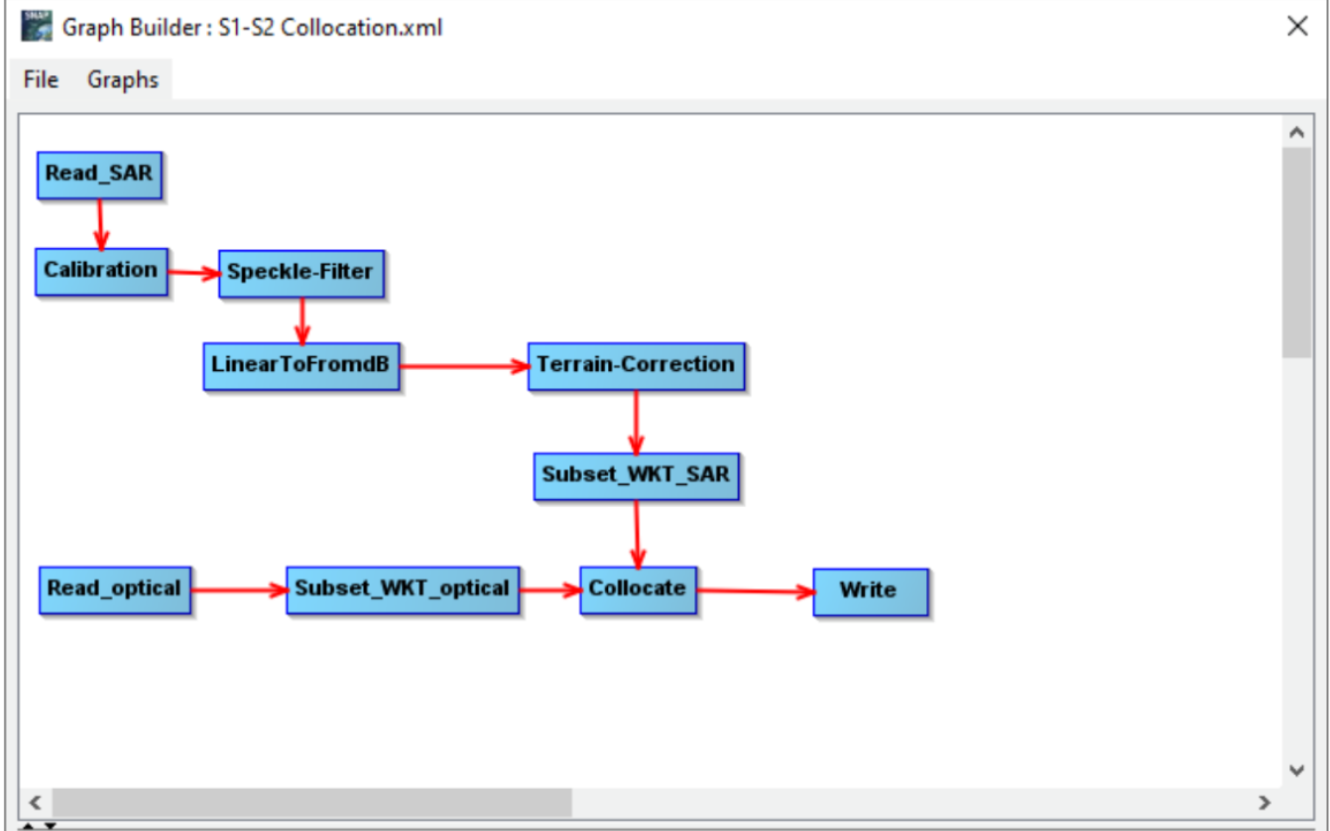
Hi everyone, I am a beginner user. My operative system is Macos (M1 chip).
I know how to perform S1-S2 collocation by using SNAP interface and the attached graph. However, I should automate this process, since I need to build an annual dataset of collocated S1-S2 images, looking at a certain wheat crop. I should have some questions for you.
-
Is it possible run the attached graph in an automated way by using the batch processing in SNAP interface, without resorting to a programming approach?
-
Here https://senbox.atlassian.net/wiki/spaces/SNAP/pages/70503475/Bulk+Processing+with+GPT
there is a tutorial for batch processing from the command line, with an example .bash file (S2 resampling graph)
I understand the logic of the .bash script, but I am not very confident with this kind of scripts.
processDataset.bash (1.5 KB)
Would you be so kind as to explain me how to adapt this script to the context of the attached graph, which takes as inputs two observations rather than only one? Or to indicate me a .bash file related to the task of collocation? -
Is it possible to automate the collocation process by using a python script and the API snappy? In such a case, could you suggest some scripts o tutorials about this?
-
According to you, there exists another way to automate the collocation process, that is simpler than the just mentioned SNAP-based possibilities?
Thanks in advance, hoping someone could help me ![]()
Luca Liverotti
PhD Student in “Mathematical Models and Methods in Engineering”
Politecnico di Milano, Dipartimento di Matematica
MOX Laboratory