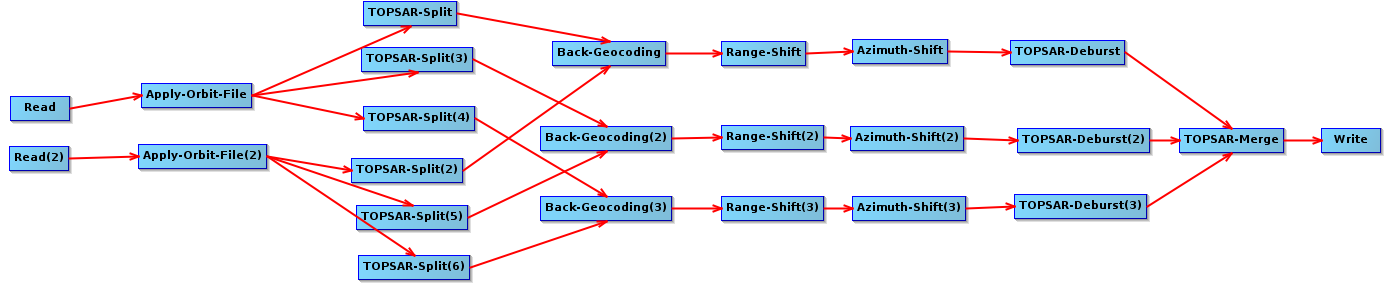
I’ve been testing gpt with large graphs that coregister a pair of Sentinel-1 SLCs. Regardless of the input images, gpt seems to run into an infinite loop. This is the command I use:
My current workaround is to split the graph in two smaller ones, thus having to save intermediate results. I’ve attached the graph’s xml and a screenshot.
It depends what’s in the graph but, usually the more operators in a
graph, the more memory it will need. If it runs out of tile cache, some
tiles may get triggered to be recalculated.
Thanks for your prompt reply. Do you mean that if the cache is too small, then gpt will run indefinitely? If so, what cache size would you recommend? I was hoping to use gpt to get a coregistered pair in one go.
Note that I’ve attached the graph’s xml in my original post. So, that’s what’s in the problematic graph.
You have a lot of memory available so make sure your JVM heap size is big and tile cache size is big.
The problem in the graph may be caused by range and azimuth operators which are currently not very efficient when they are in the same graph due to how they request data.
Using azimuth-shift and range-shift in the same graph makes it very inefficient. It’s better to split the graph into two and run them sequentially. I’d be interested in hearing how much this improves performance.