Hello,
at the moment I try to build multiple stacks of multiple SAR images. When using the GUI it is quiet easy to load Topsar Split and orbit file applied files into the Back-GeocodingOp the first one is the master image, to which all other images will be coregistered.
Doing this with snappy with two images looks something like this and it works just fine:
parameters = HashMap()
parameters.put('demName', "SRTM 3Sec")
parameters.put('demResamplingMethod', 'BICUBIC_INTERPOLATION')
parameters.put('resamplingType', 'BISINC_5_POINT_INTERPOLATION')
parameters.put('maskOutAreaWithoutElevation', True)
parameters.put('outputDerampDemodPhase', False)
mst = ProductIO.readProduct('path/to/mst.dim')
slv = ProductIO.readProduct('path/to/slv.dim')
prodset = []
prodset.append(slv)
prodset.append(mst)
prodset_bgc = GPF.createProduct('Back-Geocoding', parameters, prodset)
parameters_deb = HashMap()
parameters_deb.put('selectedPolarisations', 'VV')
prodset_bgc_dbrst = GPF.createProduct('TOPSAR-Deburst', parameters_deb, prodset_bgc)
outpath_bgc_dbrst = 'path/to/output.dim'
ProductIO.writeProduct(prodset_bgc_dbrst, outpath_bgc_dbrst, 'BEAM-DIMAP')
But now I want to add a second slave image therefore the stack will consists of 3 images mst, slv1 and slv2. I tried this, but it does not work:
...
mst = ProductIO.readProduct('path/to/mst.dim')
slv 1= ProductIO.readProduct('path/to/slv1.dim')
slv 2= ProductIO.readProduct('path/to/slv2.dim')
prodset = []
prodset.append(slv1)
prodset.append(slv2)
prodset.append(mst)
prodset_bgc = GPF.createProduct('Back-Geocoding', parameters, prodset)
...
When I run this script there are two outcomes:
- the result is a stack but just one image is stacked and I can see the Intensity when checking in the GUI (see the screenshot, for some reason you have to scroll in and it is not clickable…)
- Another “result” is snappy works for hours but does not produce anything, there is no error. In my spyder Terminal these message can be seen (bottom right in the picture)
The picture shows also the output when generated, but as you can see just one intensity band is included in the stack, beside the band name, but there is no data in it…
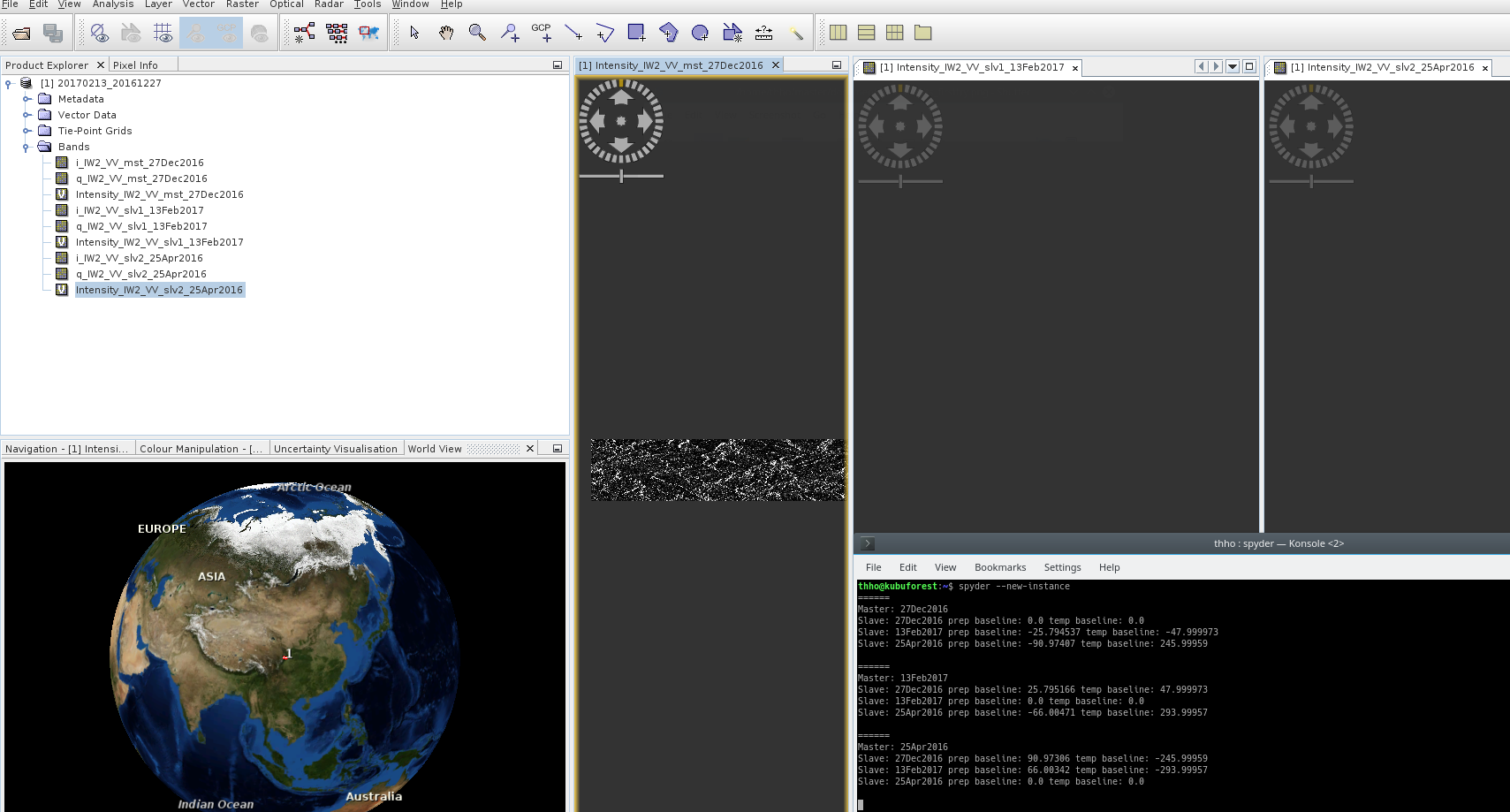
Maybe I prepare prodset in a wrong way? I tried a lot to get this run, but until now I was not able to fix this Problem. Maybe @marpet or @juanesburgo (I have in mind that you once worked with snappy and back geocoding) have an idea how to handle this? The operator works fine when using the GUI but I have to create hundreds of stacks and the loop doing this is ready if the Op works in snappy. It would be really great when I get some help here 
Cheers
Thorsten
 you have to check if all relative paths work out…your starting point is a dir of your choice which will be the projectDirectory in this workflow. Hope it helps…you can also build a for loop around that to do multiple stacks (that is what I have done)
you have to check if all relative paths work out…your starting point is a dir of your choice which will be the projectDirectory in this workflow. Hope it helps…you can also build a for loop around that to do multiple stacks (that is what I have done)