Hi,
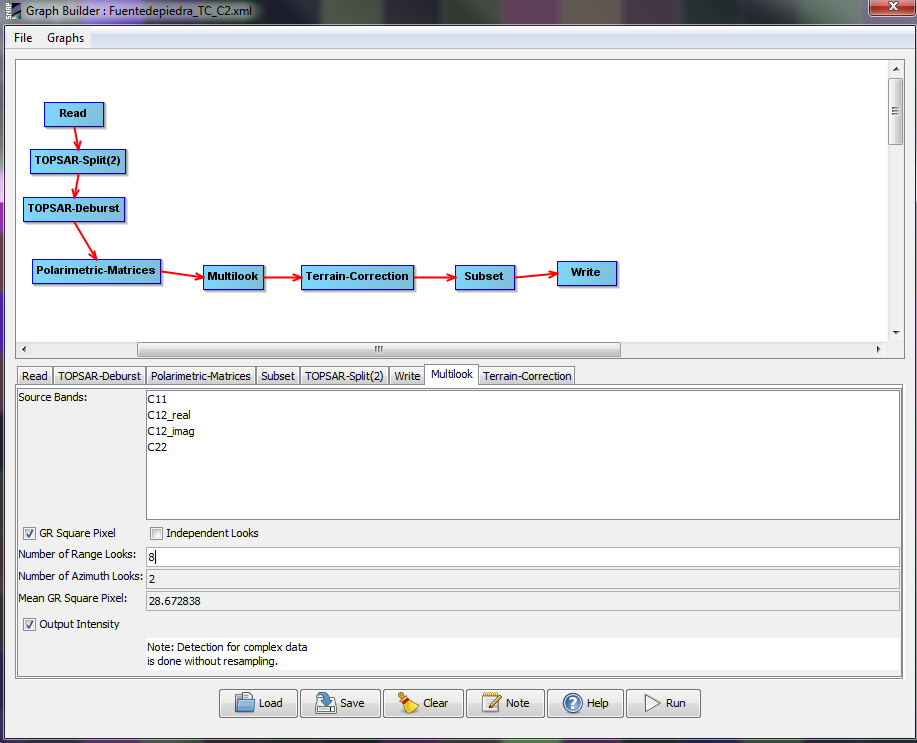
We are createing polarimetric image matrices C2 out of IW SLC (20 m x 5 m) Sentinel 1 images. We apply a multilook 8 range x 2 azimuth, and according to snap, the mean GR square pixel is 28.7 m, which is indeed the nominal pixel size of the final product.
My guess is that the C2 polarimetric image matrix is not anymore 20 m x 5 m. Is that so?
Or, why is the pixel size of the multilooked product ~30x30 m instead of 40x40 m?
Say you SLC product has a 14.1 m azimuth spacing and 2.3 m slant range spacing. If you multilook the image with 2 azimuth looks and 8 range looks, then you will have a multilooked image with 14.1x2 m azimuth spacing and 2.3x8 m slant range spacing. These can be seen in the metadata of the output product.
Then what is the mean GR square pixel? It is the pixel spacing on the ground. Sometimes we want the mutilooked image has a roughly squared pixel on the ground. The 2.3x8 m is slant range pixel spacing. To get the ground range pixel spacing, it should be projected to the ground.
Say you select “GR Square Pixel” in Multilook UI, the operator will suggest you with 6 for “Number of Range Looks” and 1 for “Number of azimuth Looks”. This is because with this setting the multilooked image will have a roughly square pixel on the ground, i.e. its azimuth spacing will be approximately the same as its ground range spacing. The two spacing won’t be exactly the same due to the integer limitation on the number of looks. The “Mean GR Square Pixel”, which is 14.02 m in this case, is actually the mean value of the two ground spacing.
Is multilooking a necessary step for processing the Sentinel-1 GRD product? If yes, how to decide the number of looks? Can the looks be 1 in range and 1 in azimuth, resulting in the GR square pixel of 10 m?
No it is not a mandatory step. GRD products are already multilooked. If you want to multilook further for higher radiometric accuracy you will further degrade the resolution - it is a trade-off.
If you have a stack of images using a multitemporal speckle filter instead multilooking is often a great way forward.
maybe as a further clarifying comment…
The ground range resolution of a pixel in slant range is computed by dividing the spacing by the sine of the angle of incidence:
Hi @Nizar I only picked up on the example above. This angle is computed by SNAP to be that of the scene’s center. Since @javier_unib did a spatial subset of the scene (with TOPSAR-Split), the angles from the link no longer apply. Furthermore, it is always better to use the angles contained in the metadata of the scene to be exact.
What I still not understand is the question of why the azimuth pixel spacing also differs from the specified 14.1m in the documentation. For pixel spacing in range direction I get the point of slant vs. ground range but in azimuth direction the pixel spacing shouldn’t be changed by projection, should it?
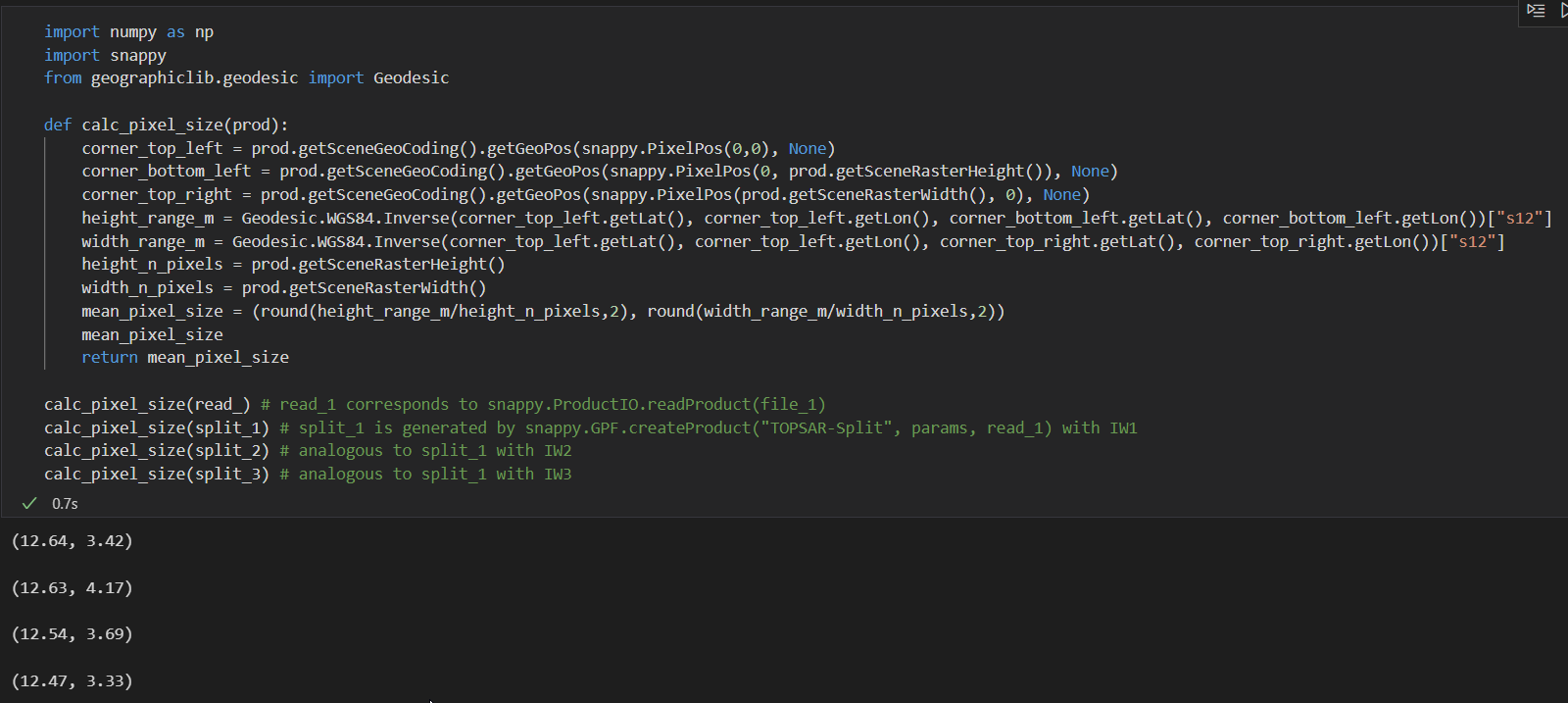
However, if I use the measurement tool in SNAP I obtain azimuth spacings of approx. 12.5m instead of 14.1m. The test scene for this (file_1 in the script below) was S1B_IW_SLC__1SDV_20210802T165835_20210802T165903_028070_035934_E327 but I checked this also for other scenes. I further validated the distance measurement using a short snappy script.
Hi @fkroeber
Your approach can always only be an estimation since you are computing the spacing based on the geolocation grid in map geometry and the pixel spacing in radar geometry. You always have to interpolate to a different pixel grid during geocoding and define your own spacing in the process. If you want to read out the original spacing, you’re better off just reading the entries in the annotation XML files.
Cheers,
John
I know that during terrain-correction I’m interpolating values and projecting them using a specified spacing. Nevertheless, I do not see why this calculation only serves as a rough estimate since it does explicitly not rely on the radar geometry. I’m calculating the spacing based on the number of pixels (which is constant regardless any projection/interpolation) and the coordinates of the edge pixels (which are also constant). If you refer to the fact that I’m only using two edges for the pixel spacing computation and different results may be obtained when permoing the calculation on different parts of the image, you are of course absolutely right! Albeit, the issue remains the same as the 12.5m can be measured almost everywhere in the image - the SNAP measurement tool confirms that azimuth spacing across the image is systematically lower than 14.1m. Or am I getting you wrong?
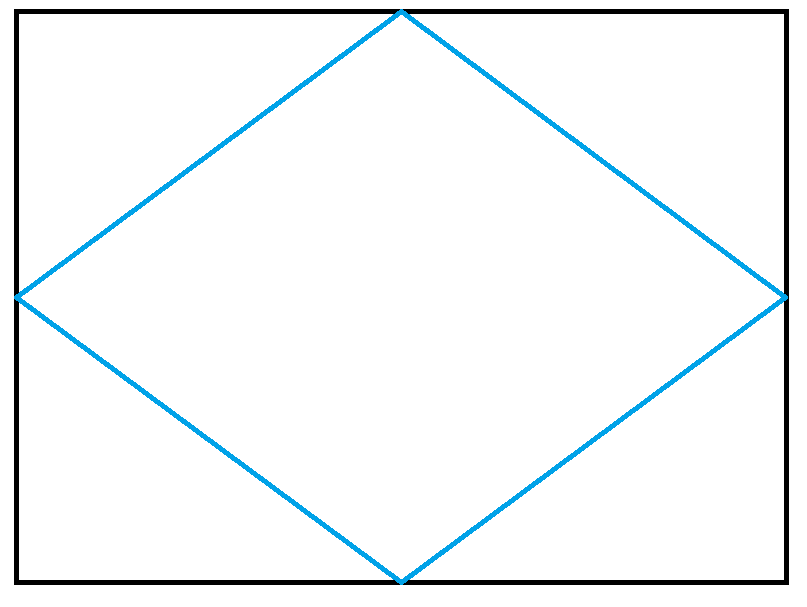
Considering map geometry, if the blue box is the scene’s footprint and the black box is the bounding box. Then the grid’s extreme coordinates (which are the edges of the blue box) do no longer correspond to the number of pixels in the original image.
Does that make sense? Perhaps I am also missing something…