Hello,
I’ve got a question regarding processing using GPT.
I’m planning to process some 560 S1 scenes for flood detection purposes. I’ve figured the easiest way would be applying a pre-built graph with the processing operators on the S1 scenes.
I’ve already successfully managed to process multiple scenes with the following graph:

Soon I realized that the resulting data-volume will be too much to handle, so I decided to add the Convert-Datatype operator in order to convert the processed scenes to Int16.
The graph looks as follows:
So that’s where things get interesting for me. I’m working on a Win7 64bit machine with 128 GB Ram and 6 Cores @ 3.50 GHz.
Processing the 1st graph for a small (~450 MB) S1 scene takes about 1 Minute and 10 seconds. When I manually apply the Convert-Datatype operator to the processed result, it takes another 15 secs or so to be done.
However, when I’m applying the second graph which should do everything in one single step, the processing takes 7 minutes and more.
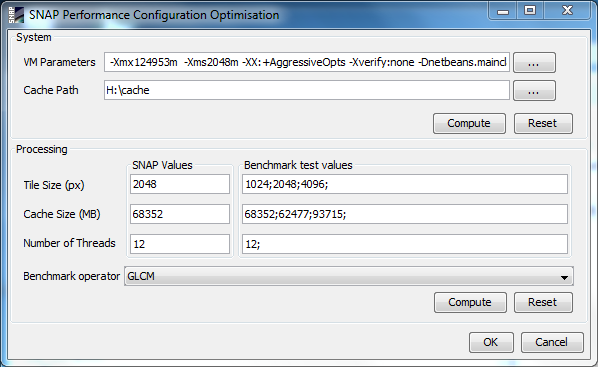
I read the threads here about GPT performance and java heap size etc. (especially Gpt performance) and I’ve consequently tried everything to modify the parameters correctly.
Additionally I’ve noticed another thing while processing the two graphs:
For the first graph, the processing seems to run using the full amount of available power, as all the threads are maxed at 100%.
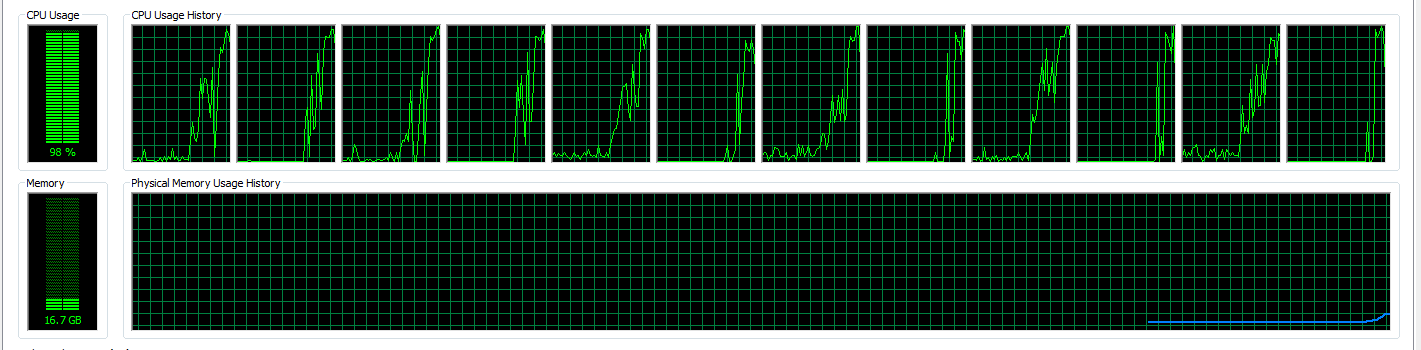
For the second graph (the one that includes Convert-Datatype), the CPU Usage looks more erratic and doesn’t really show full load.
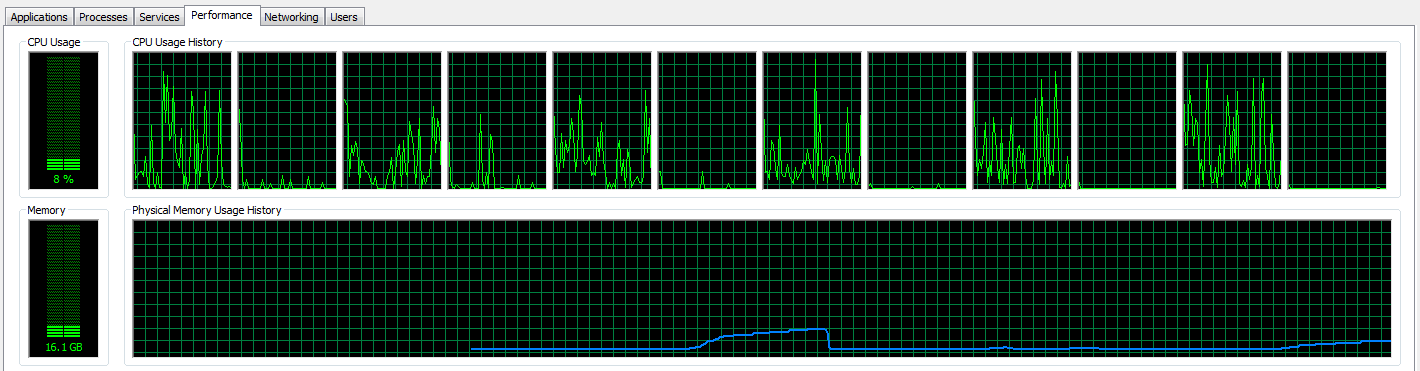
I’m grateful for any hints on what could be going wrong or how I could streamline the processing. Also, I’m happy to hear any feedback and enhancements on my processing graph for flood detection.
Many thanks,
Val