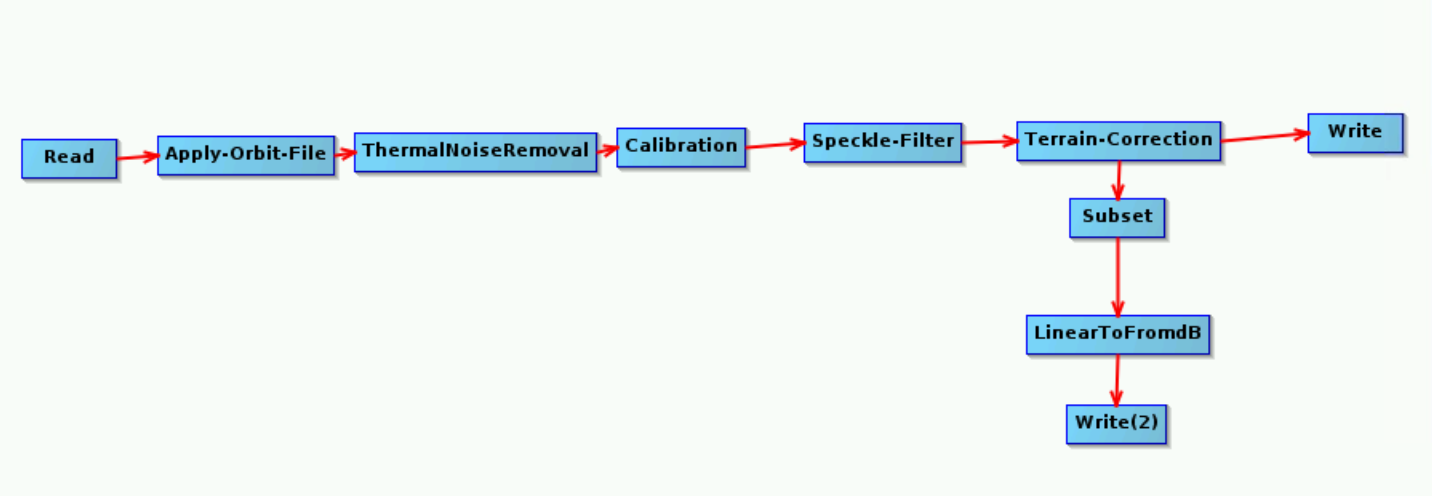
I am trying to process a simple graph calculating backscatter from GRD and then subsetting that I created using the Graph Builder from the terminal, I get a JRE out of memory error. gpt maximum memory usage is set to 10 GB.
Interestingly enough, the gpt command still seems to generate and save reasonable results (tested on two S-1 datasets).
Wanting to use this graph in batch processing, the command crashing is however not an option, in addition to the fact that I can’t really be sure about if the results generated are correct.
Can this be a problem caused by the way I set up the graph? Or is it really a system issue?
P.S.: I also tried to perform the subset operation and the conversion to dB after the first Write, but that does not seem to make a difference to the operation crashing.
(Using SNAP 7.0 on a Linux machine with 16 GB RAM)
How much memory does the system have? Linux has many tools that allow you to monitor memory usage while a job is running but modern systems are so fast that it can sometimes be hard to get data. I do ocean colour processing where it is possible to do the subset operation early in the chain, which reduces memory and time requirements for the remaining steps. You can try breaking up the graph into a bunch of simple operations to see which operation is giving the error.
Thank you for your idea!
The total RAM available is 16 GB and I seem to be exceeding memory usage running this graph (used top to monitor memory usage) even when I don’t run anything else. From previous test runs it really seems like it’s the Subset operator that is causing the error in my context, not sure why though.
I am not sure if I would loose data quality performing the Subset operation before applying the corrections, but it has been used as late in the examples I’ve seen so far.
Update: Performing the subset operation earlier in the graph does not seem to make a difference to the fact that I am running out of memory. I also tried running gpt with the -x option to save memory but it does not seem to make a real difference.
Have you tried saving the subset data and then processing it with a new graph? The reason this could make a difference is that Java can postpone operations until the result is actually used, so if everything is done in one graph Java may be carrying full-sized data past the subset node.
Thank you, this is actually what I’m currently trying. I did not know about the way Java is handling these processes, so thank you for providing the background!