I am facing problems with PCA tool. EO expert runs PCA on Windows and I run the same on Linux on the same inputs but I got different results. I am sure that we have the same inputs and the same parameters for the tool. Any help appreciated.
Are both PCA calculations using the same software? How different are the results? It is not unusual to get minor differences on the order of 10^-5 for the same algorithm implemented in different languages.
1 Like
Thanks both. We use the same SNAP (version 8), the module is PCA version 8.0.2.
@gnwiii You are right the differences are small, close to zero (10^-5). The problem is that later we do unsupervised classification with kmeans clustering and there the differences are quite visible. So some pixels are targeted to different class and the difference in some areas is more than 10%. See the image
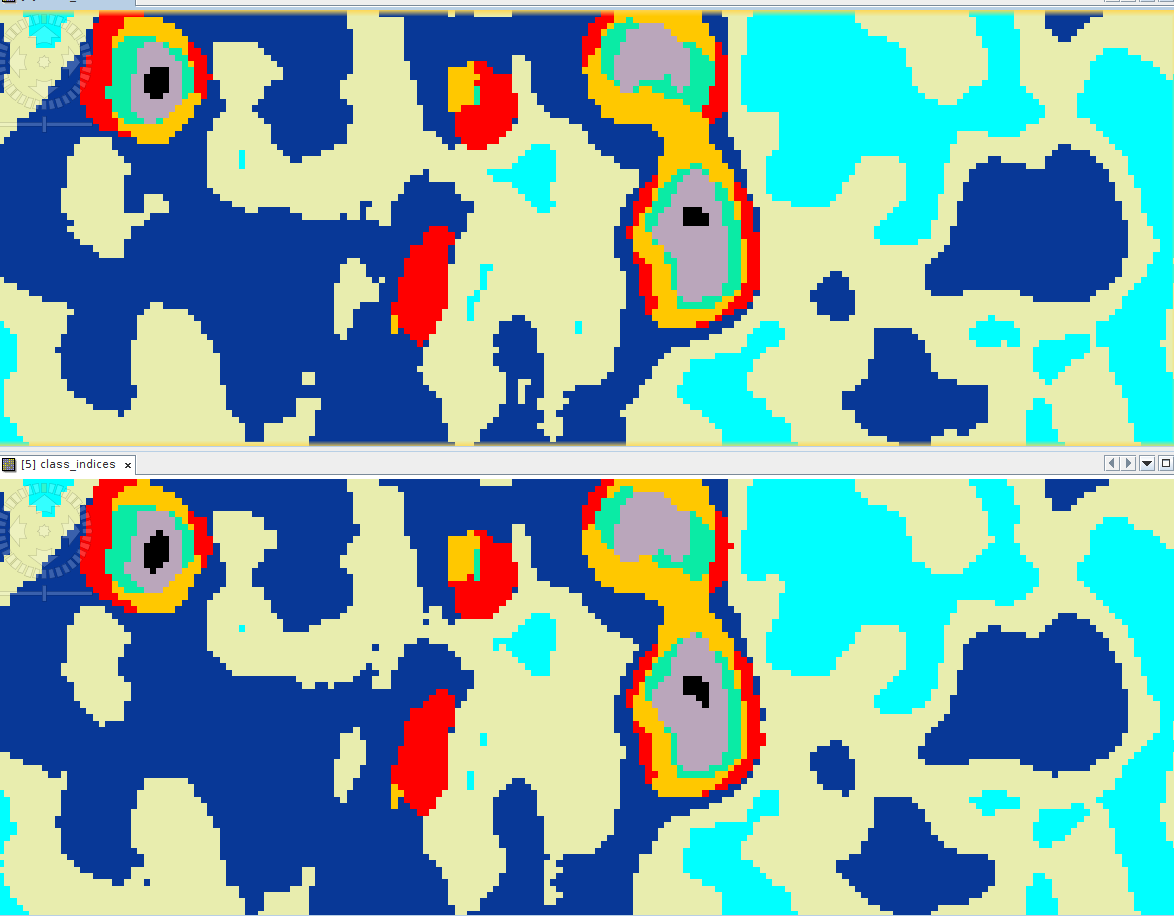
The overall patterns are similar. With clustering you can get thresholds where two slightly different calculations will affect cluster membership, so you always need to be wary of drawing conclusions that aren’t robust to such differences.
It can, however, be helpful if you can get the same software and data to agree bit-for-bit when run on different systems as small differences could be due to a subtle bug. Parallel processing on modern hardware can introduce a bit of randomness due to differences in single instruction multiple data (SIMD) support from the CPU and compilers and even differences in optimizations that reorder calculations.
Unsupervised classification such as K-means and EM uses random initiation of clusters. Because of this randomness, the result may be different each time when running with the same parameters and on the same system, although only a tiny bit. Try increasing the number of increments/repetition to highest possible.
1 Like
This is a good point. When comparing results on different systems it is helpful to set the “seed” for the pseudo-random number generator so you use the same initial state. Statistical software generally supports this. SNAP Help for “KMeansClusterAnalysis Operator Description” indicates that the default seed value is “31415”, but you can set a different value in “Processing Parameters”.
Thank you both. We use the default seed value 31415, but only default 30 iterations. So I will try to increase the number of iterations.