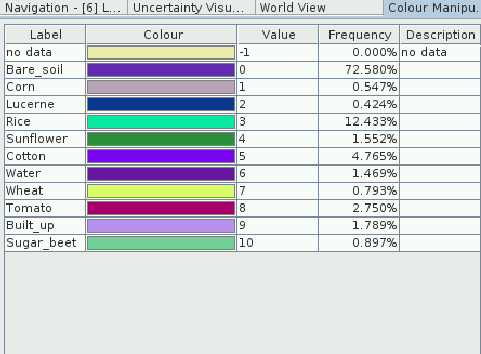
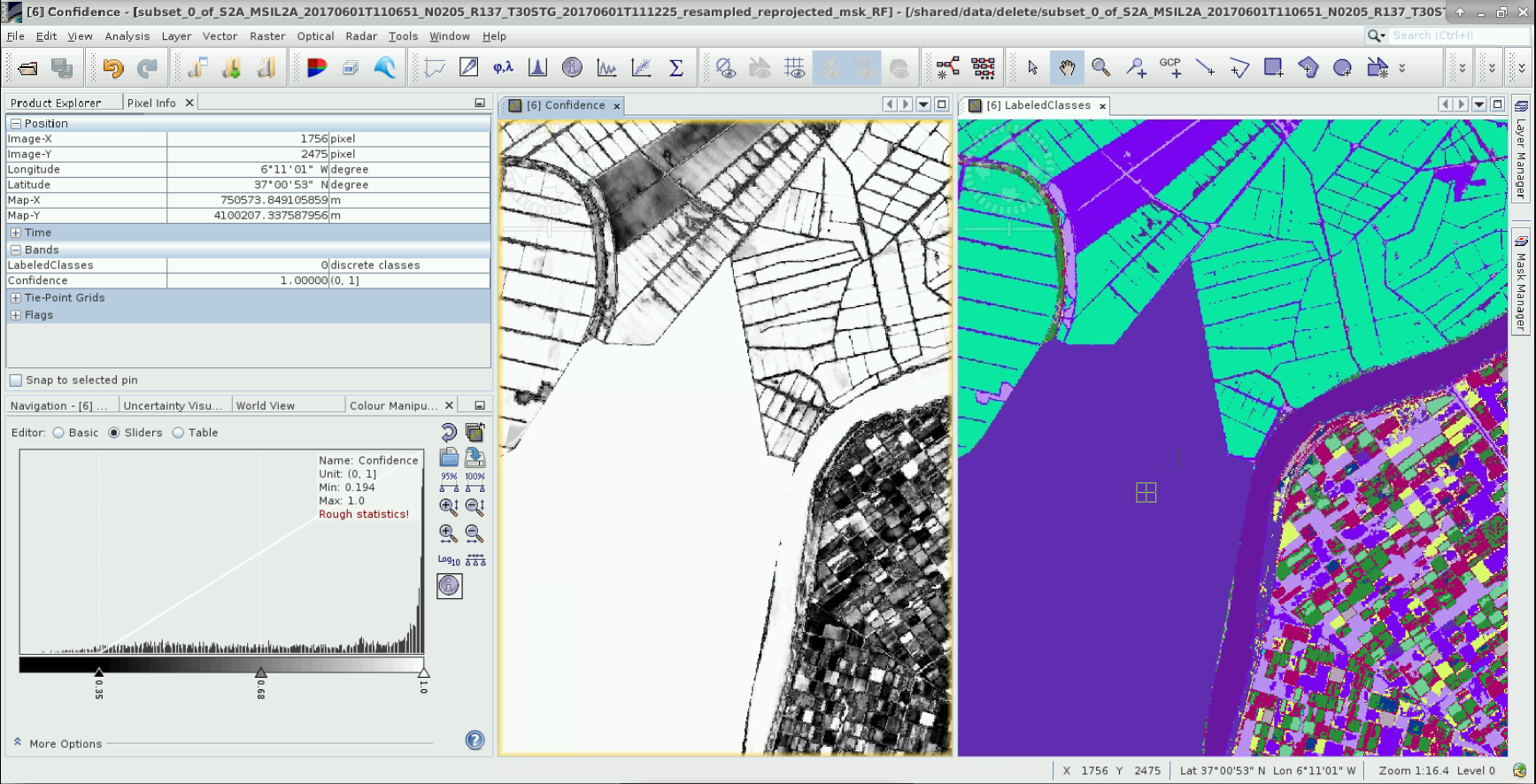
The confidence level of the NaN is 1 so I cannot play with the threshold. If the NaN cannot be classified according to the RF algorithm, why do they have a class (they are classified as bere soil). The statistics of the output are affected and there is a dedicated class (-1) for no data.