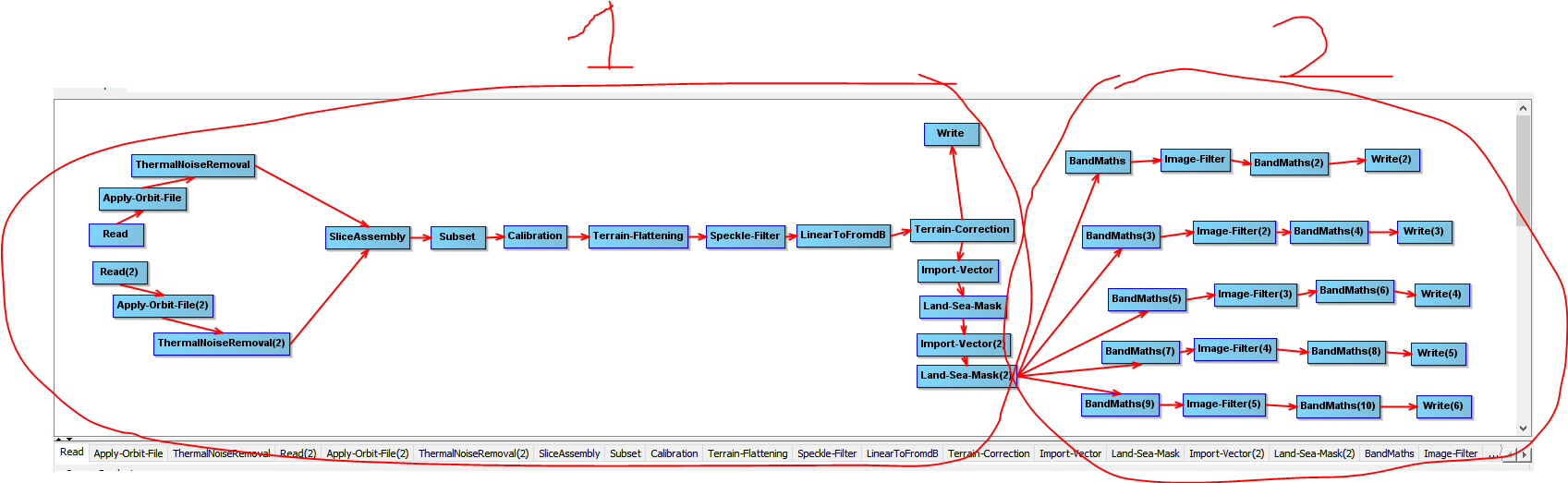
If I process it in two different steps, graph 1 takes about 5 minutes, graph 2 a few seconds. When I assemble 1 and 2 , the processing takes around one hour (a time variable between 45 minutes and 90 minutes…I don’t understand what this variability is due to).
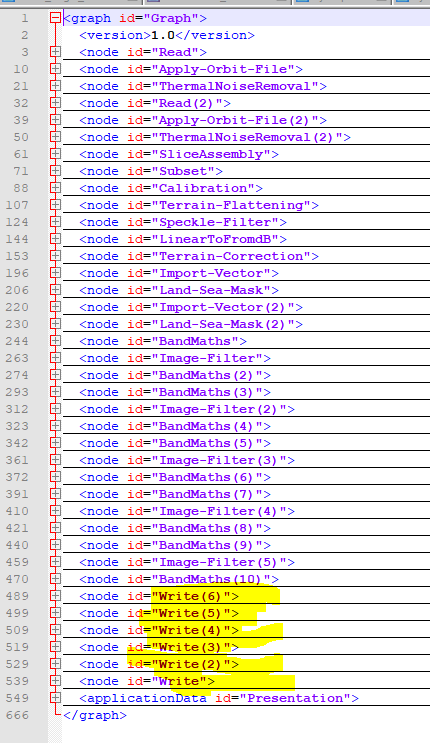
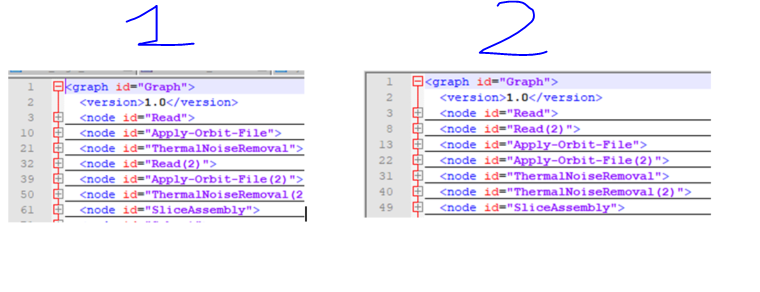
Do you think there is an error in the order which operator are write in the .xml?
When SNAP writes a product it can release the memory which was used in the graph for all the intermediate steps required until this step.
As longer as the graph gets, the more memory is required to store these files in the RAM which makes it successively slower. I would really recommend to split the processing chain into these two parts.
There are some tweaks in case you have a high performance PC (64 GB or more), but these settings are not effective for 16 GB (your Xmmx value is already 12 GB, which is the recommended amount).
It looks like you have already found a highly efficient of splitting a “monster” graph in two. Accessing multiple files on the disk always slows things down and adding more operators to a graph is going to consume more memory.
Thank you very much Mr. @ABraun and Mr. @mengdahl.
So can you confirm that the order in which the operators are written in the .xml file [I’m not talking about the way the graph structure is displayed on the GraphBuiler (first image above)] has no significant impact on processing timing?
Sorry Mr @ABraun, I uploaded the wrong picture (the third one).I was referring to the order in which the operators are written on the xml file (third pic) which, i guess, depends on the order in which the operators are added on the GB.
E.g.