Hello,
I’m an internship in an interprise and I want to do Random forest classification. I searched the forum for some information on the random forest classifier but I did not find answers my questions, It would be very helpful if anyone can guide me through the following questions
1- I have understood that the number of « training samples » that I provide the algorithm with as input correspnds to the number of training samples that the algorithm will use for each class? Is this true? Or is it the total number of training samples for all the classes?
2- Is it possible to choose the number of training samples for each class separately? Or this number is unified for all the classes?
3- What is the percentage of pixels in the input used for training and validation? Can we also tune this parameter?
4- Does the algorithm use for validation the same pixels it uses for training?
5- I see that there is a confidence associated with the classification. However, is there a probability matrix that defines the probability of each pixel belonging to each class?
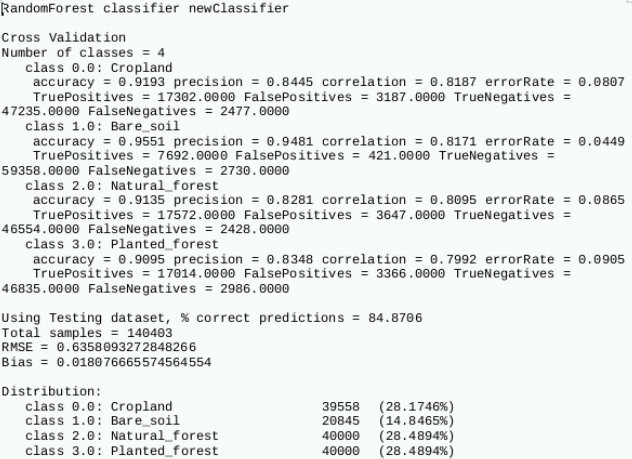
6- In the following example, I defined the input to the algorithm as 80000 training samples. However, the number of pixels in the classes Bare_soil and Cropland is less than 40000 (which is the half of the total number of training samples). How is the validation is carried out in this situation?
Any information would be appreciated. Thank you in advance.
Romain