I have several quad-pol images which I would like to classify by H-alpha Wishart segmentation and analyse the scattering properties of several features (covered by mask) based on H-alpha plane.
For that, I performed unsupervised H-alpha Wishart Quad classification, after Terrain Correction I’ve added mask of my features and generated histogram for my mask. The classes in a mask are: 2,4,5,6,7,8.
Parameters of the classification: 5 window size, 100 iterations (based on my experience the more iterations the more accurate results but please, correct me if that’s not the case here).
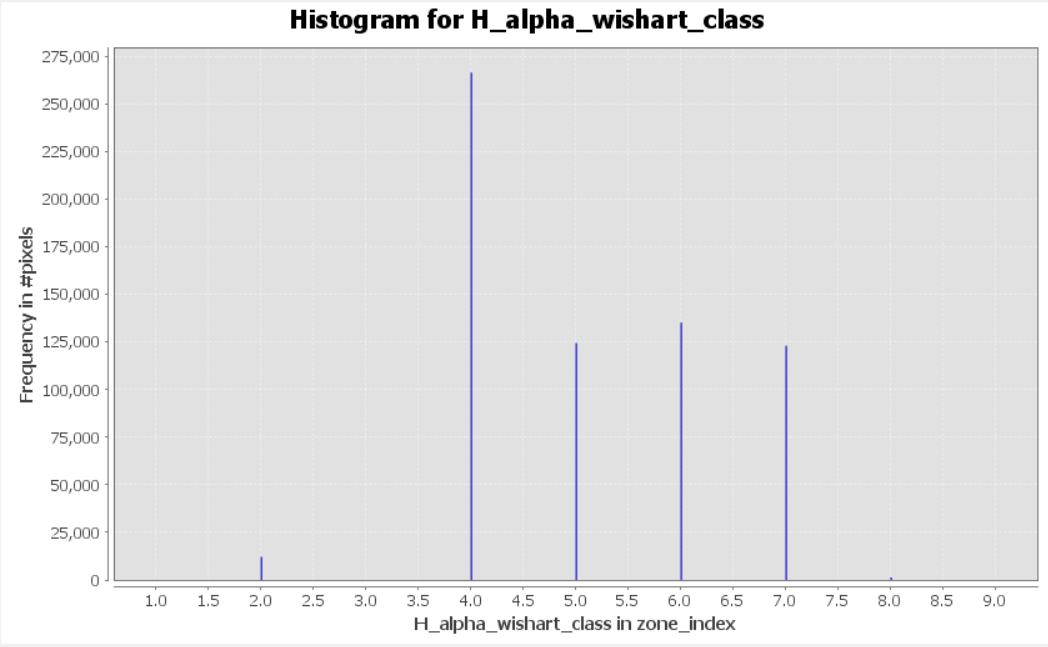
In addition, I’ve performed H-A-alpha Decomposition. I’ve generated the H-alpha plane for my mask. The classes which contain pixels of my mask are: 3, 4, 5, 6, 7, 8 (below).
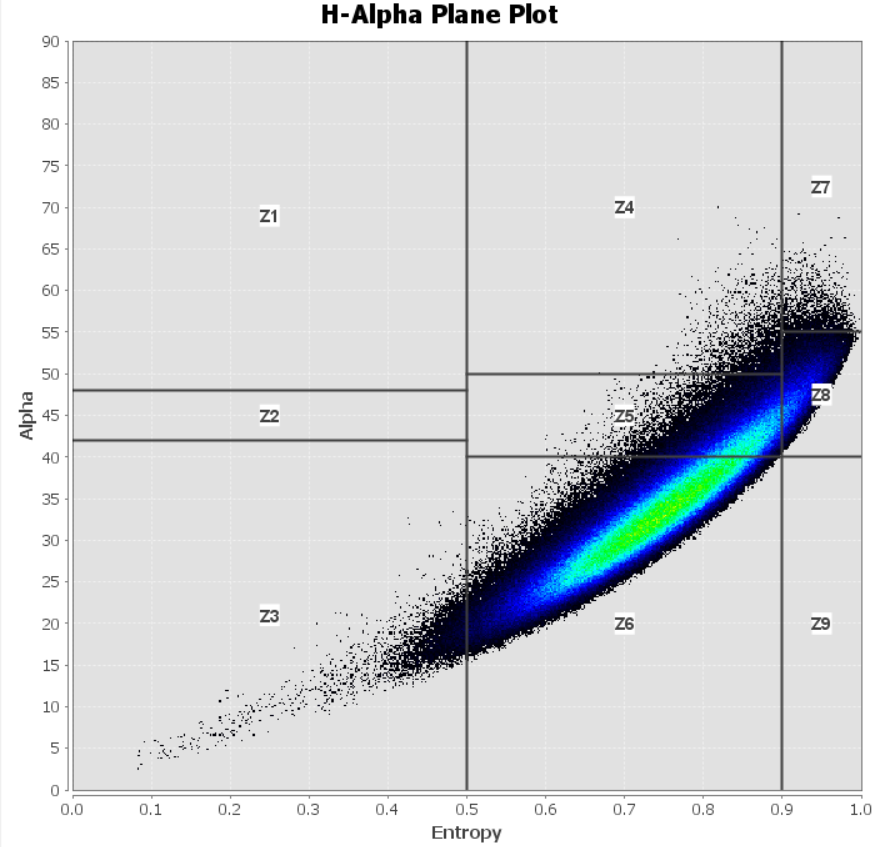
The density of H-alpha plane shows that class 6 should be the most frequent in a mask. However, the histogram shows that the most frequent is class 4 of H-a Wishart segmentation. The representation of other classes is also inconsistent when H-alpha plane and results of H-a Wishart classification are compared. Why such big inconsistency?
EDIT: I have also generated H-alpha Wishart classification for default parameters, i.e. 5 window size, 3 iterations. Here is a histogram for the same mask as above:
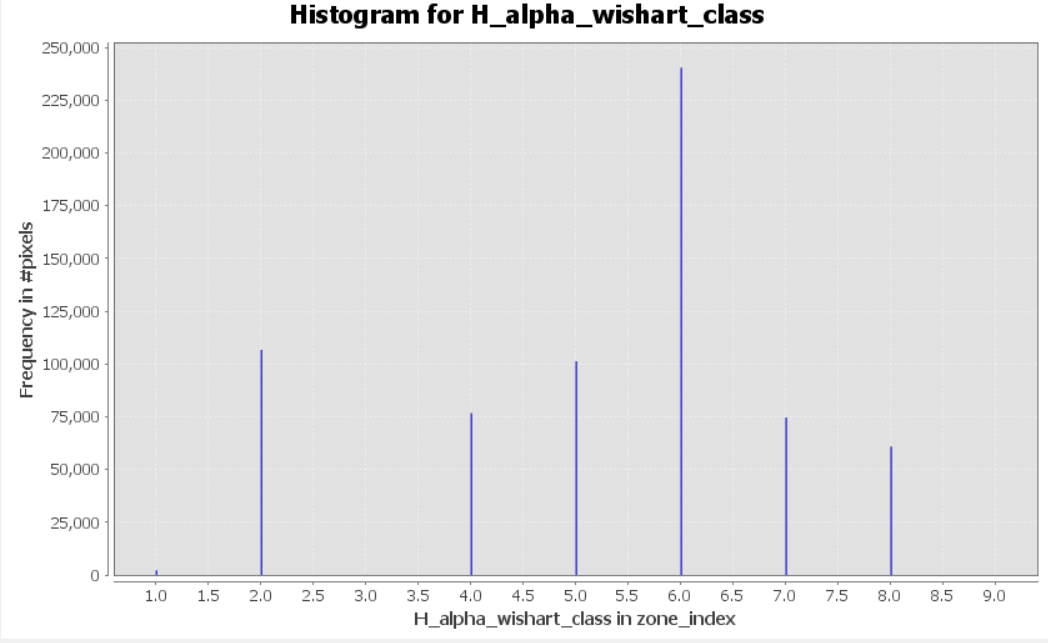
Indeed, class nr 6 is the most frequent (as on H-alpha plane) but there is also quite frequent class nr 2 (not represented by H-alpha plane at all!). There is no representation of class nr 3 (present on H-alpha plane).
Again: could you please explain me why this inconsistency?
(I suspect that there is misclassification of class 3 as class 2 in H-alpha Wishart classification process…)
How many iterations should be used for H-alpha Wishart classification? Just by comparing the histograms, there is a big difference between the results of 100 iterations and 3 iterations (not to mention the differences in comparison to H-alpha plane…). As I wrote before, I was taught the more iterations the better… I don’t really care about the computation time (dependent on iteration number) as long as I get correct results.