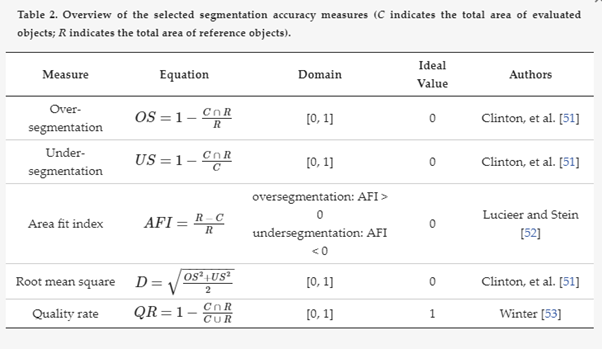
I am experimenting with the segmentation options in SNAP (e.g. Batz&Schape - or Lambda like the FLS in ERDAS) and all seem to be working fine - but what I would like is a way of quantifying results under different settings, using methods you see in literature such as oversegmentation, undersegmentation, area fit - etc.
Firstly - which which would you prioritise?
Secondly - what is the best way of doing this in SNAP?
I don’t have a solution (or an opinion) but may I ask what you do with the segments in SNAP - as these are just raster patches representing the number of each segment.
I saw that mentioned that in an older post when i searched earlier today - but hoping it had been clarified in later versions as to be honest I am not sure what happens next.
The user needs to then classify those rasterized segments but I cant find an attribute table to see what it is at currently. I was looking at this in Scikit a while back and found a good tutorial:
First you need to assign them a unique identifier attribute
Then you classify those using SVM or RandomForest or similar - so somehow this output needs to feed into the RF classifier in SNAP, ‘train by raster’ and ‘train by vector’ are an option but thats the training data i presume, not classification datatype input.
Thank you. It would indeed by great to have the segments as vectors whose attributes could at least be exported. My question was rather adressing if you already found a way to use these segments within SNAP.
Still, thank you for the reference.
In the past I had my own workaround used segments generated in QGIS and calculated zonal statistics, then I exported the attribute table to analyze it in Orange (https://orange.biolab.si) and imported the classified table back into QGIS to join it there with the geometries. So basically what the python script does.
I tried modelling the whole process in QGIS with the OTB add-on in the model builder - but one of the later steps kept crashing on me, not sure what the issue was and got sidetracked.
No wonder eCOGNITION and Imagine Objective are so popular!