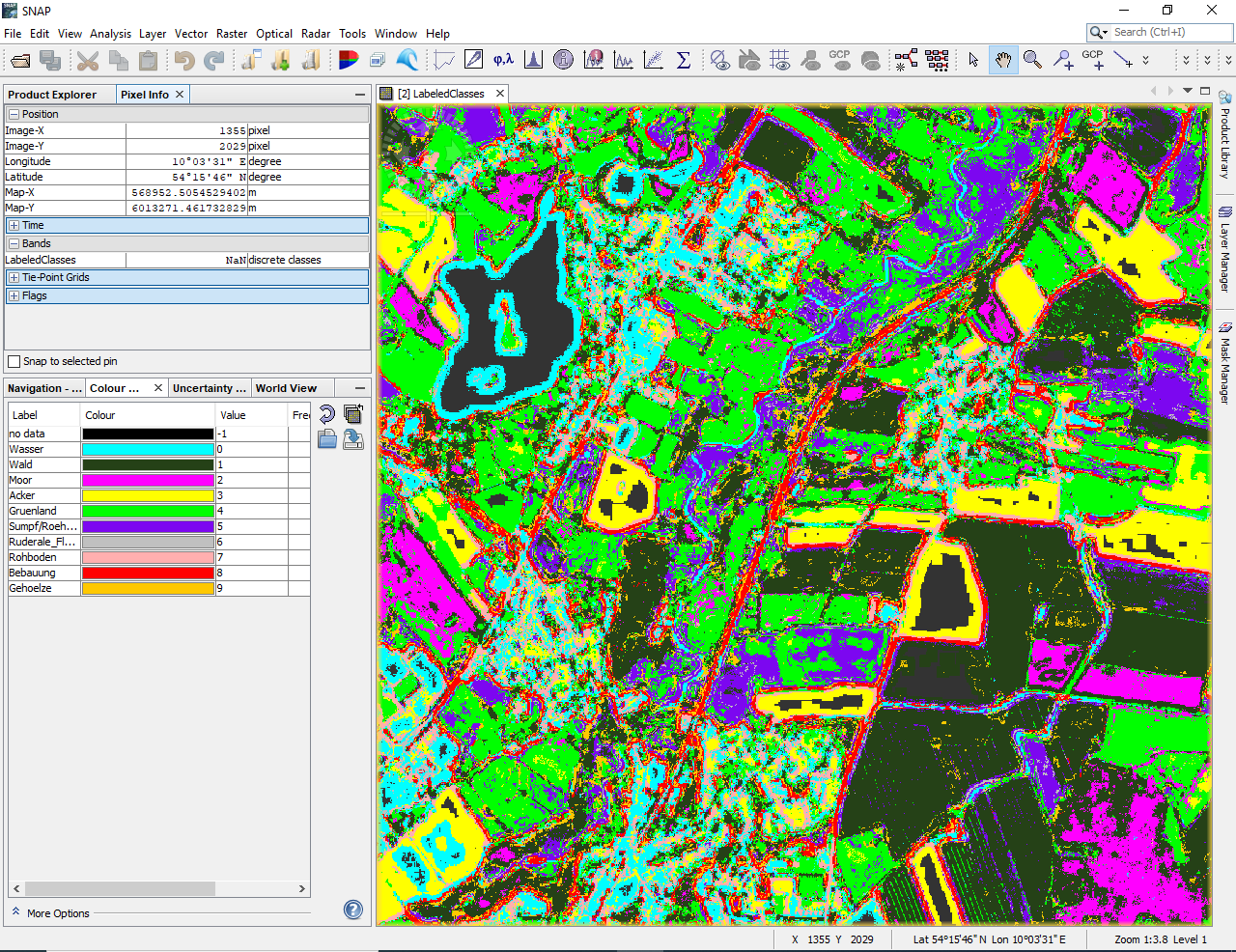
I have a question regarding the random forest classifier. I would like to classify a raster stack of SPOT-6 (B01, B02, B03, B04, NDVI, NDWI, glcm_contrast, glcm_entropy, glcm_mean, glcm_correlation) with random forest:
raster → classification → supervised classification → random forest classifier
I used 500 trees and trained by vector shapefiles with 10 land use classes.
But some regions always get NaN values (e.g. a lake or arable land - see screenshot black regions) even though there are training data in these regions. I already deleted the confidence in the valid pixel expression.
Is there a reason why SNAP produces NaN values with the random forest classifier?
Either it is a matter of low confidence (please see here: Landcover classification with Sentinel-1 GRD page 22-23) or one of your input datasets contains NaN values at these pixels (often happens with textures).
Hello! I am a beginner in learning Snap. While following the document you mentioned to learn land cover classification, I completed the terrain correction step of data pre-processing (page 11). The valuable water were corrected and turned into NaN. Do you know how to handle it?Thanks for any help!
NaN values might happen if some of your input data, like textures or bands, have missing values. Check your input layers to make sure there are no NaN values. You can also adjust the settings to improve the confidence in your classification