Do I need to increase the number of classes?
what happens if you delete this expression?
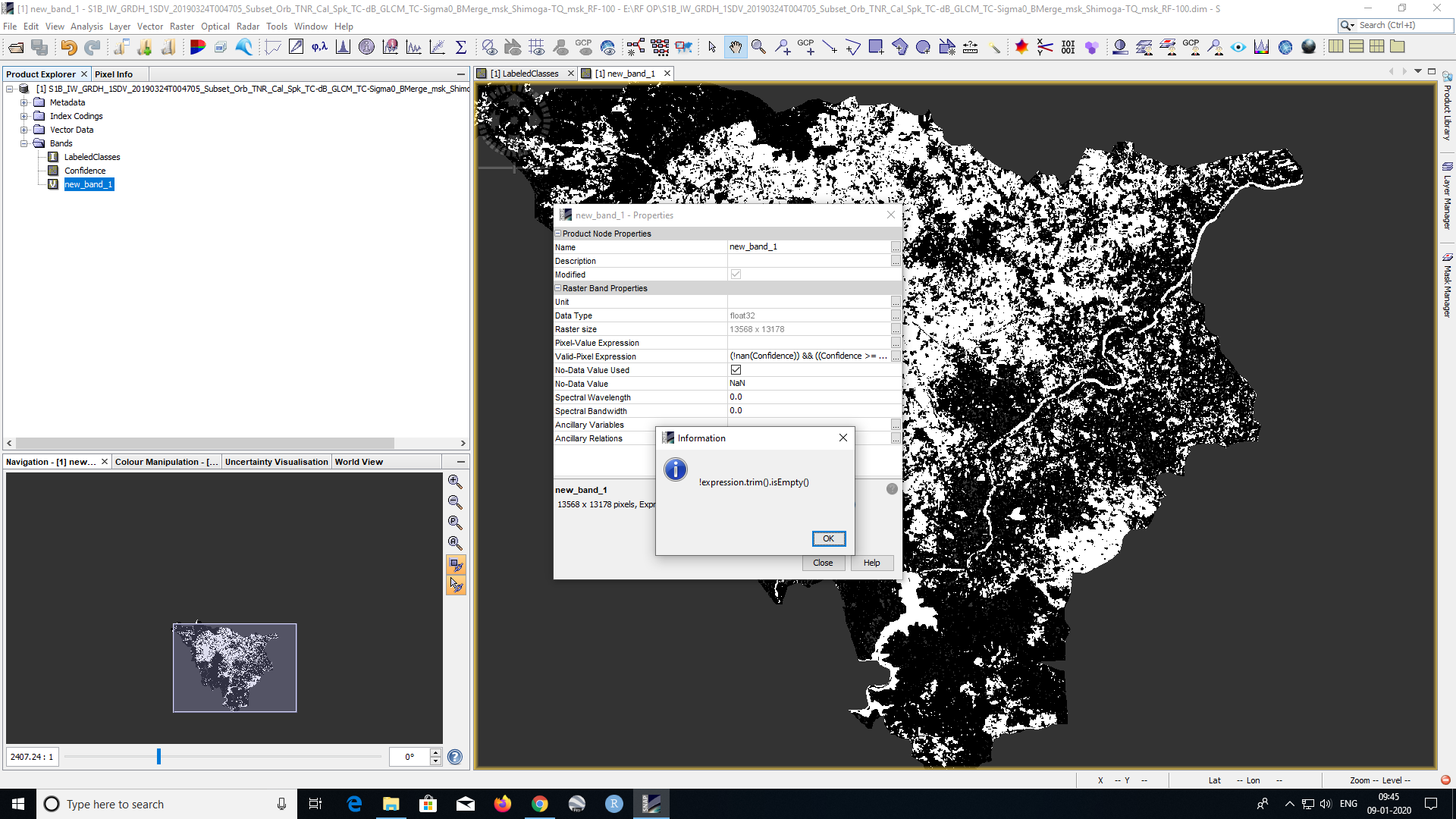
@ABraun When I put the same expression to LabeledClasses band, I got this result:
and if you reduce 0.5 to 0.0?
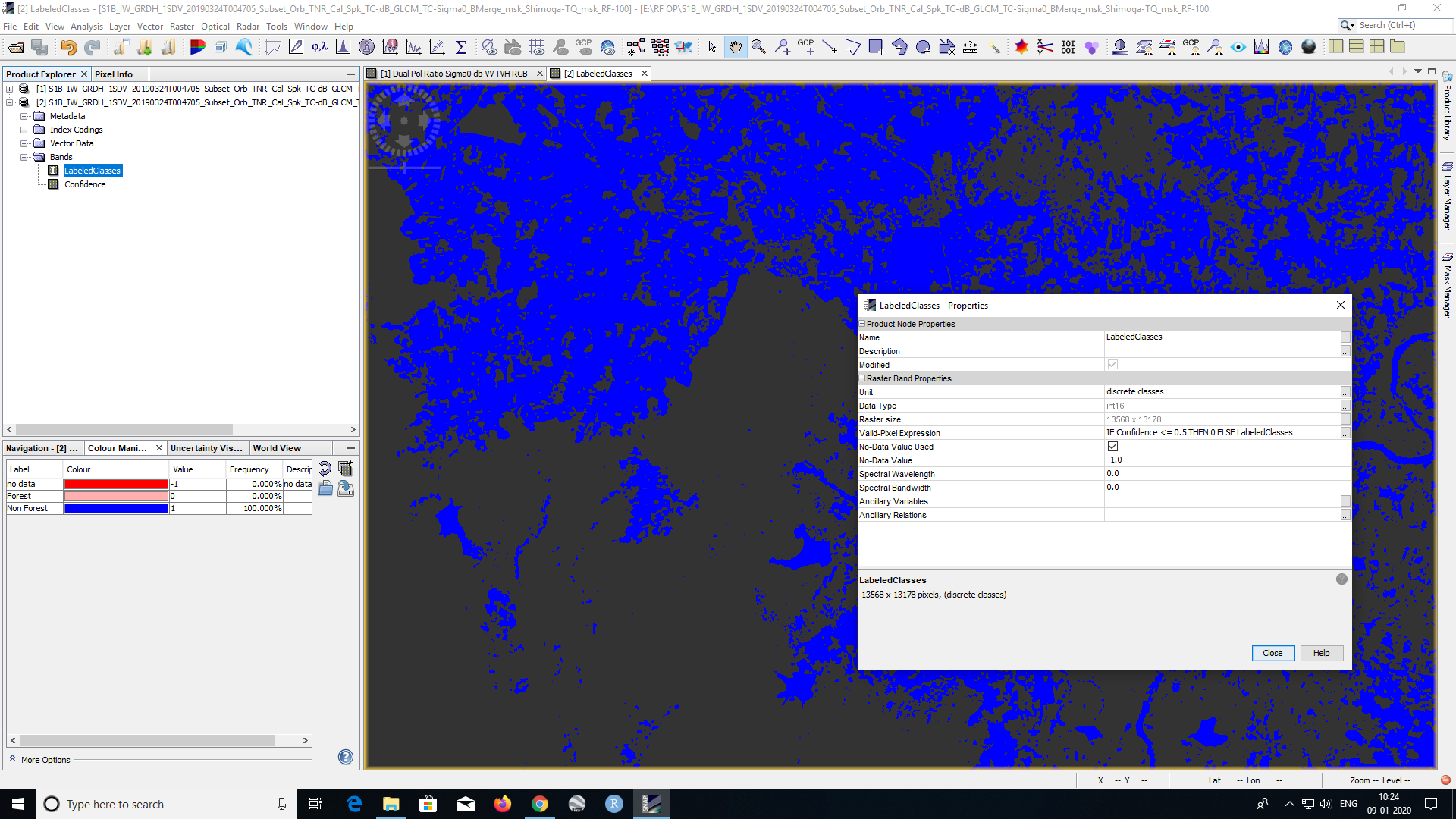
did you leave the entire expression?
IF Confidence <= 0 THEN 0 ELSE LabeledClasses
Yes @ABraun, Am I wrong?
no, you haven’t done anything wrong. In this case it just means that these pixels cannot be predicted by the random forest classifier in its current configuration.
You can try to increase the number of trees, maybe add more training areas or train more heterogeneous classes (e.g. forest1, forest2, forest3, no-forest1, no-forest2) so that every pixel can somehow be related to any of the classes. .
Thank you, sir. I will do that…
Thanks a lot for your quick response 
 .
.
Dear @ABraun, I am getting NaN pixels even after increasing the number of classes.
I have also classified with Maximum likelihood and Kmean algorithms, facing the same issue with those classifiers also.

(1st image = RGB, 2=RF, 3=ML, 4=Kmean)
Are there any particular criteria for training data collection?
Are these pixels defined as no-data in the original dataset?
Maybe you disable the nodata value of all bands in the properties, save the project, and run the classifier again.
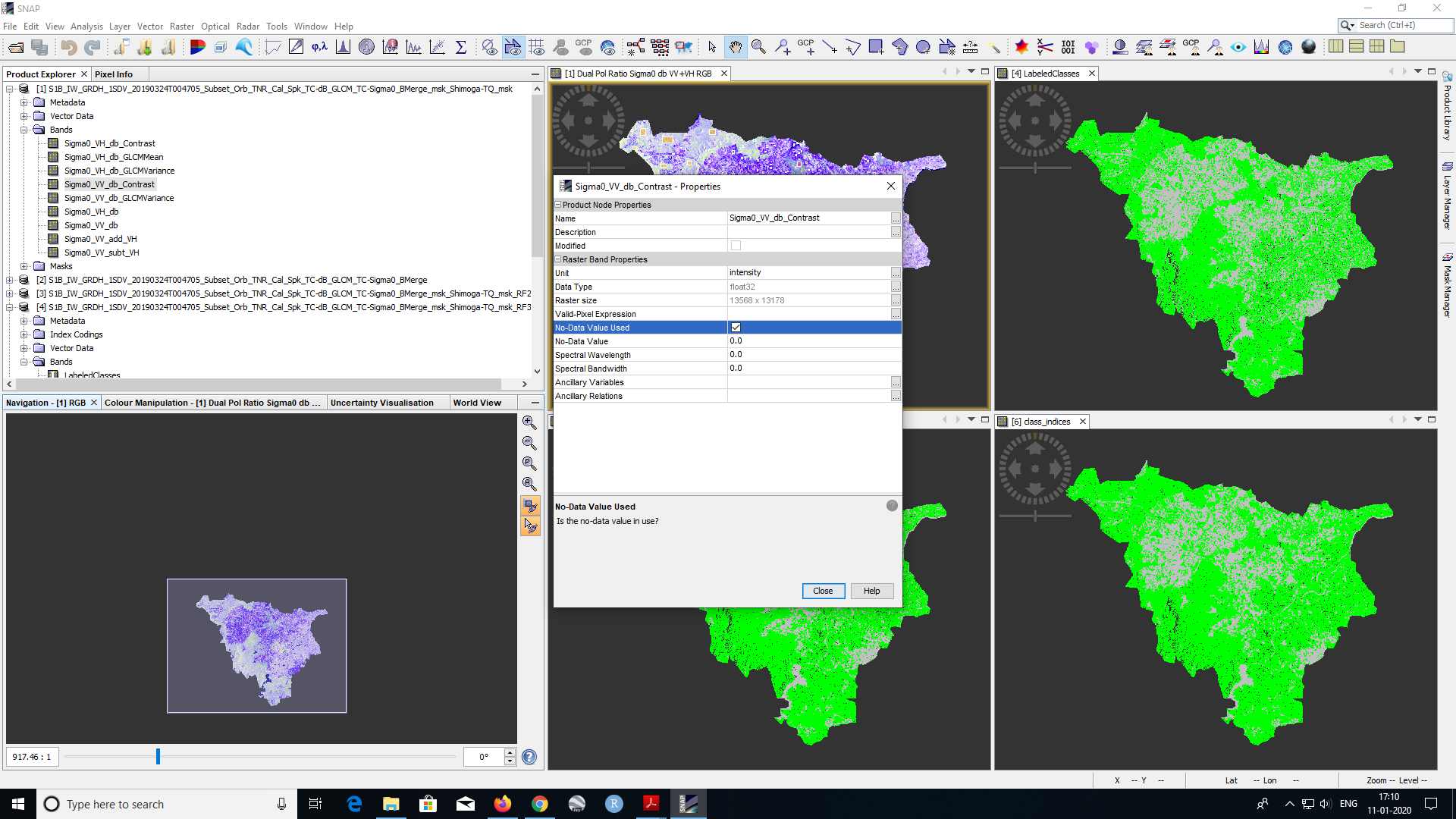
disable it in all bands and save the products.
Dear @ABraun,
I have tried that also, but no change
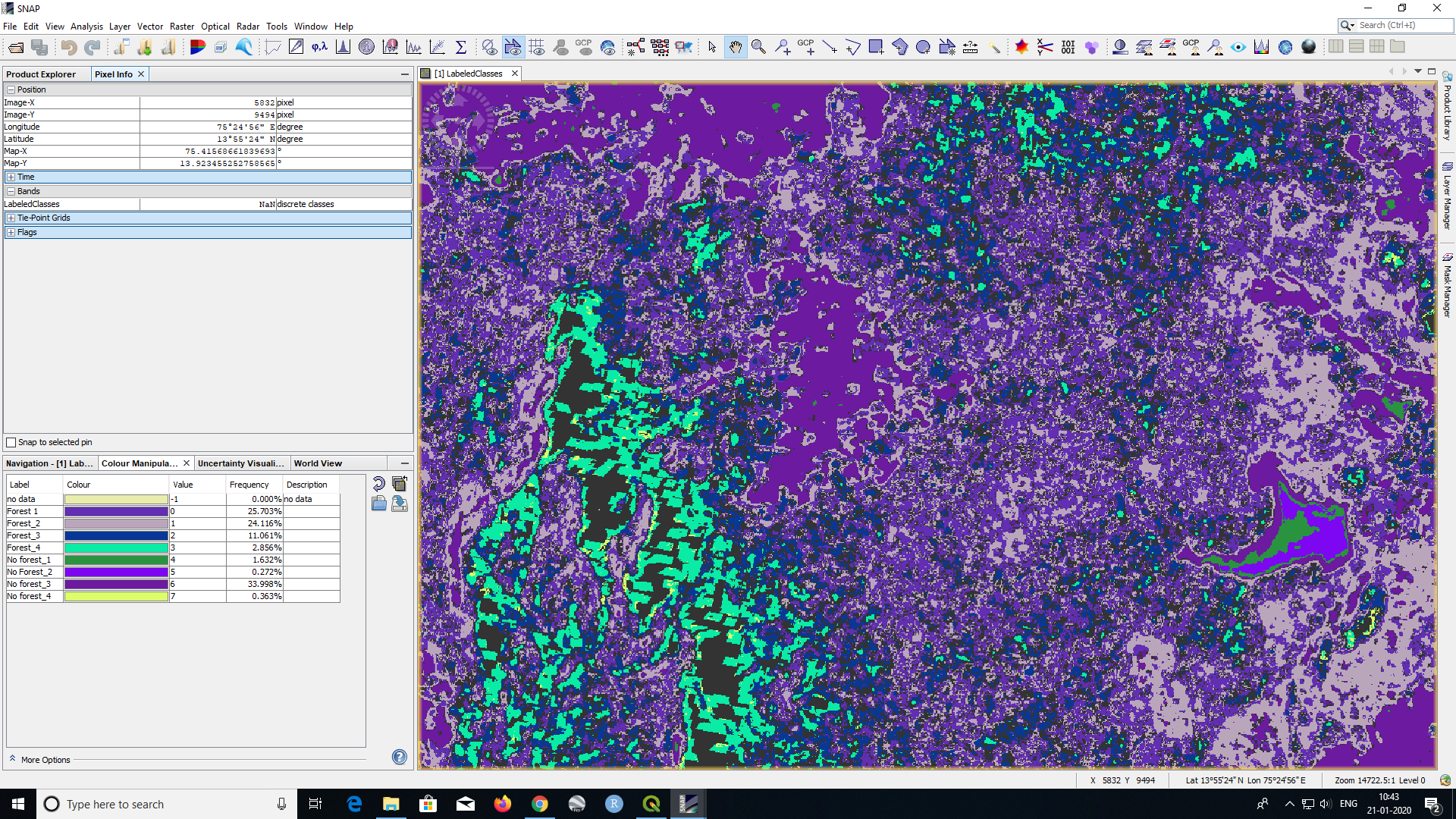
what is the value of these pixels in the original image?
Are you using image textures?
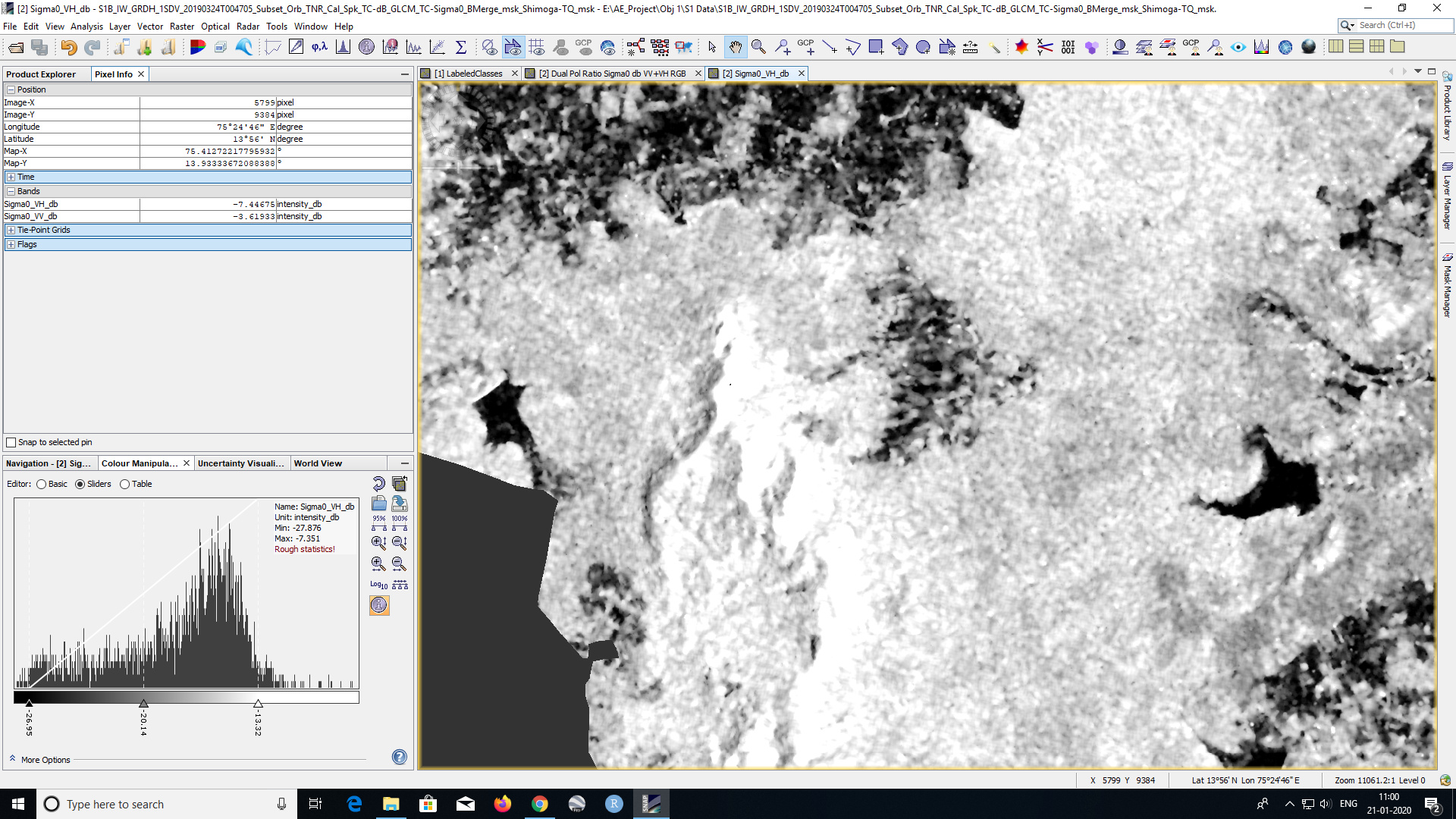
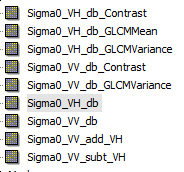
it has been reported before, that when a pixel was 0 before the calculation of textures, it can lead to NaN values in the textures as well. Please go through all input rasters and make sure that none of them has a NoData value applied in the properties. Also, make sure to save the changes (File > Save Product) afterwards. If only one raster contains a NaN pixel, the result will be blank here, as in your case.
Please also see here: