Maybe my explanation was not good. The problem that I have should not be very complicated.
As you may know unlike S2 products which are enhanced with GeoTransformation, S1 products do not provide such information. Lets take a look at the result of calling for this information using two random S1 and S2 tiles. When you call gdal’s gt=ds.GetGeoTransform():
the case of S1: gt = (0.0, 1.0, 0.0, 0.0, 0.0, 1.0)
the case of S2: gt = (499980.0, 10.0, 0.0, 1100040.0, 0.0, -10.0)
We know that the 6 provided values in each tuple are being interpreted as:
0 - Origin x coordinate
1 - Pixel width
2 - X pixel rotation (0 if image is north up)
3 - Origin y coordinate
4 - Y pixel rotation (0 if image is north up)
5 - Pixel Height (negative)
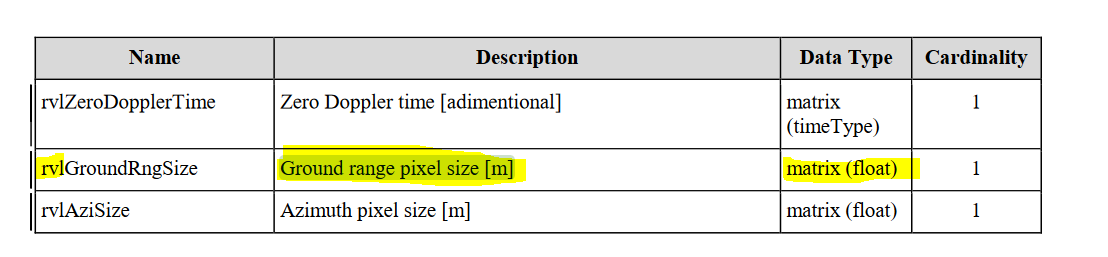
In the case of S2 one easily gets the width and height of the pixels from this metadata. (In case of different bands this pixel size value changes).
In the case of S1 though no information is provided. I have tested different hypothesis and came up with two Observations:
Observation 1):
If I use SNAP and select a spatial window from the S1 tile (manually providing Geocoordinates) and export it as a new image then the geotransform information is being added to the product which in my case is :
gt = (-51.390484599947186, 0.00020748114436486276, 0.0, 71.35720128316908, 0.0, -0.00010813274440124587)
here gt[0] and gt[3] correctly provide the coordinate (lat/long) of the north-western pixel Img(0,0).
gt[1] and gt[5] are supposed to present the pixel width/height.
There are two problems here however:
First) These values are not the same as you can see.
Second) I can not relate these values to 10x10 size that is mentioned in Sentinel-1 manual. why these values are such small fractions?
Observation 2):
I noticed that within the metadata of each S1 tile there is a collection of ground control point GCPs which is possible to access either by reading annotation .xml files or simply by calling ds.GetGCPs() function of GDAL. Within these GCPs one can find the coordination of 4 pixels representing the four corners of a tile. therefore by having these coordinates and the number of pixels in each dimention we can calculate approximately (in a linear sense) the width and height of each pixel. When I did this the result of calculation is again far from the expected value 10.
I would appreciate your comments on these observations.
With regards,
Sina