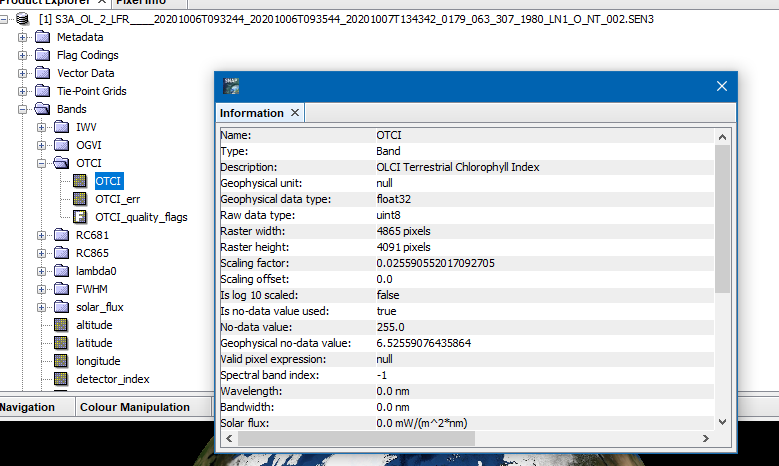
I am using the snappy python api to load S3 OLCI data, extract the OTCI band, subset to an area of interest, and export as a single-band GeoTIFF.
The code I am doing this with is below (with thanks to this forum for getting me this far). However, despite the readBand of the OTCI returning the expected values in the 0-6 range. The exported GeoTIFF has all values over the 0-256 range. Why is this behaviour occurring and what can I do to ensure that the exported GeoTIFF retains the original data format?
I have also tried the route of writing a new band to a new product using copied band data, however when I try this I get an RuntimeError: no matching Java method overloads found. There seemed to be no easy answer to why this should be the case and hence I persued the route above.
When using the band maths the scaling is applied and the geophysical values are written.
You could also switch to NetCDF-CF or ENVI format. These formats would work without the band maths operation.
@marpet you really are the best :D. Thank you for your swift reply. That makes perfect sense, I had not realized that there was an additional step going on under the hood.
I will stick with GeoTIFF for now as that makes sense for the next step of my pipeline (and is a temporary file anyway so storage is not so much of an issue). But good to know that NetCDF-CF is an option that would work here as well if that changes.
Just a bit background info. We could actually write the data scaled into the GeoTiff file right away.But the code originates from times where diskspace was valuable and geotiff wasn’t that widely used, at least in our community at that time. So we decided for the smaller file size. Changing this now could break existing processing chains.
Maybe we will tackle this in the future.
Interesting, thanks! Having now implemented it, I have switched to the final output of my workflow being a NetCDF for storage purposes, so much the same applies as in the past.
However, I have retained the GeoTIFF out of snappy in the intermediate step as I am doing some data modification (mosaic and nodata handling) with rasterio. I suspect that I could likely do said handling in snappy if I knew it better, but not that confident I could figure it out quickly. One for the future me to tackle…