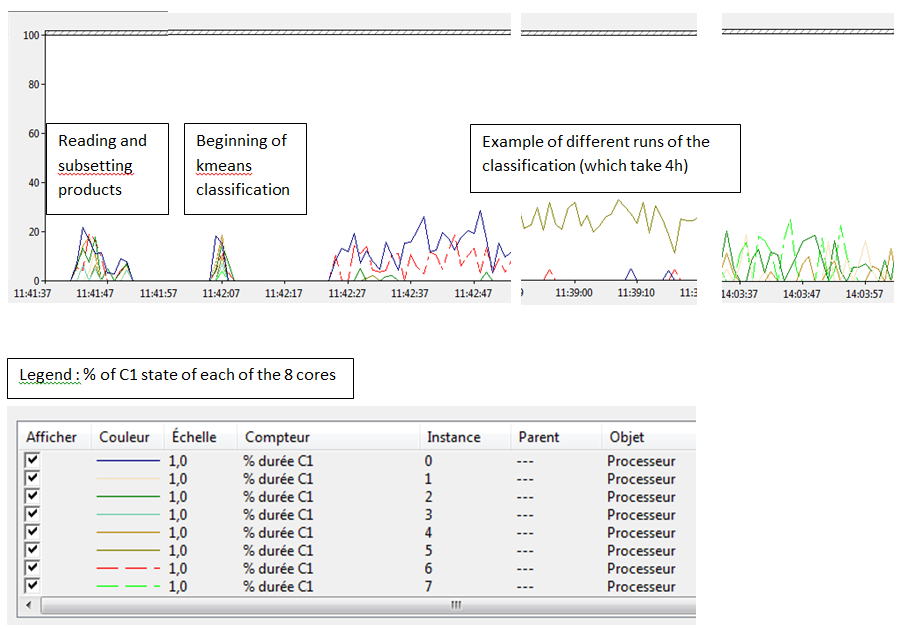
Hi Tonio, I tried to monitor ressources during a run of the classification. I’m not super handy with the windows performance analyzer tool, but from what I gather C1 state shows if a core is being used or not. Here’s a summary of what cores are being used during the processing. All cores seem to be involved in reading and subsetting the different products, and in the beginning of the classification. This activity lasts a couple of seconds. Then, for 4h the activity looks like one of the three examples I put. I didn’t notice anything different happening at the end, so if it did it was brief. There seems to be either 1 or up to sometimes 3 cores involved in the classification.
Like I said, this is not my expertise so if this is a bad metric to document what we are interested in please let me know.
The main work of the K-Means clustering is done single threaded. The memory requirement isn’t very high.
As the algorithm is an iterative approach it reads in each iteration all pixel and computed the cluster center until the result converges or the maximum number of iteration is reached.
While the iterations have to happen sequentially, in each iteration there are some parts of the algorithm that can be done in parallel e.g. the computation of the closest cluster centers. But the current implementation does not do this.
An approach we are using in such cases is to compute multiple jobs on the same machine, each using only 1 or 2 cores. If the number of products is bigger than the number of nodes this will shorten the overall time.
Thank you for your insight, this is an interesting idea (to run multiple jobs on the same computer). I will most certainly keep that in mind when I have a list of classifications to do !