My current project is moving an on-premise Sentinel 1 processing pipeline onto AWS.
Part of our migration is aiming to use the Sentinel 1 Open Data Bucket https://registry.opendata.aws/sentinel-1/. The main reason is that S3 -> AWS will reduce download speeds, another benefit is that I believe the SciHub data is now a rolling archive.
Does anyone have experience processing this dataset with SNAP? We’re planning on running Subsetting, Radiometric Calibration, and Terrain Correction.
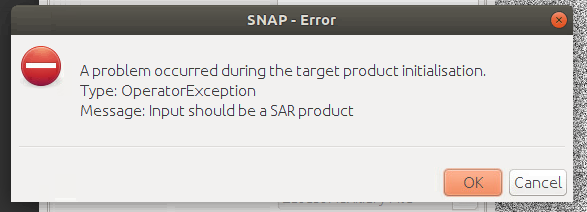
When I open a tiff, for example: GRD/2019/1/1/IW/DV/S1A_IW_GRDH_1SDV_20190101T003857_20190101T003922_025277_02CBAA_DDD4/measurement/iw-vh.tiff from the Open Data bucket inside SNAP and try to run Radiometric Calibration on it, I get the following error:
SNAP needs the metadata stored in the safe file in the top level of the product. Opening the tif file alone technically works but it does not contain any information on incidence angles, sensor specifics ect which are needed for radiometric calibration.
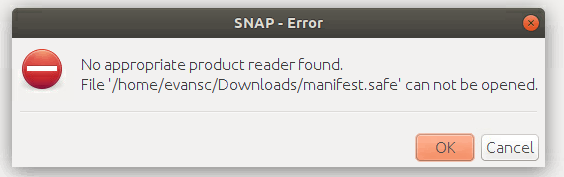
I think the overall structure of the product folder needs to be maintained. So the manifest.safe is in the top folder and the tif file is in the measurement folder.
But there is also a support folder which contains files like S1_level1_calibration.xsd, so I assume they are needed as well.
Maybe I missed the point: Why are you not downloading the entire product folder from AWS?
Turns out it was a simple as downloading the total of that prefix and afterward SNAP joyfully opens it as a Sentinel 1 Product.
Not the most exceedingly terrible thing on the planet as we can simply clear up the downloaded documents
I accepted I could simply utilize the band I really wanted, the envelope is certainly not a ‘solitary’ downloadable on AWS, it’s only single documents isolated by keys.So if I somehow happened to download the manifest.safe record for the given spat, could that conceivably work?
I’m wanting to do this automatically with smart and utilize the AWS facilitated information, would there say there is a great way I can open them ‘together’?