I resampled one S2 product, but I don’t see resampled images in my …\AppData\Local\Temp\… directory.
I know that data is cached by the S2 reader in the directory <USER_HOME>.snap\var\cache\s2tbx\l1c-reader. This could fill up your disk and the handling of this cache needs to be improved. There are already issues for this in our bug tracker (SIITBX-277, SIITBX-288).
In SNAP Desktop it is possible to change the interval how often the cache is deleted (Tools / Options / S2TBX). But this will probably not help you.
This cached data can be cleaned by a function call. I guess the following will work.
from snappy import jpy
S2CacheUtils = jpy.get_type('org.esa.s2tbx.dataio.cache.S2CacheUtils')
S2CacheUtils.deleteCache()
If you call deleteCache() after every processed product you should get rid of this problem. If the reader-cache is the problem and not something else. Probably it would be good if you first call on the source product dispose().
After a few days short break I’ve come back and start dealing again with the issue.
What I figure out was that by reading the *.zip file corresponding to the S2 imagery, the readProduct function was creating data in the folder …\AppData\Local\Temp\snap-user and that data was not removed. The dispose() method called on the product obtained by using readProduct did the trick and now the hard drive is free of unwanted data. The code is looking something like this:
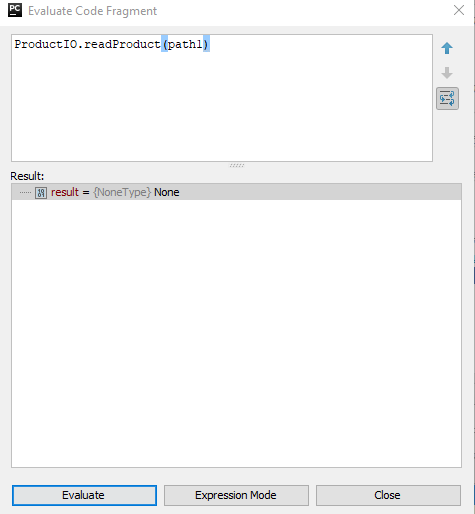
snappy give me none output either i give zip file or unzip file. checked in two sentinel images. Instead when i open the manifest.safe in snap software it show result…
This happens either when no reader is found or when the file name is invalid. It is weird when you can open the file in SNAP Desktop, though. Can you tell me the value of ‘path1’?
Perhaps could it be a typo in the path? Normally it should be
‘D:\SENTINEL\S1A_IW_GRDH_1SDV_20181008T131251_20181008T131316_024045_02A0A4_4743.SAFE\manifest.safe’
When you unzip it, the product folder should be [yourProductName].SAFE and if you are opening it compressed, then the path should be:
‘D:\SENTINEL\S1A_IW_GRDH_1SDV_20181008T131251_20181008T131316_024045_02A0A4_4743.zip’
@marpet@ABraun
Hie,
In the example provided snappy_flh.py I am getting an error:
w1 = b1.getSpectralWavelength()
AttributeError: ‘NoneType’ object has no attribute ‘getSpectralWavelength’
How can it be corrected?
Thanks
Hi @ABraun thanks for your reply. Can you please correct me am I on the right track to preprocess Sentinel-1 SLC data to reach the goal of change detection.
add orbit file
remove border noise
remove thermal noise
Calibrate image to sigma0 and dB
TOPSAR Deburst
multilook
subset to study area
terrain correction
radiometric correction
speckle noise filter
geocode/reprojection.
Please recommend what steps I have to follow. I tried TOPSAR-Split using SNAP instead of Python, but its also creating very big file as output.
Border Noise removal is not required for SLC products
I would apply a speckle filter earlier (before the conversion to db and multi-looking)
Multi-looking is not mandatory. After range doppler terrain correction your pixels are converted to squares anyhow.
The conversion to dB only makes sense if you search for changes in the low backscatter areas. The information is kind of the same but low values get streched while high values are shifted towards the mean. Your histogram then shows a more normal distribution.
Hi, As per your recommendation, after trying TOPSAR-Split function, I have run all the required processes successfully.
One thing I would like to confirm here. As you said border noise removal is not necessary. For testing purpose, I tried to remove border noise but function was not detecting the selected bursts product as correct one. is it because of applying TOPSAR-split function and selecting few bursts or reason is something else?