I always get the RuntimeError: java.lang.OutOfMemoryError: Java heap space when processing S2 data. So I already changed it as you described it in Topic 1102. I changed jpyconfig.py and snappy.ini in C:\Users\Andreas Baumann\.snap\snap-python\snappy:
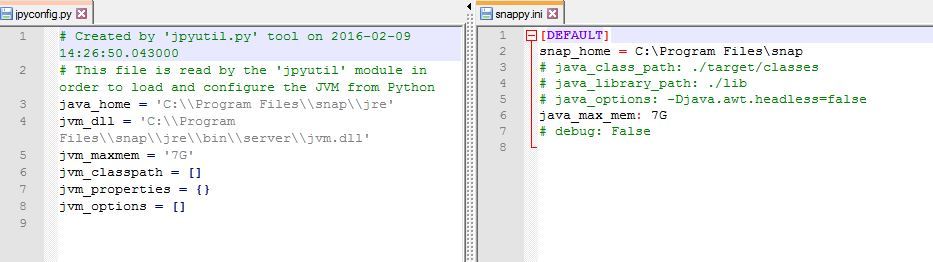
But it did not really work.