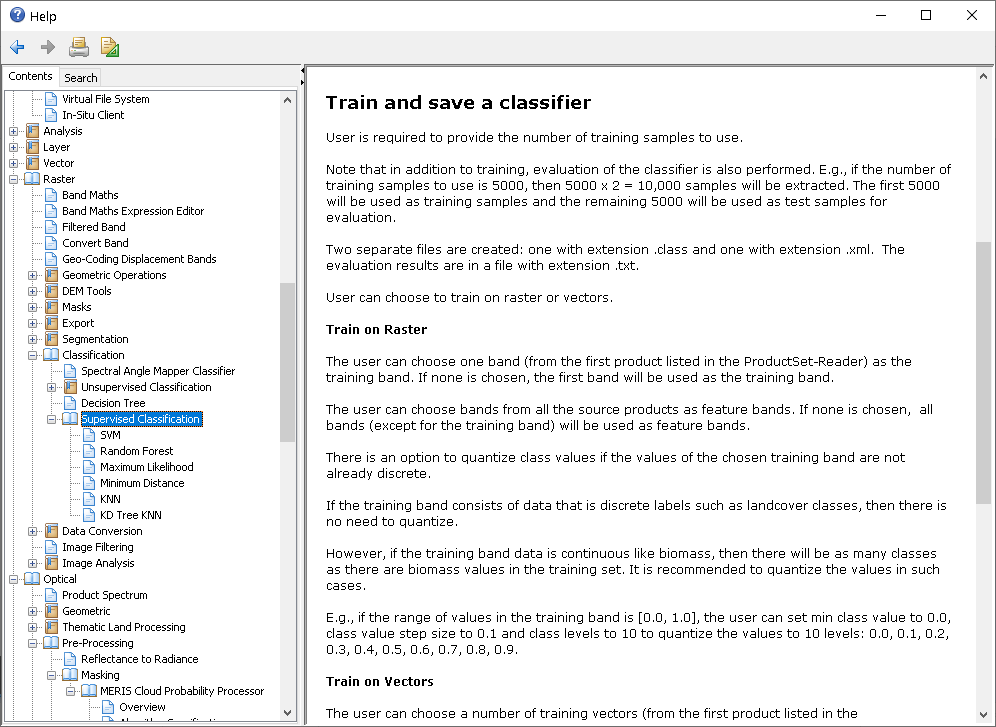
I have red all post concerning the issue but I can’t find the answer. in file generated by option “Evaluate classifier” we have “Total samples = 10000” ot less
for classification process default is: 5000
So 5000 is for training and 5000 others for validation? if possible so if there are enough amount of the pixels?
An it is randomly taken in each approach.
Am I right?
thanks in advance
Beata
Hello,
I am just working on the classification accuracy in few software: SNAP, QGIS ENVI, directly in Python, preparing comparative paper. I still have some questions. I know that SNAP selects randomly as many piksels as we define (if possible).
- is the selection really random? My training polygons are farmers’ declarations (agriculture parcels), so not homogeneous at all. Repetitions of classification using maximum likehood give very similar results (also accuracy parameters almost identical, BTW “Using Testing dataset, % correct predictions” = overall accuracy in “conventional” accuracy analysis in other remote sensing softwares),
- using random forest in SNAP - results are much more different (also accuracy parameters). The difference is due to the difference in the algorithms, not due selecting other pixels. Am I right?
- is it correct if we call maximum likehood algorithm machine learning as random forest, k-means, k-NN SVM? In my opinion maximum likehood, minimum distance etc. are pattern recognition.
Thanks in advance.
Random Forest delivers differnet results on the same input data because of the randomized selection of training samples (pixels) and explanatory features (raster bands). You can increase the number of trees to reduce this variation at the cost of longer processing.
I would say SVM and RF belong to machine learning while maximum likelihood or minimum distance belong to estimation theory.
Thanks a lot!