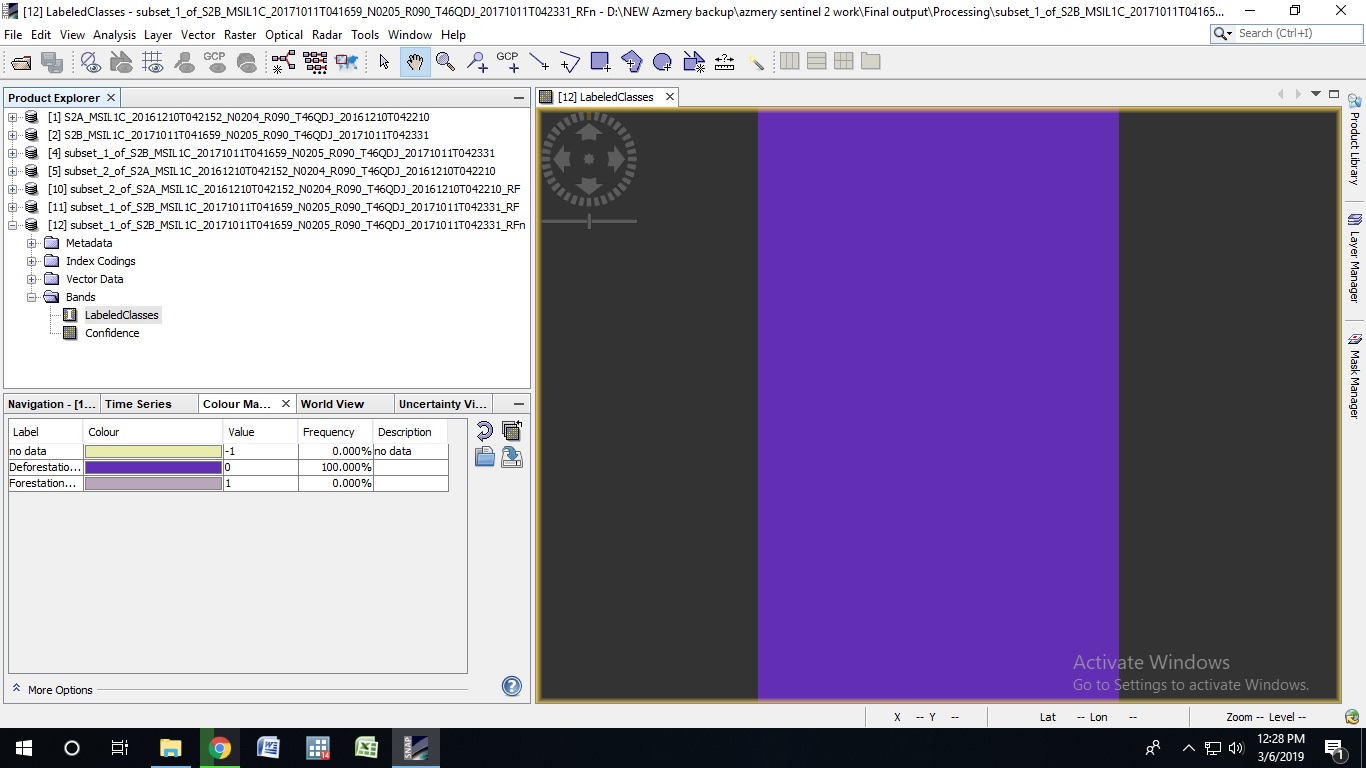
I have been trying to perform Random Forest Classification with Sentinel 2 image. But I keep getting this as a result. Please Help
Regards,
Azmery
1 Like
what kind of training data do you use and how many samples do you have for each class?
I am using a shapefile of my area and just selected 2 classes- forest and non forest.
Your result looks like that all pixels are likely to lay in class 1 and none in class 2.
How many bands are used as input rasters?
Can you please post a screenshot of your training areas (in the whole image)?
1 Like

I see two problems here:
- you are using images in high wavelengths and none in the visual spectra. This gives your classes a limited amount of separability. Make an RGB image of B4 B8 and B11 to see how different the surfaces are in your feature space. If the training areas look similar, the classifcation has no good starting point.
Is including all 13 bands of Sentinel-2 an option? - More critical is tht both of your training classes contain large amounts of cloud pixels. These are highly dominated by very bright pixels (white clouds) which do not represent the landcover underneath (forest/no forest). You can either make clouds an own third class (only select pure cloud pixels) or you have to reduce your training areas on surfaces which are neither affected by clouds or their shadows. Otherwise, you are training false image features (clouds) while you actually want land characteristics.
Nice study area by the way, I suppose it’s the Kutupalong refugee camp, right? 
Okay I will try to make it RGB image. and yes all 13 bands are present and I am following the SNAP sentinel 2 image pre proccesing manual to pre process the image. Also please check this image for cloud pixel thing. This image does not have much of cloud pixel issues, yet it gives same results.
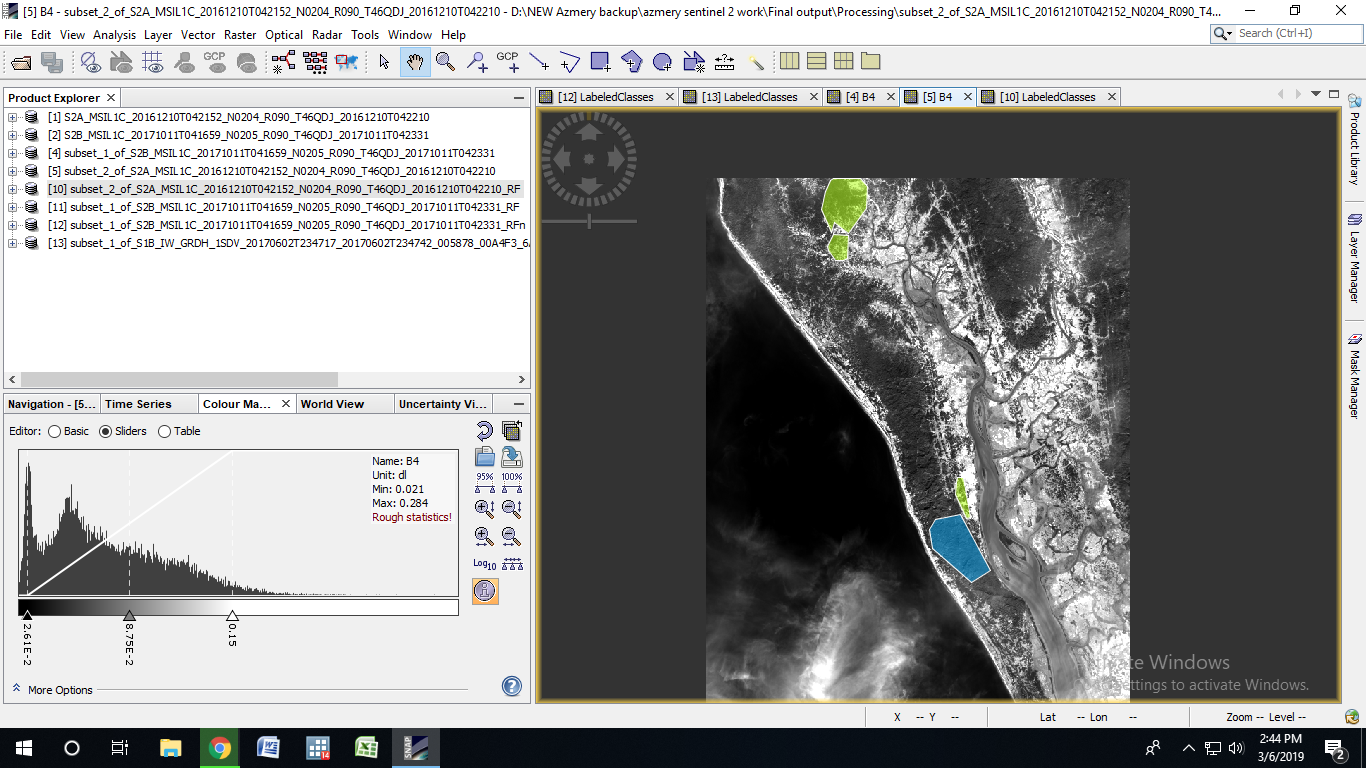
and yes its the Kutupalong and Balukhali refugee camp. I want to monitor the deforestation in that area 
the classification you first showed was based on the image from 11.10.2017 with lots of clouds. You can try again with the cloud free image or change your training areas.
If you ran sen2cor to preprocess the scene make sure you include all resolutions: Sen2Cor-02.05.05-win64 - AttributeError: 'L2A_Tables' Object has no attribute '_L2A_Tile_PVI_File'
what I am saying this image does not even have clouds but yet it shows 100% deforestation. Can you be more detailed about my training datas. Also I don’t have sen2cor, what can I do?
of course it has. They are just not visible in B11 and B12. And I am quite sure that these clouds cause the faulty classification.
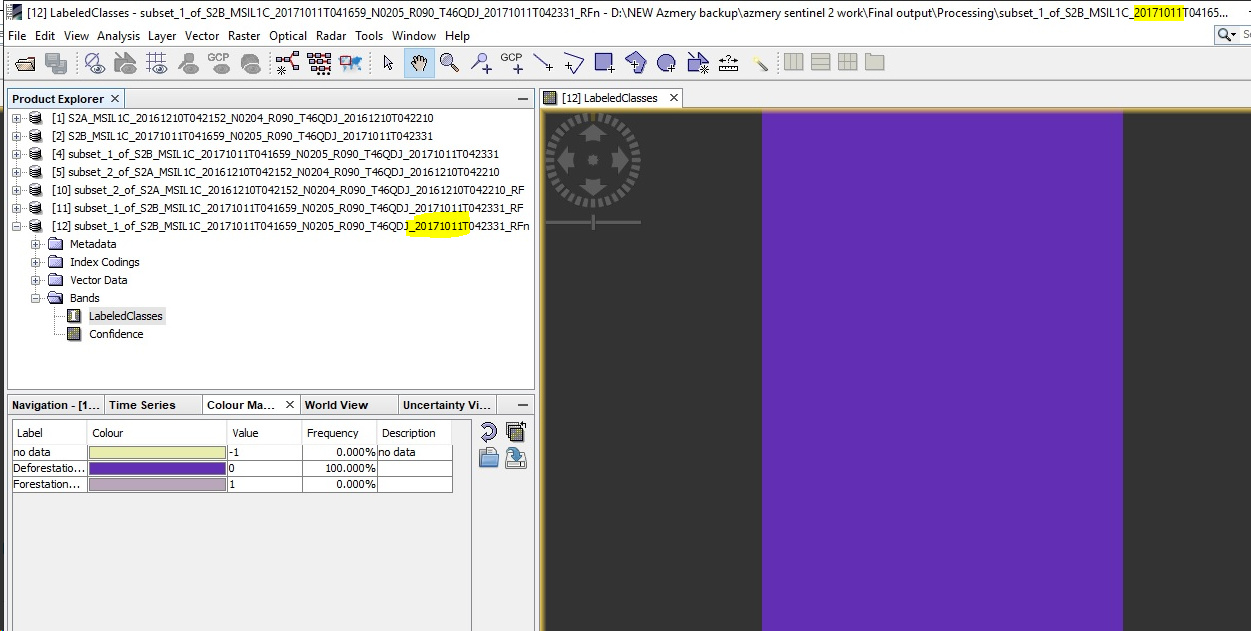

All the white spots are clouds. Your training areas should only contain pixels without clouds and your training rasters should contian B1 to B12.
sen2cor radiometrically calibrates your image to surface reflectance (L2A). It is advised if you want to compare images of multiple dates.
If available in the archive you can also download the calibrated products (L2A) instead of the uncalibrated (L1C).
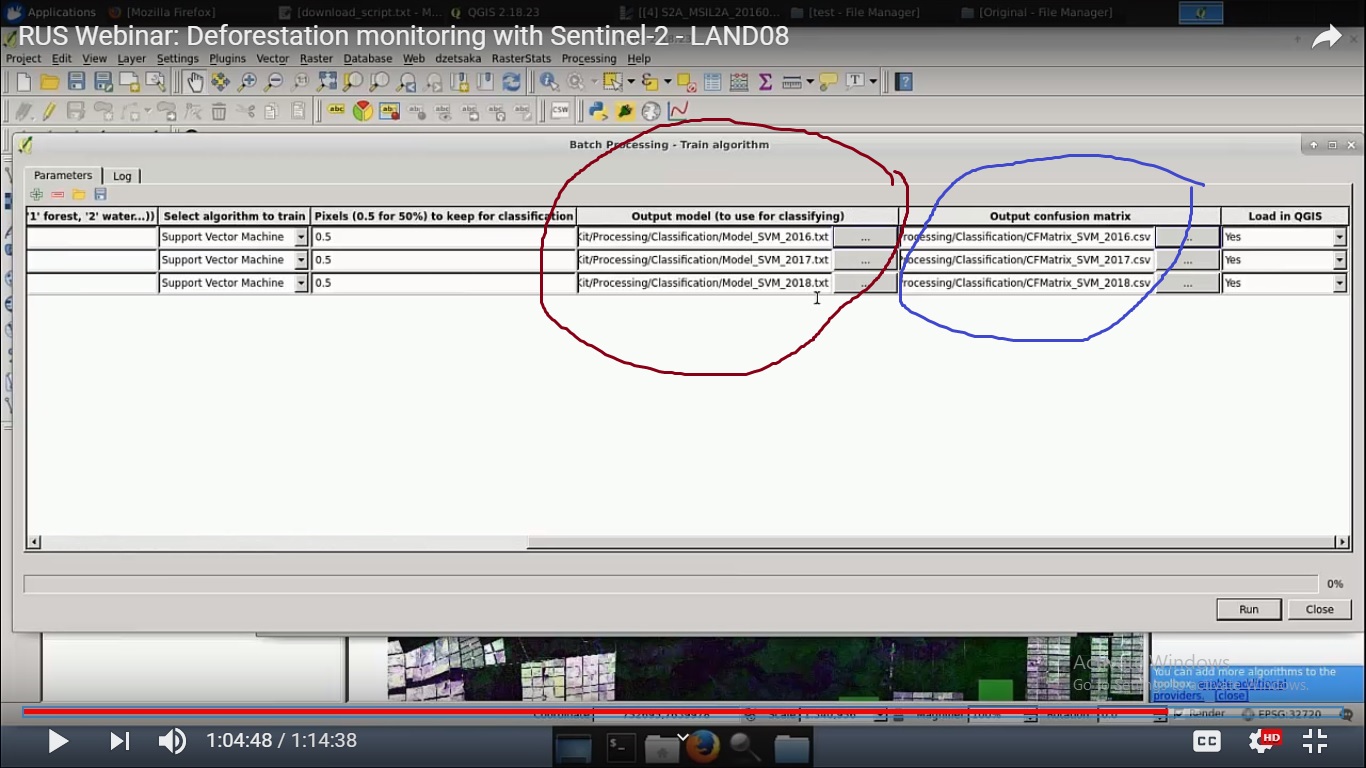
Hi I am now trying the SVM method suggested in the manual of Deforestation monitoring with Sentinel-2. And now I do not understand how they got output model for classifying (marked in red) and the Output Confusion matrix (marked in blue). Please help me.
Please find the attached image here.
Regards,
Azmery
Andreas
This discussion is very usefull, I learn from trial and errors
to adress my topic : above ground biomass with sent 1 sigma0 HV signal using sent2 L2A training classes LAI products calculated from B4,B5,B6, B7 ( LAI -say leaf area index -is closely related to AGB )
I would like to use RandomForest classifier :I still do not use polsarpro ,( but am going to )
-in winter wheat
-how many trees would be optimal ( 200 ?) knowing that my goal is to get as many as 4 classes in the resulting classification
-Reading this topic you gave me an idea : i shall not use vectors but pixels ranges training rasters ,each one specific to a class of LAI that fits to the patterns I see in the fields .
-Is a number of total pixels of about 700 sufficient ? ( 160 per classes ) resolution 10x10 meters
-is it possible to make a recursive boucle for - is it already implemented in R Forest ?
As you say , perhaps I shall not get a high accuracy , but some litterature show good results
I hope my questions are not too stupid !!
Many thanks
Best regards
Bruno
if you have the capacity to run 200 trees, you can do it. There is usually a saturation at which the quality no longer increases. But generally, the more trees, the bigger benefit is retrieved from the randomization. This also depends on the number of input layers. If you have only 2 bands, there is no way to randomize and recombine them in multiple way so the only random component is the subset of training pixels. Again, if you have digitized 700 pixels, setting this value to 2000 won’t bring any improvement. So the number of training samples should be smaller than the absolute sum you have because then a different subset is selected with each realization (each new tree) and by this, the algorithm sequentially finds rasters and thresholds with the highest impact.
I still recommend using vectors as training polygons, but if you manage to create rasterized training samples (with NoData at all non-training areas), it should work as well.
Generally, random forest works best with large training inputs (many bands and lots of samples), because only then the randomization is effective. Using only VH band is technically possible, but kind of ruins the whole idea of the RF algorithm. Or did I misunderstand your point and you are using a series of VH bands of different dates? This, in turn, would make sense very much, because the temporal variation is then part of the feature space.
I wonder why you use a classification method to model a gradual variable, such as the LAI. Wouldn’t be a regression, for example, more suitable?
I’d like to comment on this by bringing the comment of our colleague @johngan
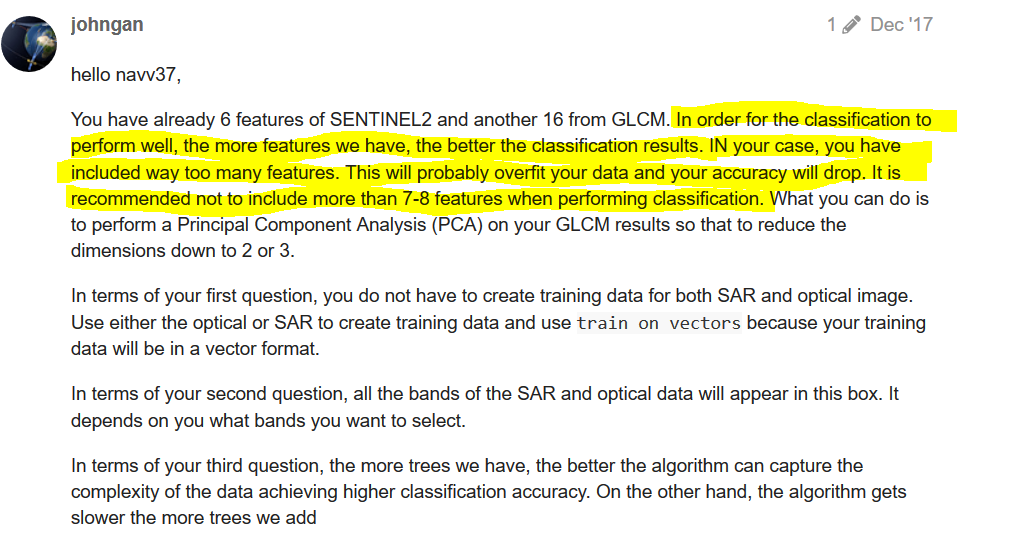
Accordingly more features leads to lower accuracy!
He might be right in a way that texture rasters (GLCM) are highly redundant and often have only few differences. For each tree, a subset of all input rasters is used for training (often the square root of available). That means, it does have a positive effect if I have 3 training inputs or 12. But it will probably no longer increase the quality if I have 25 or 35.
If I have only one or two bands, each tree is based on the same data - therefore it is no longer decesive if I run 10 or 100 trees. Therefore, all the parameters play together - number of input rasters, number of samples and number of trees. Increasing only one while the others are low will not lead to better results.
1 Like
Is there anyone know how to get the Random Forest plugin in SNAP 6.0
I could not find it when installing SNAP.
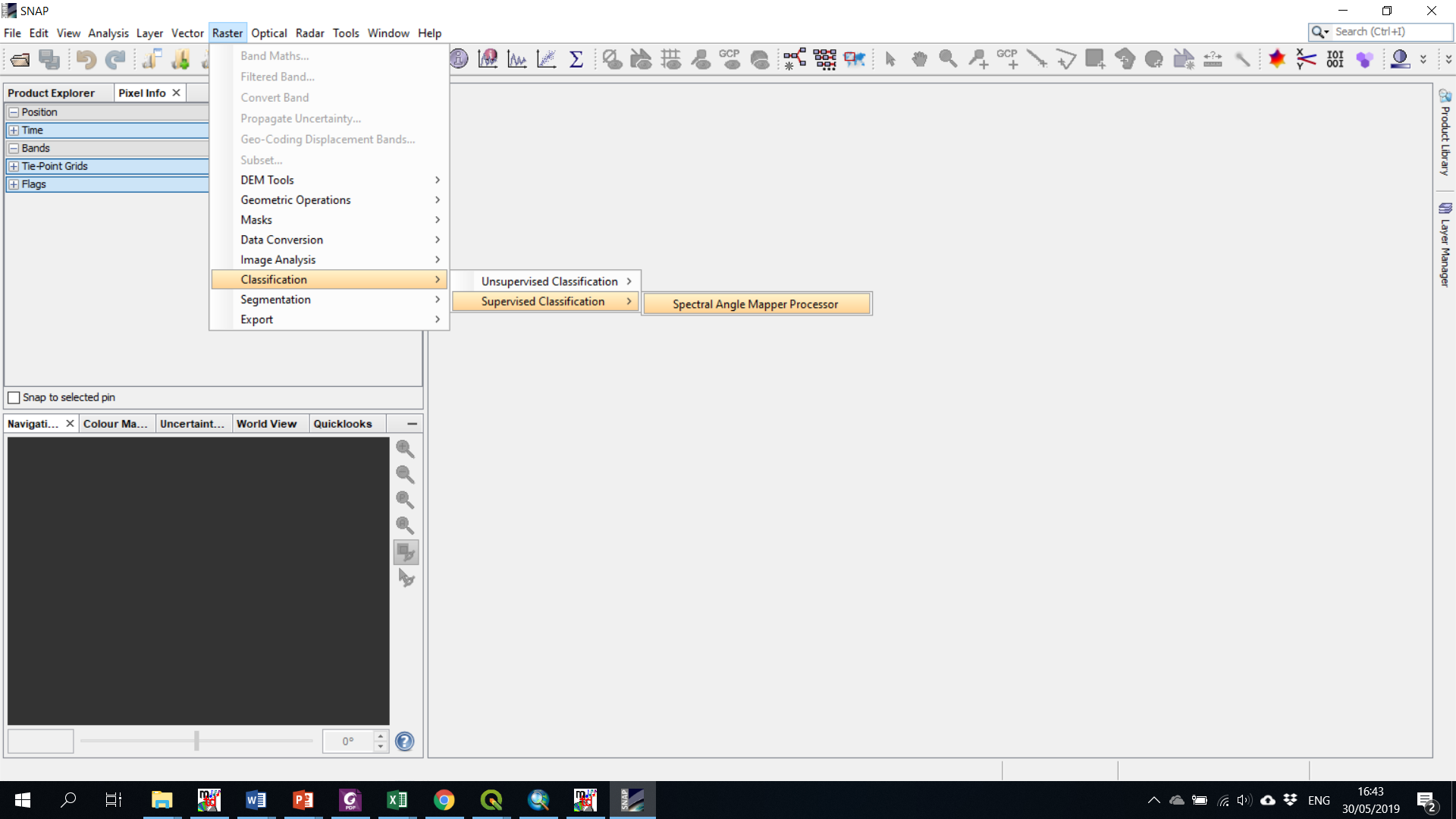
Seemingly your SNAP missed many other classifier as well, please check up the update ,
Help-------》 check for update
1 Like