Hi,
I am struggling with a problem of understanding here and I was hoping you may be able to offer some insight.
I have a S1-GRD processing chain that I run in SNAP. It looks like this:
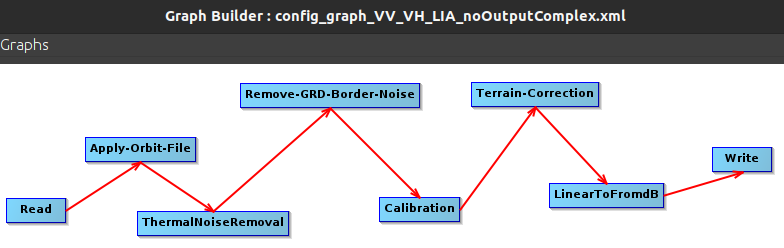
The outcome of this are
Sigma0_VH_db, Sigma0_VV_db, LIA_db, which is great and works for the intended purpose. However this is very costly to process on a large scale. So I am looking to use Microsoft Planetary Computer, as they have a S1-GRD product that is also processed and known as S1-RTC. You can see their product hereTheir product output is COG files which are “terrain-corrected gamma naught values with radiometric terrain correction applied”. They describe their entire methodology in as such:
"The Sentinel-1 GRD product is converted to calibrated intensity using the conversion algorithm described in the ESA technical note ESA-EOPG-CSCOP-TN-0002, Radiometric Calibration of S-1 Level-1 Products Generated by the S-1 IPF. The flat earth calibration values for gamma correction (i.e. perpendicular to the radar line of sight) are extracted from the GRD metadata. The calibration coefficients are applied as a two-dimensional correction in range (by sample number) and azimuth (by time). All available polarizations are calibrated and written as separate layers of a single file. The calibrated SAR output is reprojected to nominal map orientation with north at the top and west to the left.
The data is then radiometrically terrain corrected using PlanetDEM as the elevation source. The correction algorithm is nominally based upon D. Small, “Flattening Gamma: Radiometric Terrain Correction for SAR Imagery”, IEEE Transactions on Geoscience and Remote Sensing, Vol 49, No 8., August 2011, pp 3081-3093. For each image scan line, the digital elevation model is interpolated to determine the elevation corresponding to the position associated with the known near slant range distance and arc length for each input pixel. The elevations at the four corners of each pixel are estimated using bilinear resampling. The four elevations are divided into two triangular facets and reprojected onto the plane perpendicular to the radar line of sight to provide an estimate of the area illuminated by the radar for each earth flattened pixel. The uncalibrated sum at each earth flattened pixel is normalized by dividing by the flat earth surface area. The adjustment for gamma intensity is given by dividing the normalized result by the cosine of the incident angle. Pixels which are not illuminated by the radar due to the viewing geometry are flagged as shadow.
Calibrated data is then orthorectified to the appropriate UTM projection. The orthorectified output maintains the original sample sizes (in range and azimuth) and was not shifted to any specific grid.
RTC data is processed only for the Interferometric Wide Swath (IW) mode, which is the main acquisition mode over land and satisfies the majority of service requirements."
So how different is their RTC product from the one I generate by using the xml graph in SNAP?
Well… I see no mention of using updated orbit files, so they are probably using the native one. I don’t see any mention of ThermalNoiseRemoval, GRD Border Noise Removal or linearTodB function. I do however see information about calibration and terrain correction, and when I load the cog file into python, I apply a db scale to it, so disregarding the linearTodB function then.
Now besides the seemingly descrepencies in processes, missing the noise removal, it is also the different use of sigma/gamma terms that I seek to understand. I thought once we calibrate, the product “becomes” sigma0. I found this statement on a guide somewhere …“It [read: Calibration] produces calibrated backscatter values, known as sigma0, which represent the radar reflectivity of the observed area.”. So what is what here? The SNAP end product outputs it as sigma0_VV_dB. The S1-RTC says it outputs Gamma0. The processing, besides noise removal and the final linearTodB, seems to be similar.