Dear all,
I want to do the pre-processing for polarization decomposition using the S-1 SLC data, but the data volume is very large and memory demanding ,so does anyone have a easy way to get the desired subset from S-1 SLC data. I am looking forward for your detailed steps.
Best regards.
you can use TOPS Split to select only parts of the image first.
Another way to reduce memory use is to extract the files before using them in SNAP:
Please see here:
thanks a lot, I will have a try
Dear @ABraun
I am using SNAP V8, which has become very slow recently. I have tried to reproject a single tile of Sentinel 2 data and it took around 3 hours to process. The size of the processed data was 17 GB. Earlier the size of the processed data never exceeded 1 or 2 GB.
I have reinstalled the software several times and also updated my system BIOS and other drivers just a few days back but the problem remains. I am unable to understand what reasons could be behind this issue.
Please assist me to solve the issue.
this is probably not related to the version, but most likely to the “reproject tie-point grids” option which you can deactivate to reduce the size of the output data.
Thank you for your reply @ABraun
As per your suggestion, I have deactivated the “reproject tie-point grids” and then reprojected the data but I could not find any differences. This issue is not only occurring in the reprojection tool even in the case of resampling the data the same problem is occurring. Today I also have tried to resample the same data and the processed data size was 16.5 GB. Please help
can you maybe check the products in your file explorer and compare where exactly the sizes differ so much? Are there more raster products inside or do the raster bands have larger sizes? Did you select the same output format? Maybe your data was integer before and now is stored as float.
This could have so many reasons…
Sorry for the late reply @ABraun
Yes, I have 10 bands inside the raster product. This issue may be caused by the larger size of the input raster.
I have another small query, I have performed RF classification using the raster data that contains 29 bands (20 GLCM, 6 PCA, and 3 backscatter). It has been 12 hours, still, the processing window is showing 1 % of data have been processed. Is it normal?? In general, how much time SNAP required for classification?
That means the rasters are now larger? Can you please name the size and file format of a raster before and after reprojection?
There is no general answer, because it depends on:
- the number of input features (29 rasters in your case)
- the size of input features
- the number and size of training polygons
- the number of trees (10 by default)
- specifications of your machine (RAM, reading and writing speed, processor)
I would give it some more time. The fact that it is stuck at 1% indicates that the process is still extracting the values from the 29 features under the training samples. Maybe you used too many polygons?
The raw data was 950 MB, after performing resampling and band-subset the data size was increased to 16.5GB. After that, the reprojection was applied and the data size was 17 GB. The file format was the same (SNAP default format) before and after reprojection.
What do you suggest for the RF classification…
Do I have to wait for some more time?
Sentinel-2 data is stored as integers in various resolutions. If you resample all of them to 10m (including the many quality indicators), it’s not surprising to me that the data becomes so large. Which operator did you use for resampling? Maybe you used a different one earlier.
The same applies for the RF classifier. Please make sure you only select the multispectral bands as inputs for the classification (12 bands starting with B) and not all other bands contained in the stack. Especially Sentinel-2 has many quality indicators on clouds, reflectance etc. I thinkt these are the reason for both of your problems.
In my case, Sentinel-2 data are stored as float, and resampling was done in SNAP only.
I have selected 10 bands (B2 to B8A, and B11, B12) from Sentinel 2B and then PCA was performed on the 10 selected bands. Six PCA outputs were stacked with GLCM and Backscatter obtained from Sentinel-1A. The stacked data was used for RF classification. As you can see in the attachment, I have selected all 29 bands of stacked data. Do I have to select only the PCA (S-2B) bands from the list??

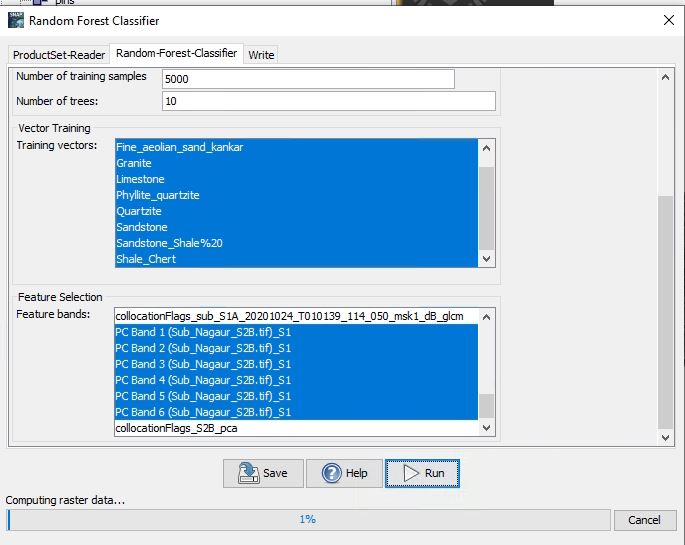
the message at the bottom of the SNAP window says “Extracting data…”
This means as long as it is stuck at 1% the values of all 29 bands are extracted below the polygons. I see that the purple ones have over 30 polygons while other classes are not visible at all or only as single polygons. Are you sure that you need all the purple training data? Seems a bit unbalanced to me.
Also, are you sure that all training data are represented by at least one polygon?
I have 9 major training classes except for those classes all other areas fall under one single class (the purple one). For that reason firstly I have selected training pixels for 9 different classes and the training pixel of the remaining one class (purple) was selected randomly from all over the area.
so why does the purple class have so much more polygons?
Because almost total study area (except other 9 class) falls under the single purple class.
if this class is homogenous, fewer polygons should be sufficient and speed up your processing. Statistics of these polygons will be merged for training purposes (average value) anyway.
Sorry for the late reply,
The class I’m talking about is a single class that covers more than 90% of the study area and includes different land cover features (like cropland, urban areas, bare surfaces, etc.). That is why I have created a large number of training polygons from different land cover features (like cropland, urban areas, bare surfaces, etc.) to put those classes into a single lithology class.
so why don’t you put these into different classes and merge them after the classificaiton process? I suppose this will give you higher accuracies than having one large “mix” class. The Random Forest classifier will always draw different subsets of samples so you will never get a fully representative training subset of such a class.
Ok, then I will do the same.