Hi there.
Let’s start with some S1 SLC images.
I use snappy to read them and do other things. First, I will create list of products:
# Import some packages
import os
from glob import iglob
import snappy
# List of images
path_to_images = os.getcwd() + '\\data' # directory with S1 images
list_of_images = sorted(list(iglob(os.path.join(path_to_images, "**", "*S1*.zip"), recursive=True))) # list of images
list_of_images_ordered = sorted(list_of_images) # list of images sorted by date
This will be something like the following:
['F:\\SAR_desarrollo\\data\\original\\S1A_IW_SLC__1SDV_20191212T122550_20191212T122617_030315_0377A6_F08A.zip',
'F:\\SAR_desarrollo\\data\\original\\S1A_IW_SLC__1SDV_20191224T122550_20191224T122617_030490_037DB3_B342.zip',
'F:\\SAR_desarrollo\\data\\original\\S1A_IW_SLC__1SDV_20200105T122549_20200105T122616_030665_0383BE_D596.zip',
'F:\\SAR_desarrollo\\data\\original\\S1A_IW_SLC__1SDV_20200117T122549_20200117T122616_030840_0389DE_CC66.zip',
'F:\\SAR_desarrollo\\data\\original\\S1A_IW_SLC__1SDV_20200129T122549_20200129T122615_031015_039005_D843.zip',
'F:\\SAR_desarrollo\\data\\original\\S1A_IW_SLC__1SDV_20200210T122548_20200210T122615_031190_03961E_0594.zip',
'F:\\SAR_desarrollo\\data\\original\\S1A_IW_SLC__1SDV_20200305T122548_20200305T122615_031540_03A230_CB4E.zip',
'F:\\SAR_desarrollo\\data\\original\\S1A_IW_SLC__1SDV_20200329T122548_20200329T122615_031890_03AE68_6A4B.zip',
'F:\\SAR_desarrollo\\data\\original\\S1A_IW_SLC__1SDV_20200504T122550_20200504T122617_032415_03C0E6_2B80.zip',
'F:\\SAR_desarrollo\\data\\original\\S1A_IW_SLC__1SDV_20201031T122558_20201031T122625_035040_04167F_13BB.zip']
Now let’s read this list of images and make a list of products:
product_list = [] # empty list
for i, product_path in enumerate(list_of_images_ordered):
product = snappy.ProductIO.readProduct(product_path)
product_list.append(product) # fill the list
This product list looks like this:
[org.esa.snap.core.datamodel.Product(objectRef=0x000001C36DE9CA30),
org.esa.snap.core.datamodel.Product(objectRef=0x000001C36DE9CA28),
org.esa.snap.core.datamodel.Product(objectRef=0x000001C36DE9E0E8),
org.esa.snap.core.datamodel.Product(objectRef=0x000001C36DE9E0C8),
org.esa.snap.core.datamodel.Product(objectRef=0x000001C36DE9E0C0),
org.esa.snap.core.datamodel.Product(objectRef=0x000001C36DE9E0A0),
org.esa.snap.core.datamodel.Product(objectRef=0x000001C36DE9E098),
org.esa.snap.core.datamodel.Product(objectRef=0x000001C36DE9E088),
org.esa.snap.core.datamodel.Product(objectRef=0x000001C36DE9E078),
org.esa.snap.core.datamodel.Product(objectRef=0x000001C36DE9E058)]
Nice. Now we’ve got a product_list. We need to compute baselines for this product_list. This is the code:
create_stack = snappy.jpy.get_type('org.esa.s1tbx.insar.gpf.coregistration.CreateStackOp') # operator
baselines_product = product_list[0] # the baseline metadata will be stored in this product
# compute baselines using the .getBaselines() method
create_stack.getBaselines(product_list, baselines_product) # list of sar products, output product
# Here we extract the baselines from metadata
baseline_root_metadata = baselines_product.getMetadataRoot().getElement('Abstracted_Metadata').getElement('Baselines')
Finally, we will create a dictionary with the baseline info for a given primary date:
product_info_dict = {} # empty dictionary
primary_id = 'Master: 29Jan2020'
secondary_ids = list(baseline_root_metadata.getElement(primary_id).getElementNames())
for secondary_id in secondary_ids:
secondary_date = secondary_id.split()[1]
baseline_metadata = baseline_root_metadata.getElement(primary_id).getElement(secondary_id)
DB = float(baseline_metadata.getAttributeString('Perp Baseline')) # Perpendicular Baseline
DT = float(baseline_metadata.getAttributeString('Temp Baseline')) # Temporal Baseline
Df = float(baseline_metadata.getAttributeString('Doppler Difference')) # Doppler Difference
product_info_dict[secondary_date] = {}
product_info_dict[secondary_date]['Coordinates'] = [DB, DT, Df]
The dictionary looks like this:
{'12Dec2019': {'Coordinates': [56.49419021606445,
47.999977111816406,
2.306570291519165]},
'24Dec2019': {'Coordinates': [47.945621490478516,
35.99998474121094,
0.5621727108955383]},
.
.
.
}
And we can turn it into an array:
coordinates = []
for key in product_info_dict.keys():
coordinates.append(product_info_dict[key]['Coordinates'])
coordinates = np.array(coordinates)
Let’s see the baselines using 29Jan2020 as primary product date.
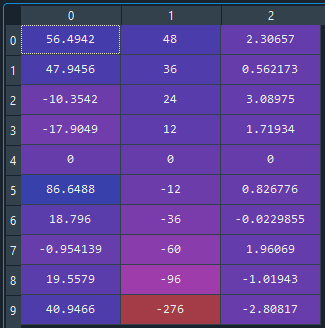
And using 31Oct2020:
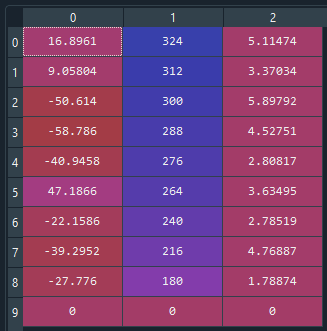
Now, it comes the problem. This is just a traslation of a reference frame, so I should be able to recover the values coordinates_29Jan2020 from the coordinates_31Oct2020 just by traslating the values:
coordinates_29Jan2020 = coordinates_31Oct2020 - [-40.9458, 276, 2.80817]
So that the [0,0,0] is again at the 29Jan2020, number 4 at the rows of the images. The new coordinates are:
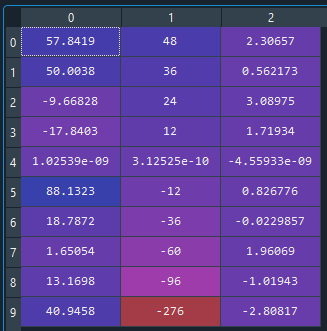
As you see, the Doppler and temporal baseline coordinates are correct, and the 29Jan2020 product has the [0,0,0] coordinates again. But the other perpendicular baseline coordinates, with very little difference sometimes, but much greater in other cases. This is like changing the relative position of the images in the [B, T] space, which makes no sense to me.
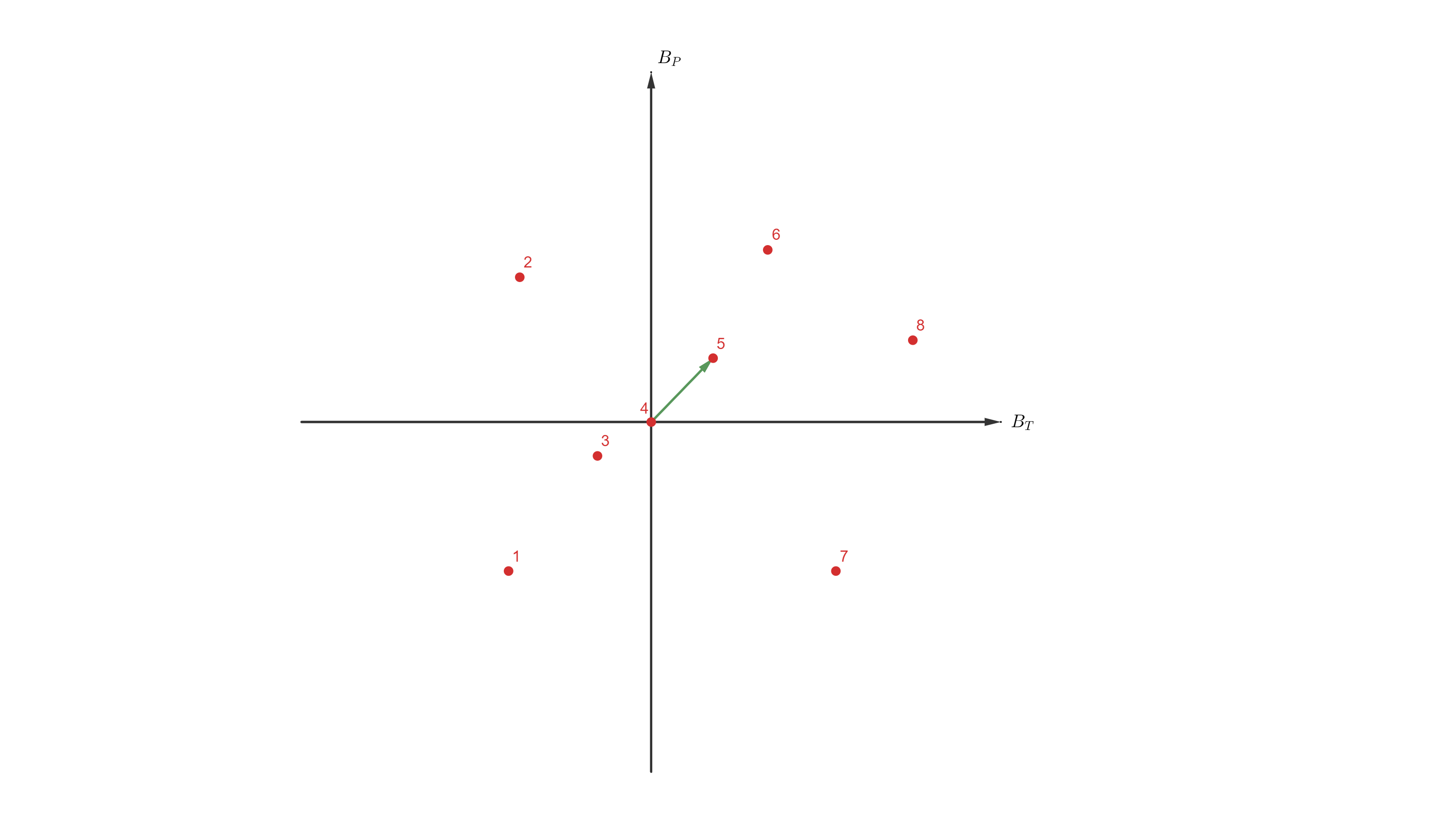
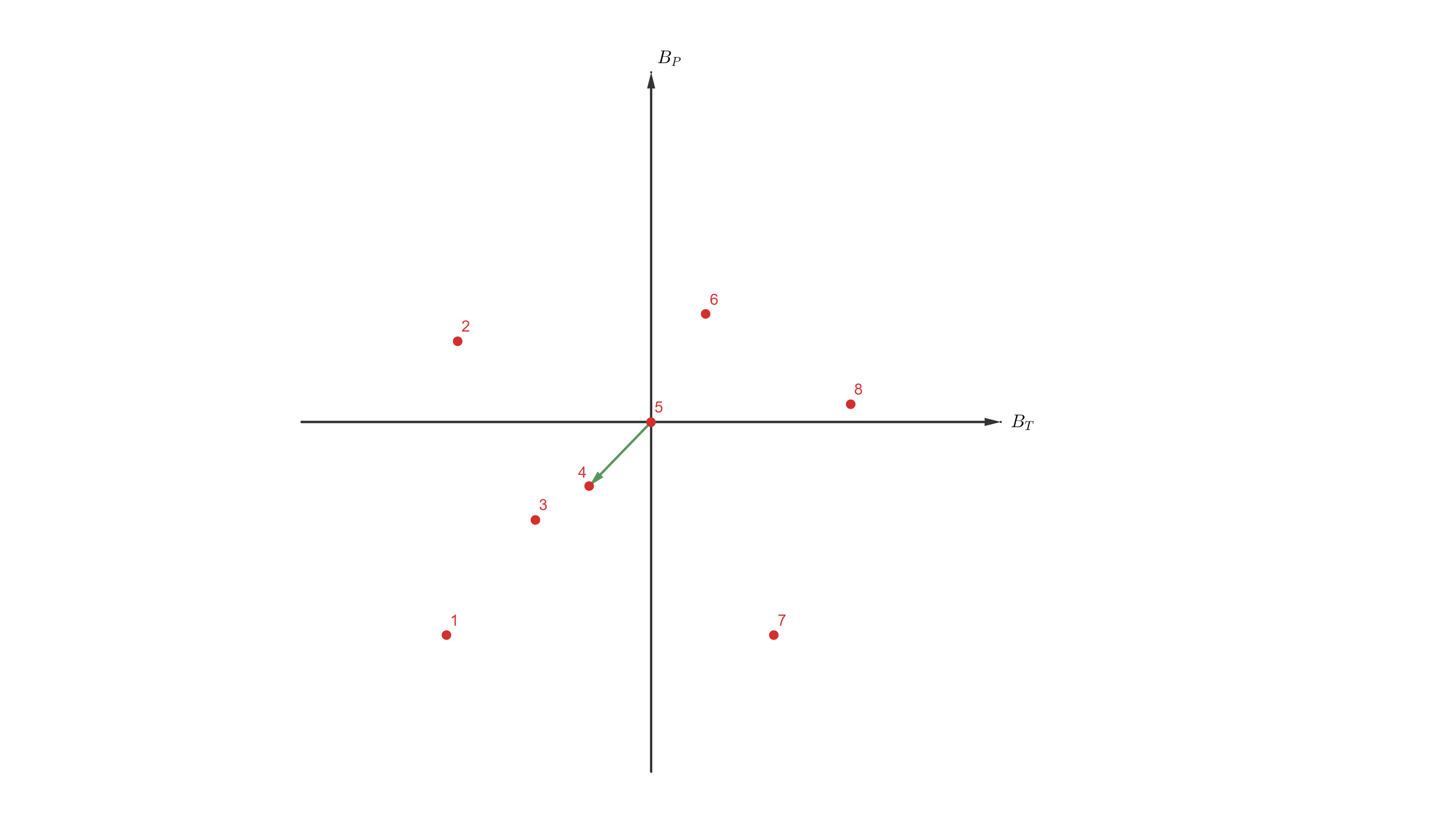
As you see, moving the reference system should not change the relative position between the points. This is a problem when I need to compute a Delaunay triangulation of the images, because it now depends on which image I put at the [0,0] position…