Hi,
In order to perform a supervised classification such as random forest in SNAP, you have to collect training datasets for each class as shown in the image below.
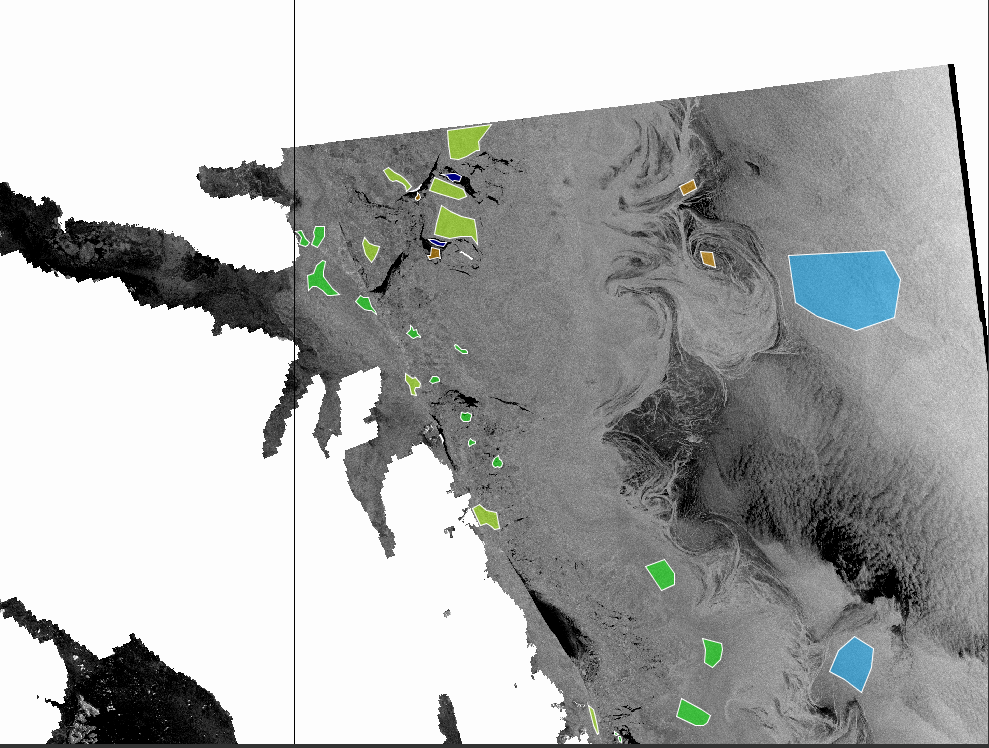
The image above shows different sea ice types and the vector files are the training data. Training data (shapefile format) can be created either using SNAP or QGIS. If training data are not specified, random forest cannot be performed.
The parameters for random forest in SNAP are specified as follows:
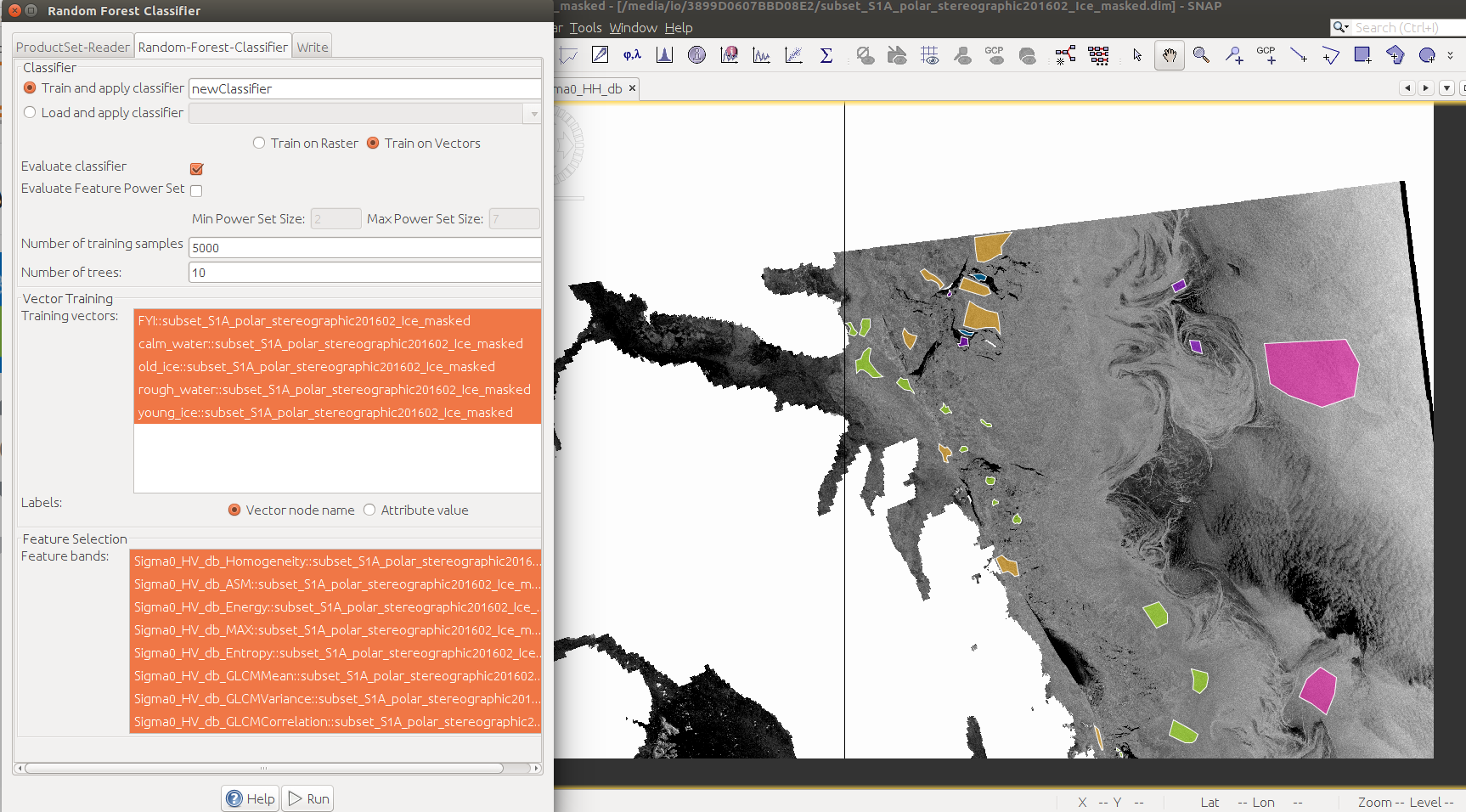
We see in the first box, we select the training data we have crated for each sea ice type and at the second box, we select the bands (GLCM bands).
If we press run, random forest algorithm runs without any issues
I hope this helps