Hello all,
I’m was trying to figure out what exactly is happening during SliceAssembly with the binary image data of two slices. Especially in the overlap region of two SLC scenes.
In the documentation of the SliceAssembly operator it says:
Sliced products may be seamlessly combined, including the metadata, into an assembled product. Product assembly follows specific rules for including, merging and concatenating the various components of the slice products. […]
Slice products can be combined to form an assembled Level-1 product with the same product characteristics covering the complete segment. Assembly is performed following the three strategies of Include, Merge and Concatenate.
- Include - the value of the information is identical for all slices and a single occurrence of the value is copied into the assembled product.
- Merge - the value of the information may differ between slices and a single value must be amalgamated into the assembled product using the values from all slices. This can be accomplished by means of averaging, majority polling, summing, etc.
- Concatenate - the information is stored in list format and the values from each slice are appended to the appropriate list in the assembled product in Zero Doppler Time (ZDT) ordered sequence and the list count attribute is updated to contain the number of items in the concatenated list. This applies to both binary image data and XML lists.
Now, this doesn’t explain what exactly is happening to the various components of each product. Are overlap regions of the binary images merged? If so, by what means? Furthermore, the documentation doesn’t provide any references.
I have browsed through the code of the SliceAssembly operator and looked through various forum threads but wasn’t able to find an answer to my question. I then found section 3.4 of the Sentinel-1 Product Specification, where the assembly strategy for Sentinel-1 is explained in more detail. If the SliceAssembly operator is following this strategy, then this information should be provided in the documentation page and list the S-1 Product Specification as a reference!
The Product Specification describes that imagery data is concatenated (see section 3.4.1.3 and figure 3-6). To see if SNAP is actually using this strategy as well, I performed a simple test of processing two consecutive SLC scenes individually with a simplified graph (Read-NR-Deb-Orb-Cal-ML-TC-Write) and using the same graph to process the assembled product of both scenes. By comparing the results, I found out that, indeed, concatenation is performed roughly in the center of the overlap region… great!
HOWEVER, I also found a difference in non-overlap regions. I expected the results in these areas to be identical between the assembled product and individually processed scenes, but a pixel shift and misalignment is introduced, which ultimately results in backscatter differences because of the resampling performed during Terrain Correction. You can see an example in the following image, where it’s alternating between the assembled product and one of the individually processed scenes in an area outside of the overlap region:
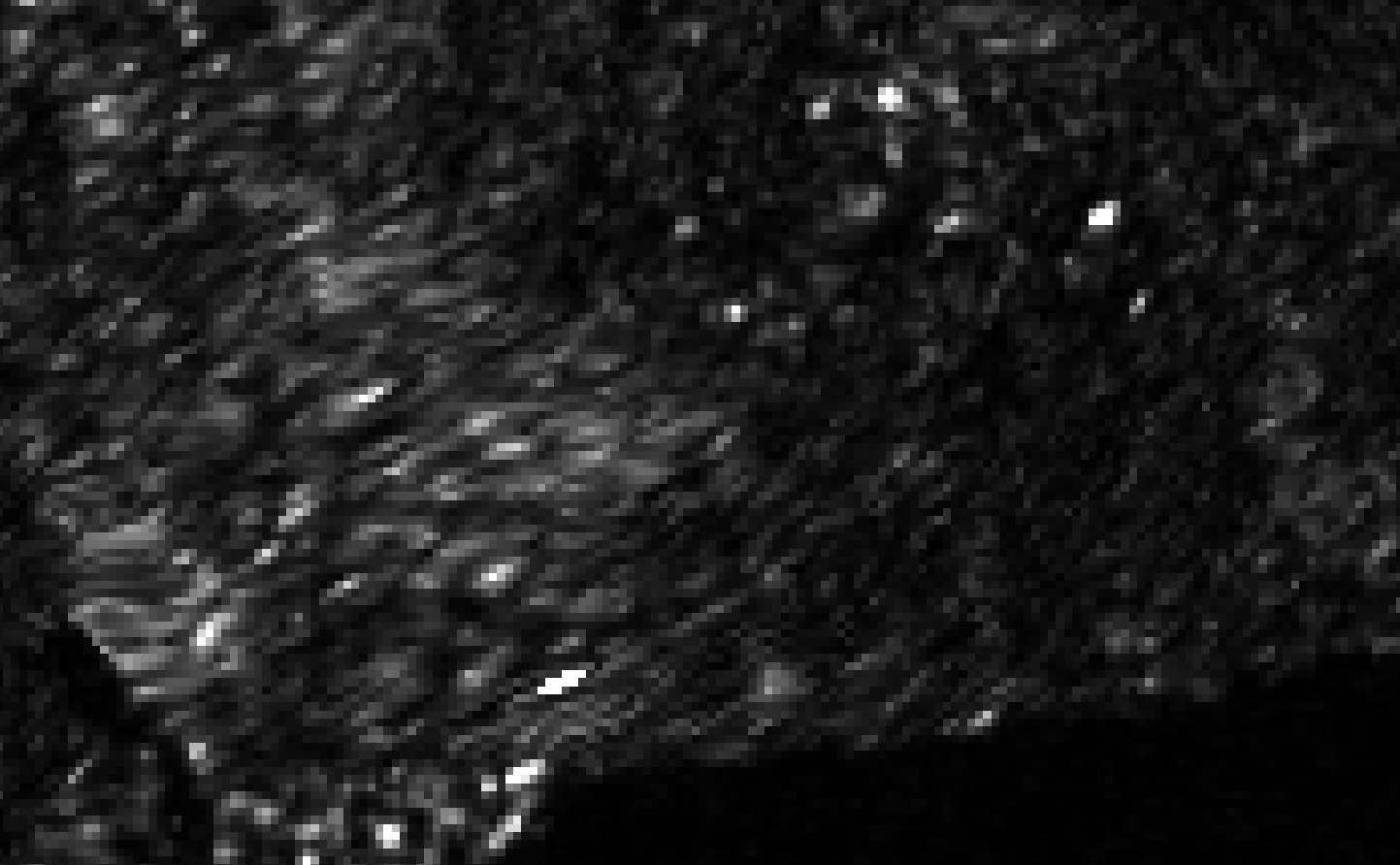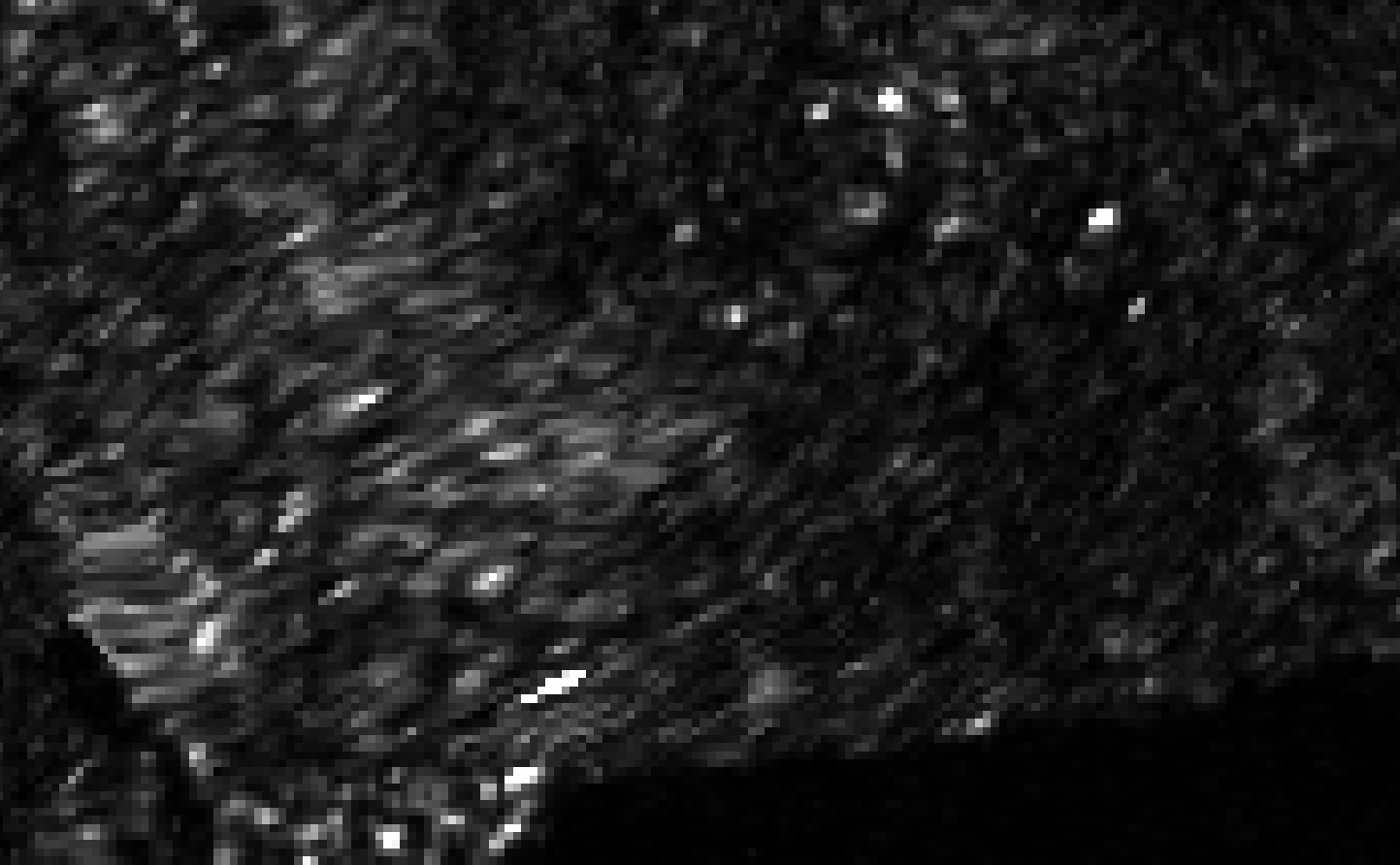
This is a quality issue of SNAP and should be addressed. The processing results of individually and assembled scenes should be comparable.