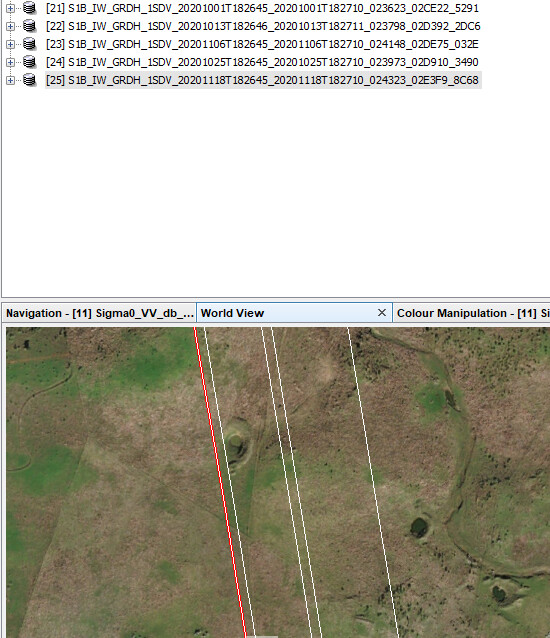
I have a sentinel 1 time series preprocessed (same coordinate system) in which the pixels don´t exactly match from one image to the other. There is a discrepancy of half pixel as you can see below:
How can I solve this issue? Can I apply collocation, coregister or geo-coding tools? The last one is just for SLC products I guess. Or is it something else?
Using the above graph and gpt, I preprocessed 15 Sentinel 1 images automatically from various dates trying to get individual bands (VV and VH) in GeoTIFF format in order to be able to use them later on in Python as I need the bands individually to perform other tasks (ratios, for example). They all seemed well, but a close look showed me almost a different extent for each one of them. They all have the same map projection, set in terrain correction.
Is it the workflow correct? Should I apply some other tool in the workflow to prevent this from happen so they overlap perfectly?
Not sure if it´s a good option to create stack (didn´t work for these GeoTIFF images, tried with some other .dim files and worked ) and then unstack (which I couldn´t do in snap).
Appreciate any hints to help me solve this.
Since the images have different extents even before the preprocessing and to prepare them for further analysis with the pixels in exact same position from one image to another, is there a way of getting VV and VH GeoTIFF´s separately without having to stack and unstack (which I had to use BandSelect operator) as this procedure is very time/memory consuming?
Alternatively, is there a diferent method to accomplish this? What are the best practices on this?