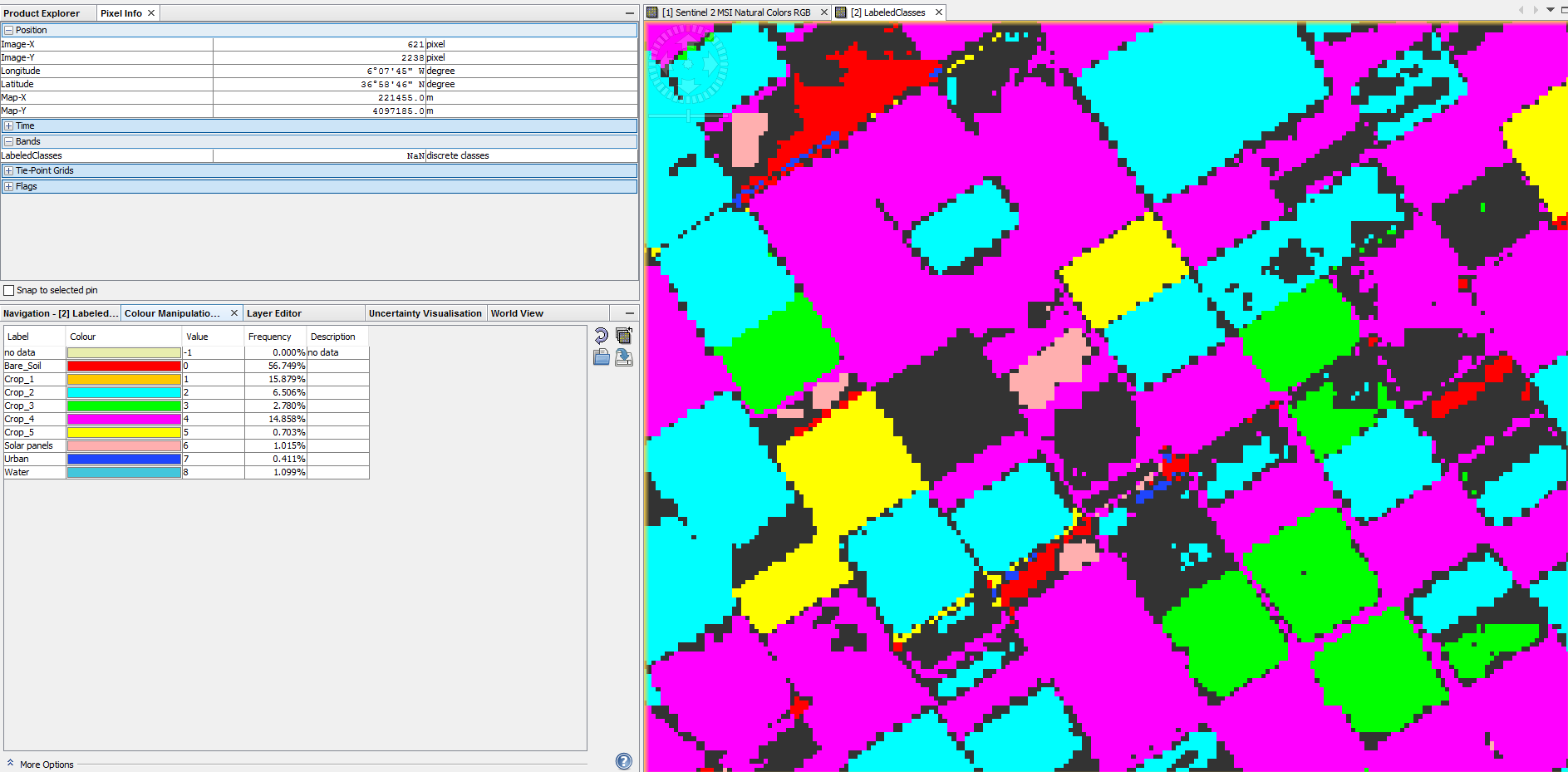
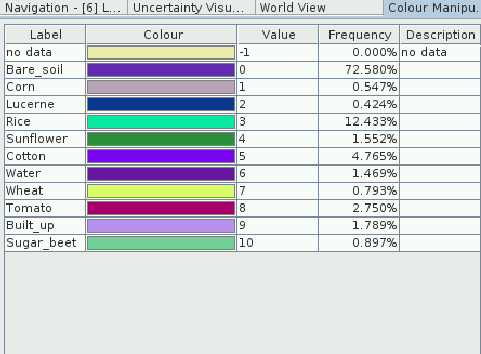
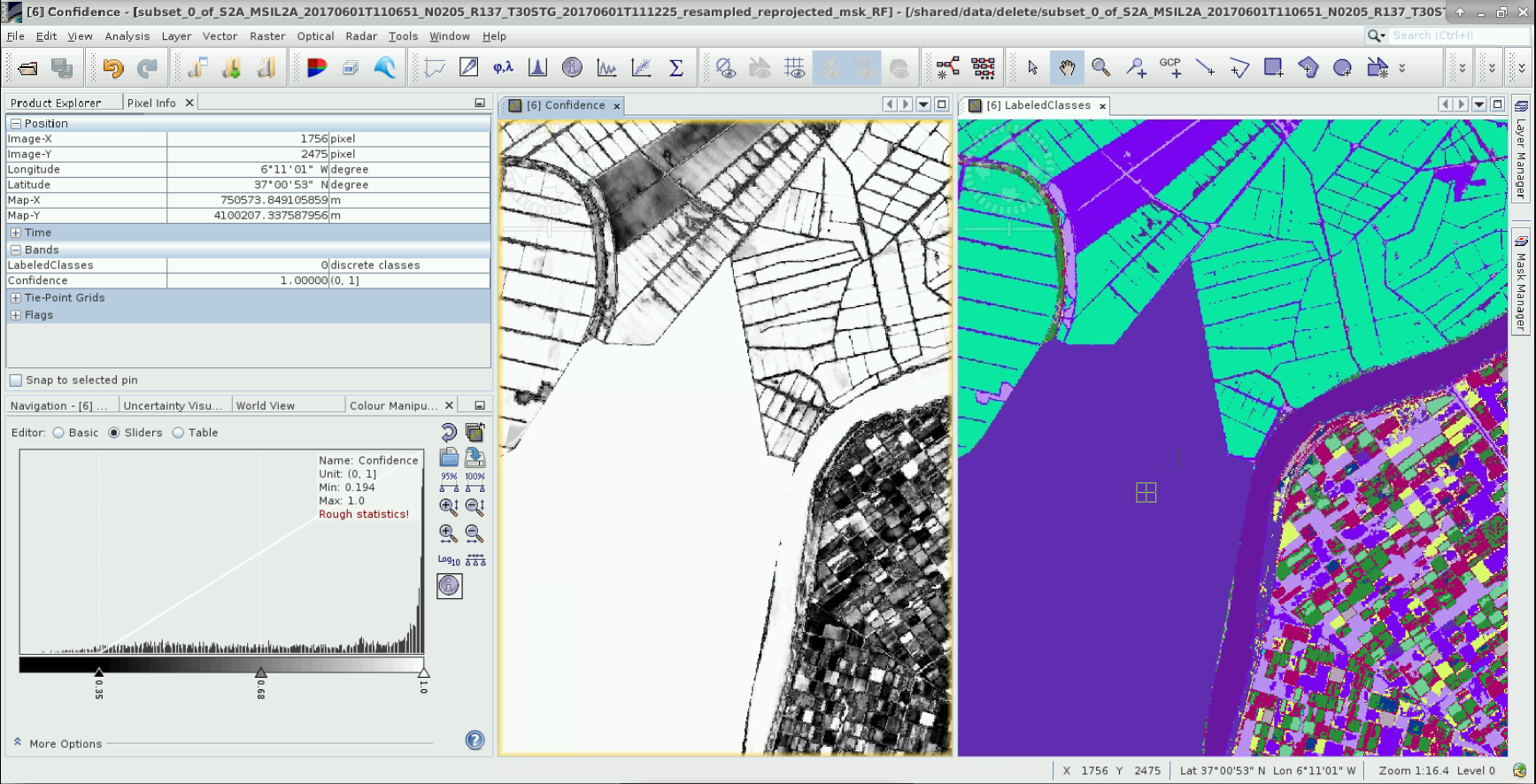
I am running a RF classification using multi-temporal S2 level 1C images (not processed to 2A yet). The classification looks good but some of the pixels are classified as NaN. Here are my steps:
-Resample (to 10 m)
-Subset (reduce size of images)
-Import Vector (shapefile of the study area)
-Reproject (to the same UTM zone of the original product. Necessary for the next step to work properly. No data is set to -1 and not NaN)
-Land-Sea mask to mask the images with the exact shape of the study area
-Import training vectors
-Run RF classification
This is an example of the images that are used as input for the RF. The black area around the study area has NaN values. They grey area is just invalid pos.
the NaN pixels fall below the confidence threshold of the RF algorithm meaning that the signature cannot be assigned to a class above the desired confidence.
At the moment you can only increase the confidence threshold in the layer properties but nontheless these areas are zero. Would be a nice improvement of the RF module to have more influence on parameters like confidence or number of samples per node ect.
Thanks for the clarification. Although RF does not have a lot of parameters, it would be nice to have more control. I guess my problem was related to this topic. I post the link for new readers.
Hi,
I have run a RF classification over an image that was subset and masked before. The input image has the shape of the Study Area and the remaining pixels are NoData. When I run the classification, the NoData pixels are taken into consideration and classifed.
The confidence level of the NaN is 1 so I cannot play with the threshold. If the NaN cannot be classified according to the RF algorithm, why do they have a class (they are classified as bere soil). The statistics of the output are affected and there is a dedicated class (-1) for no data.
Does this bug with classes getting mixed up happen consistently in a predictable manner or just randomly? Could anyone provide more details? Does it happen in SNAP v6 preview 5?
@ABraun, in SNAP, when creating the trees for the forest, do you know which is the number of variables that is randomly selected to be used as splitting options at each node of a tree? Is it the square root of the number of variables?
I have seen on literature that this parameter does not affect a lot RF but still should be possible to be defined by the user. I could not find any reference about that on SNAP
Hello everyone,
I am facing a further issue with the arbitrary threshold for NaN set by the Random Forest tool.
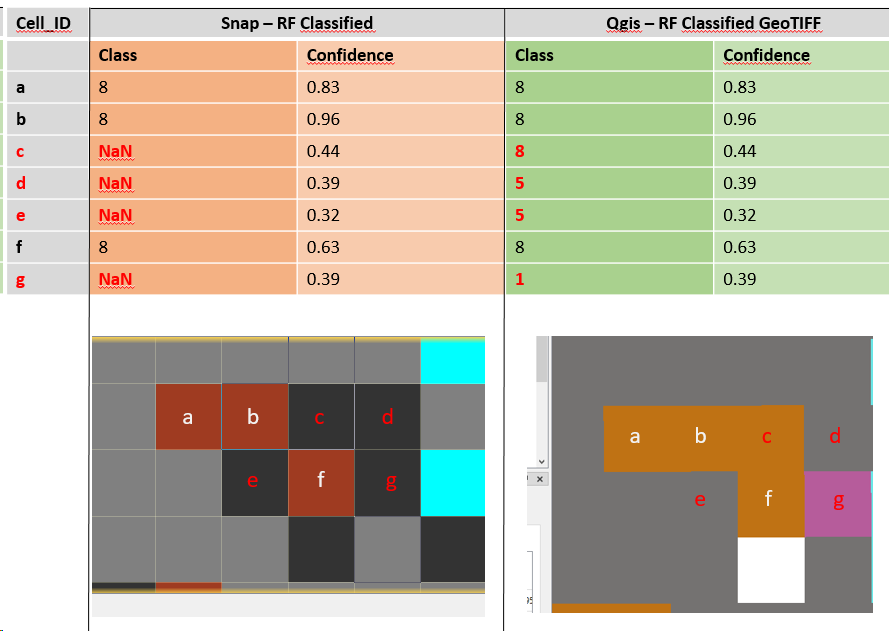
When saving my product as GeoTiff to perform an accuracy assessment in QGis (since no tool is available in Snap, Accuracy Assessment in SNAP) or other environments, my NaN pixels are automatically assigned to different classes, thus altering the results of my original classification: in the picture below I prepared a quick table to illustrate the issue (the pixels are named with letters to help visualizing the correspondence and the mismatch between the two products):
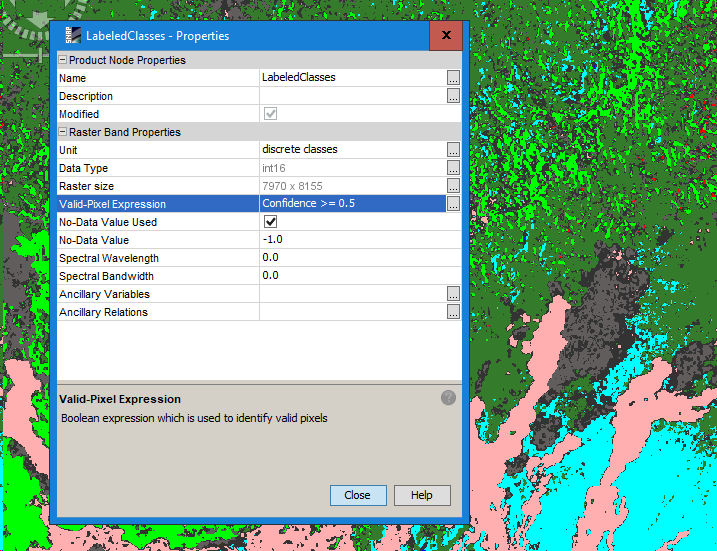
the classes are not randomly assigned, but treated as NoData within SNAP because they fall under the confidence criterion defined in the properties of the LabeledClasses raster.
In the image below, all classified pixels with confidence below 0.5 are treated as NoData, although they might contain assigned class values.
But only SNAP can handle this valid pixel expression. If you want to export the data, make a new raster in the band maths which substitutes these values by 0, for example:
IF Confidence <= 0.5 THEN 0 ELSE LabeledClasses
This creates a raster where these areas are set to 0 (you can use any other value as well)
Make sure to remove the “virtual” checkbox in the band maths and save your product to make the new raster permanent.
Thank you a lot! This clarifies everything: so, it’s possible to simply modify the valid-pixel expression from the LabeledClasses properties in order to show the classification results with a different threshold.