Another question… just want to make sure it’s working correctly. The ancillary data are stored in nested directories first by year, then julian day. In one Julian day folder, there are 3 files- 1 AURAOMI_24h.hdf and 2 MET_NCEPR2_6h.hdf.bz2. Is the code going through all of these and matching the OLCI dates with the correct ancillary data date?
Yes, the directory structure is correct. First the year and then the day of year.
The same way as the data is provided by the OBPG here: https://oceandata.sci.gsfc.nasa.gov/Ancillary/Meteorological
If the data is not found locally it is downloaded to the folder you have specified in the parameters.
If the ancillary data cannot be found locally and cannot be downloaded you will see a message on the command line saying somwthing like “Fallback interpolation” and that a default values will be used.
Hello there,
I’m also trying run the gpt for bulk S2 processing with the C2RCC processor.
I managed to adapt the batch script despite spaces in path and I ran it with an xml graph which included only resampling, everything OK.
As I try to make the graph more complex and include the C2RCC processor after the resampling and a subset of only particular bands it fails. The error I get is
Error: [NodeId: c2rccNode] Operator ‘C2rccMsiOperator’: Mandatory source product (field ‘sourceProduct’) not set.
In my xml graph the source is the output of the resample node, as the C2RCC operator expects resampled products. I’m actually a bit confused why all graphs discussed until now include only the processor itself, do you resample the products manually before?
Here is my graph CompleteC2RCCGraph.xml (1.2 KB) .
Do you have any suggestions how I can run it or am I missing something?
Thanks in advance!!
Problem solved:
if you want to do bulk processing with resample -> c2rcc you should include Read in the graph, otherwise GPT would give you an error. Here’s how the graph should look:
resample-c2rcc.xml (1.4 KB)
and in the script you call the variable ${sourceProduct} with -PsourceProduct=/path/to/source/file.SAFE
Cheers!
2 Likes
thank you for reporting the solution - I’m sure others will benefit from it.
dear irgan
i tried to adapt your xml.
where should i put “-PsourceProduct=/path/to/source/file.SAFE”?
in the graph xml or in the parameters file as mentioned in “https://senbox.atlassian.net/wiki/spaces/SNAP/pages/70503475/Bulk+Processing+with+GPT#BulkProcessingwithGPT-KnownLimitationsoftheScripts” ?
when i run the batch gpt, it sends error “Error: [NodeId: Read] Specified ‘file’ [ReadOp@sourceProduct] does not exist.”
could you help me?
thanks
Hi!
“-PsourceProduct=/path/to/source/file.SAFE” doesn’t go either in the graph xml, nor in the parameters file.
In the xml-graph you’ll call products with
<node id="Read"> <operator>Read</operator> <sources /> <parameters class="com.bc.ceres.binding.dom.XppDomElement"> <file>${sourceProduct}</file> </parameters> </node>
this thing you don’t change. Here with ${sourceProduct} you define a variable which will run over a list of files (meaning all files, ending with .SAFE in the folder /path/to/source/ ). This variable you’ll call in the script with which you’ll run the graph - the .batch or .bash script (depending on your OS). If you don’t use a script, but just run the graph directly from the command line you put the “-PsourceProduct=/path/to/source/file.SAFE” in the command line.
Here you have examples of how to make your script for bulk processing with the gpt. In the end you have also examples how your command line should look like for Windows or Unix OS.
https://senbox.atlassian.net/wiki/spaces/SNAP/pages/70503475/Bulk+Processing+with+GPT
1 Like
dear @marpet and the others.
i have been succesfully using GPT batch process for C2RCC OLCI.
i suffer a really slow process using this batch process.
for one full scene of OLCI using GUI on SNAP, it tooks 11 to 15 minutes. using GUI, the processor was fully loaded (i’m using i7-770HQ, 48GB of RAM).
in the other hand, when using GPT batch process, it tooks 30-45 minutes to process one full scene. and the processor works on 25-35%.
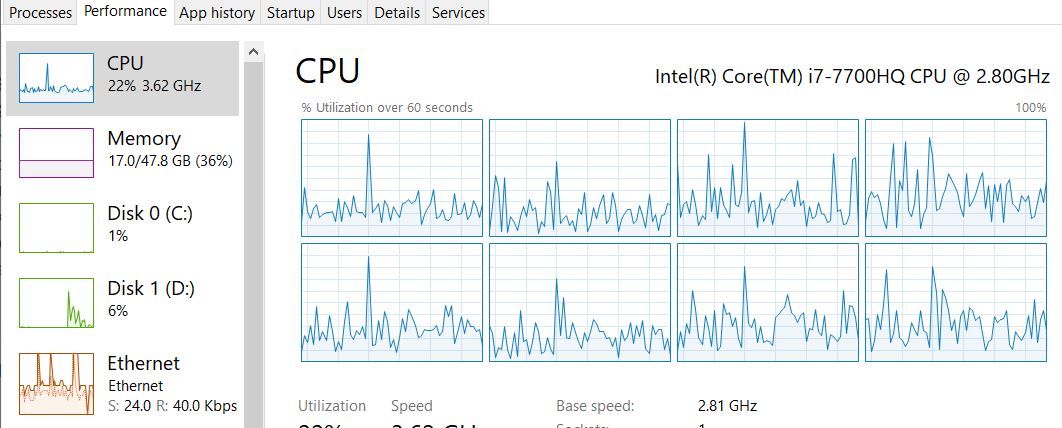
i’m trying to use parallelism -q 8 (i have 4 cores 8 threads), and it was the same, it tooks 30-45 minutes for one scene.
is there any other optimization techniques to cut the process time and maximize the cpu performance?
here’s some screenshot of my snap.properties
thank you for your kind help
We worked on this issue and the processing should perform better with the next version of SNAP (not to far away). For the moment there is not much you can do. Sorry
1 Like
thanks for the information @marpet
when the update is coming, should i re-install the SNAP or just perform update on SNAP (help -> check for updates ?
As it will be a new major version you need to reinstall SNAP.
1 Like
Hi there,
Similar to the OCLI above, I am attempting to run C2RCC for MSI through and graph builder XML I created to batch process files.
I am running into an error for the validPixelExpression parameter.
The error states: Cannot convert “B8 > 0 && B8 < 0.1” to double.
But when I look at the xml template (using gpt c2rcc.msi -h) it says the parameter should be a string, which is what I have passed:
“B8 > 0 && B8 < 0.1”
I am stumped on what I can do to fix this error. Any help is greatly appreciated!
It is strange that it says cannot convert to double. Because it must convert to boolean.
But probably you need to escape some of the characters.
Please, have a look at his post:
Sorry, I should have been more specific. I had passed the string with escape characters already and still received this error.
Could you try like this?
<validPixelExpression>B8 > 0 && B8 < 0.1</validPixelExpression>
Thanks for your help! I had been using the escape characters as you show me, but I was passing the string with double quotes “B8…”. Once I removed the quotes it works fine.
1 Like
A question regarding saving the C2RCC output as NetCDF:
by saving the data in that format I get enormous files, as big as 1GB for a subset of approx. 50km x 25km. I have both land and sea area in the subset and it saves values for the land pixels as well. Land/Sea mask would be a possible solution, however if I apply it to the graph, it produces empty files. Any suggestion how to work with that?
subset-resample-LSmask-c2rcc_v4.xml (2.8 KB)
If the amount of data is too much you can disable some of the output bands. You could also resample the data to 20m instead of 10m to reduce the amount data. And when you use NetCDF you should use NetCDF4 as output format. This format allows for lossless compression.
For Sentinel-2 data there is actually a default valid pixel expression (B8 > 0 && B8 < 0.1) which excludes the land pixels. And land should be set to NaN.
Hello!
Could you please tell me why this graph is not running. Error: The tile offset -257 is < 0.
Res_Graph.xml (1.5 KB)
or this graph
Res_C2RCC_Graph.xml (2.8 KB)
Are you using the latest updates of snap?
It could be helpful if you post the log file.
Please see How to find the log files?