I was able to parse the XML files from the annotations directory to extract the platform heading.
Is it possible to do so with the snappy python api?
Data: Sentinel-1
Aim: ensure downloaded data to be processed is of a particular heading.
What I did so far: use the XML python module to parse and extract the heading from the annotations XML.
Thank you for the hint: Did you create this as a new user or was your query simply copied by another person? Both is not appreciated according to the board rules.
Then this information is not read and not put into the data model.
Or is it may be in the Original_Product_Metadata path and not in the Abstracted_Metadata?
Yes but I am batch processing data and need to extract it programatically. So as a reminder I mentioned having parsed the xml to extract it however I wanted to know if it can be done with snappy like in the elements found in the abstracted metadata.
Yes, you can do it with snappy. You just need to replace the element names in the above-linked thread.
Your python code would look like:
annotationElem = product.getMetadataRoot().getElement('Original_Product_Metadata').getElement('annotation')
elems = annotationElem.getElements()
# iterate ove elements for the one you need
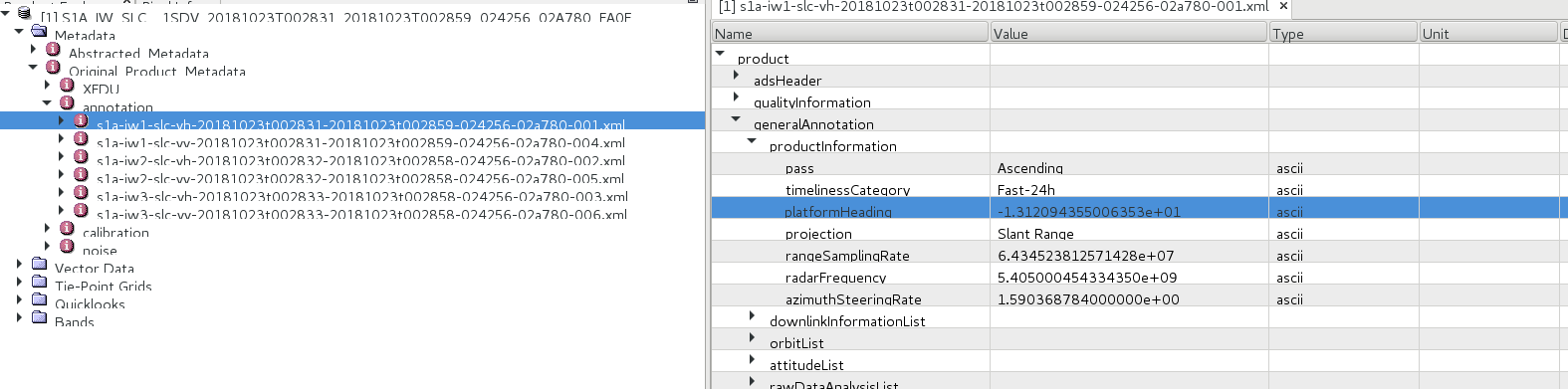
generalInfoElem = origAnnotationElem.getElement('product').getElement('generalAnnotation').getElement('productInformation')
heading = generalInfElem.getAttributeString('platformHeading')
#parse the string
Hello, everyone. I intend to use the platform heading angle in the GPS LOS projected formula, extracted from the original metadata of my Sentinel-1 images. The value obtained is approximately -6.1 degrees. Should I use it as -6.1 degrees in the formula?