I want to create some new processors to be integrated into snap. Preferably I would like to use Java in order to make sure all dependencies are met, since as I read in the python guide: “* ensure same Python configuration (used libraries) on the user system as the developer uses”, which is something quite hard to obtain. Is this statement true?
I found information about how to integrate a new processor in confluence.
However, I have several doubts:
The example in github referenced in the documentation here does not have anything in common with the documentation. It does not implemente computeTile or computeTileStack methods. Is there an up to date version or am I missing something? I have found some useful code in the s1tbx code like here
The steps to integrate a processor are explained, however I do not see how to finally make it available in my snap installation after I finally create it. I mean, I guess I will need to take the .jar and place it somewhere. Am I right?
In the perfect scenario, I would also like to debug my code while I implement it. I see two options for this:
Develop the processor disconnected from the snap desktop and just test and debug the application writting my own unit tests. In this case, how can I extract the tiles from a Product to pass them to my Operator methods?
Directly build the sources of snap and launch in my IDE the whole desktop app
Run in “debug” mode my Operator inside snap desktop in some sort of esoteric way. Is this possible?
Thanks in advance, and in case you have any other reference to documentation or code… I would really appreciate it
To integrate you processor, when you build it using maven you can generate a nbm file that then you can install as a plugin in SNAP via Menu->Tools->Plugin
Very useful.
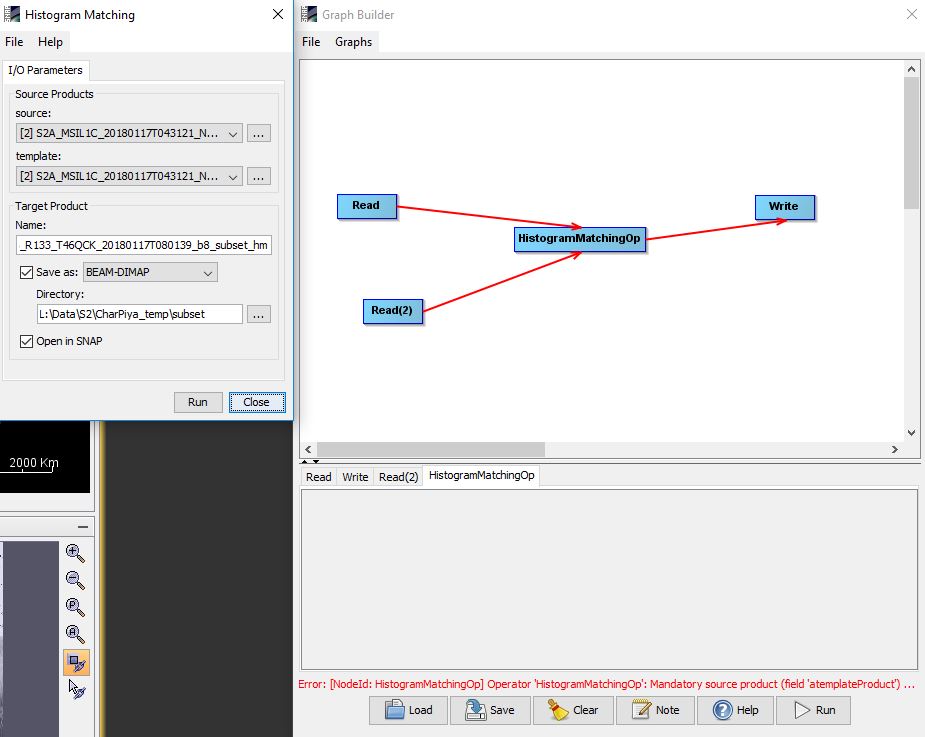
I managed to create some operators that work well when triggering them through the Action Menus. However, when I try to use the operators within a graph, they seem not to read properly the input/output parameters. See the attachment.
That’s very likely an issue in the Graph Builder. Using two specific source products seens not to work.
In this case you need to create the XML graph manually and run it from the command line.
Btw., great job. Nice that you have manged to develop the operators.
@lveci, @obarrilero That’s what I was referring to in the TC yesterday.
I 'll take a look at the github repo to see if I can contribute somehow to fix some of the issues (like this one), although the codebase seems a bit too overwhelming for now.