I am a new ESA Trainee and I would like to implement some of the processes of S2-tbx/sen2cor into a online platform. As a programming language I am going to use python. Are there beginner guides, handbooks or well documented scripts available?
You made already a good start.
Some more examples can be found in the snappy dir.
There is an examples and a tests directory. In those directories you will find more or less simple scripts.
Beside what you have already found there is no beginners guide or handbook. Sorry for disappointing you.
The developer guide, you found it already in the wiki, is still under construction.
However, feel free to ask questions here in the forum as much as you like.
Thank you @marpet, I found the examples you mentioned and they are really helpful. I costumized “snappy_subset.py” to run with “S-2” and added some new input arguments. It works well but there are two INFO message and especially the second one irritates me:
INFO: org.esa.s2tbx.dataio.s2.ortho.S2OrthoProduct10MReaderPlugIn: Building product reader 10M - EPSG:32632
INFO: org.esa.s2tbx.dataio.s2.l1c.L1cMetadata: Skipping tile S2A_OPER_MTD_L1C_TL_SGS__20160113T143043_A002922_T31TGJ.xml because it has crs EPSG:32631 instead of requested EPSG:32632
I saw it already when running the “snappy 1st contact” script with different S-2 datasets. When I open the “end” products in SNAP it does not look like any tile was not processed. Has this any impacts? If so, do I need to reproject everything before running any S-2 dataset to not get this message anymore?
As much as I saw it works fine. But I am curious about “setParameter(…)”. Is there a list or anything alike where I could see what kind of parameters are available and which ones are mandatory to run a operator? And also which values are valid (e.g. i used ‘nearest’ instead of ‘Nearest’ and got an error) for a certain parameter?
Thank you for your help and best regards from Frascati.
Andreas
The problem is that S2 data can cross several UTM zones. This is not yet well handled by SNAP and the S2 reader.
When you read a product you can also specify the product format.
ProductIO.readProduct(file, formatName)
This way you can force the S2 reader to open a certain UTM zone. For example
To get documentation about the operator the easiest way is to use the gpt command line tool
Call
gpt -h Reproject
And you will get the list of parameters and a description for each.
When you simply call
gpt -h
You will get a list of all available operators.
The way you call the operator is valid but you should call setParameterDefaultValues() after creating the operator. This will ensure that the default value is assigned to the parameters if there is any.
However, there is a more preferred way of calling an operator
Also I saw in a previous beam-forum (Link) that there was also a parameter “variables” to select the bands which should be processed. In SNAP it is mandatory to select them but I can not find it in “gpt -h Mosaic”. Did I oversee something?
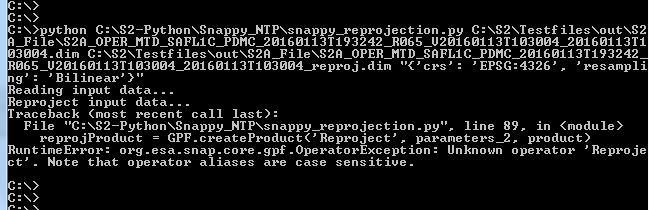
the exception message must be longer as just the one line you posted . It would be helpful to know this error message.
However, I think it complains about the missing variables definition what you already have assumed.
The variables are not directly listed in the parameters list when you call gpt -h Mosaic. The reason is that it is are more complex parameter and it cannot be specified on the command line. It can only be specified within a xml file or via the the API. The variables and the conditions are shown in the example xml on the command line when you type gpt -h Mosaic.
You can use it in your code as follows:
that is the thing: This is the whole error message! I may have fixed the code, but I get the Java-Out-of-Memory-Error when running two S-2 datasets. So I can not be sure. Will try to test it on the VM, as soon as I get to run it.
Good afternoon,
Again, I have a question regarding SNAPPY. I would like to compute a mosaic and would like to set the “northBound”, “southBound”,… automatically to the overall boundingbox of the input files. Is it possible to read them out of an input raster (e.g. GeoTiff, S2)? If so, how to do it?
I could not find something within the ProductIO.readProduct(…) . Did I miss something?
Secondly is it also possible to get the Pixelsize/GSD of a file, to set a appropriate pixelSizeX/pixelSizeY?
From these geo-positions you can retrieve lat and lon.
gp_lr.getLat()
gp_lr.getLon()
Compute the min and max for lat and lon and then you have the results.
When you have the lat and lon values you can compute the lat/lon width/height and divide it by the pixel width/height.
This way you get the pixelSizeX/Y
Thank you once again. I could successfully implement it.
But now I have two questions regarding this PixelSize and Mosaicing.
As you mentioned above I can read out the S2 data with their different UTM zones and afterward create a mosaic of both of them. Now I would like to keep the same resolution (e.g. 10,20 or 60m). I have a test file in the area of the Siachen Glacier (~36°N, India-Pakistan). If I did not make a huge mistake, then 10m in this latitude should be ~0.0001° (PixelSizeY, East-West) and ~0.00009° (PixelSizeX, North-South). But if I want to run the Mosaicing with such values I will receive an error RuntimeError: java.lang.RuntimeException: Cannot construct DataBuffer. . If I run the same script with 0.001° (~90m, which is also the minimum Value in SNAP) it works fine. Is there a reason why it is not possible to have a better resolution?
You can try to set the JVM memory.
Have a look into the snappy directory. There is a jpyconfig.py file. Change ‘jvm_maxmem = None’ to jvm_maxmem = 6G for example.