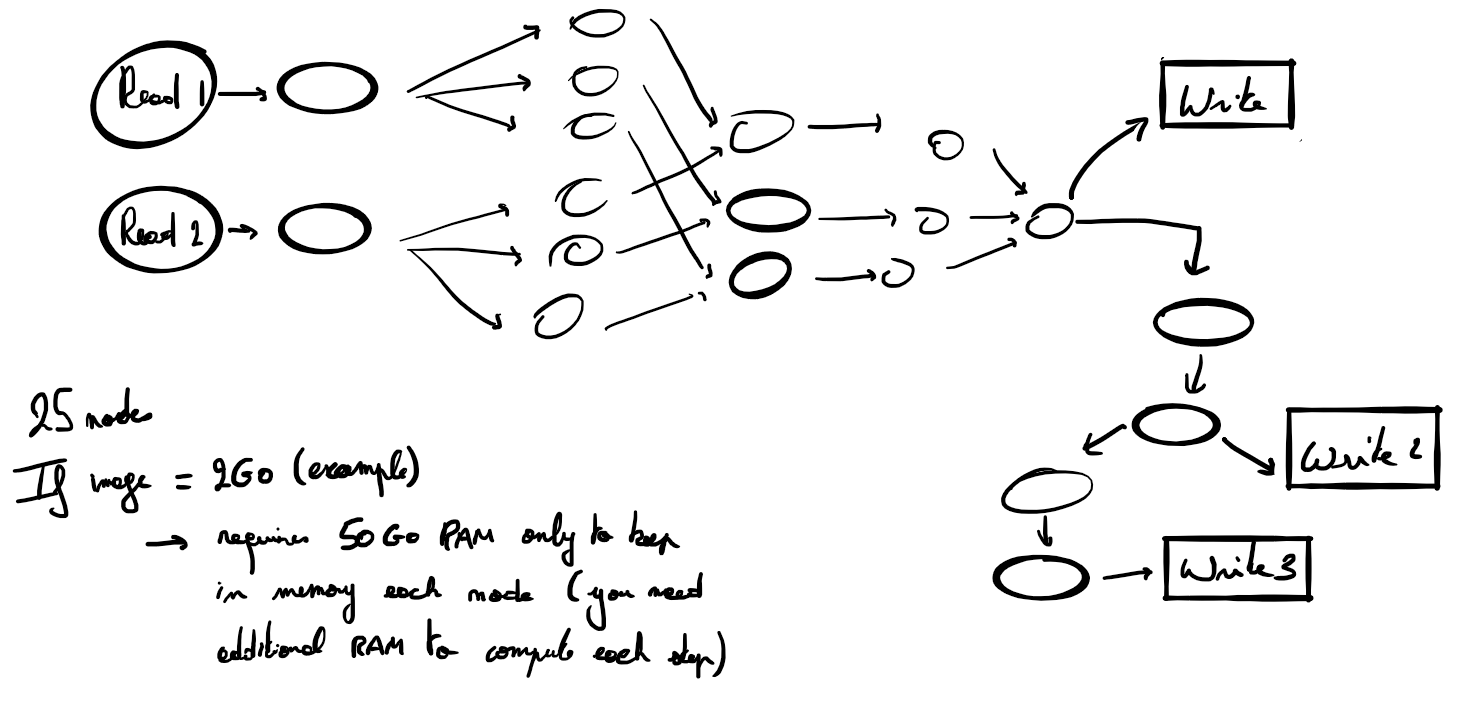
The issue with SNAP is that in computing such a graph is that it uses a crazy amount of RAM … for nothing. In fact, SNAP keeps in memory the results of each node.
In many cases, student wants to perform a simple processing chain. In theory, they could perfectly do it but the way SNAP manages the processing chain make it cumbersome. Then, their encounters problems even with their 16Go laptops.
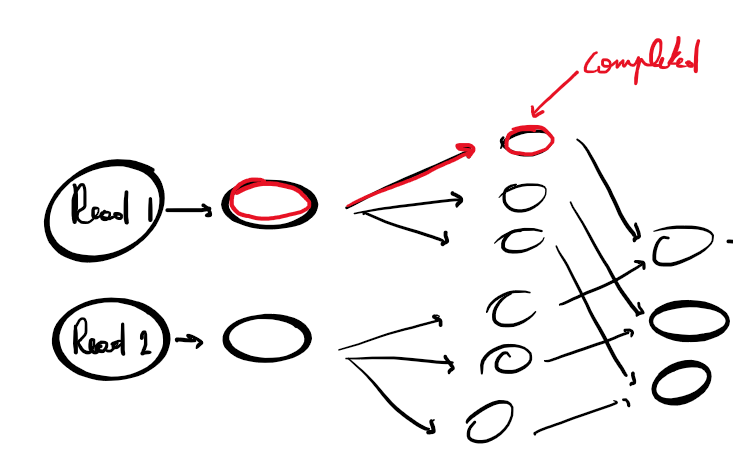
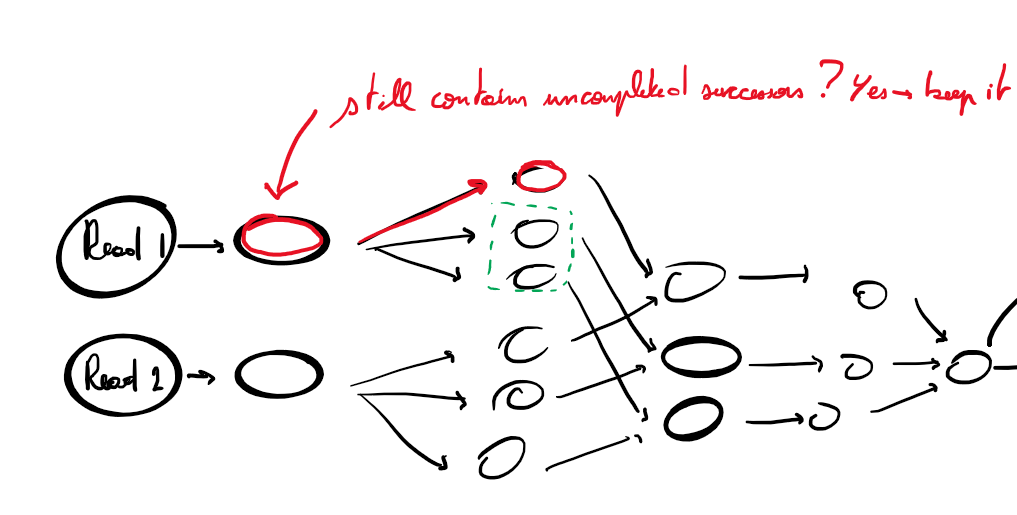
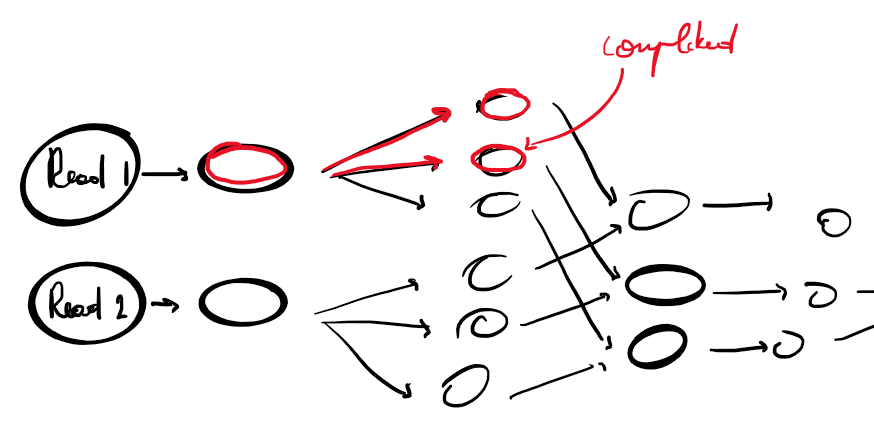
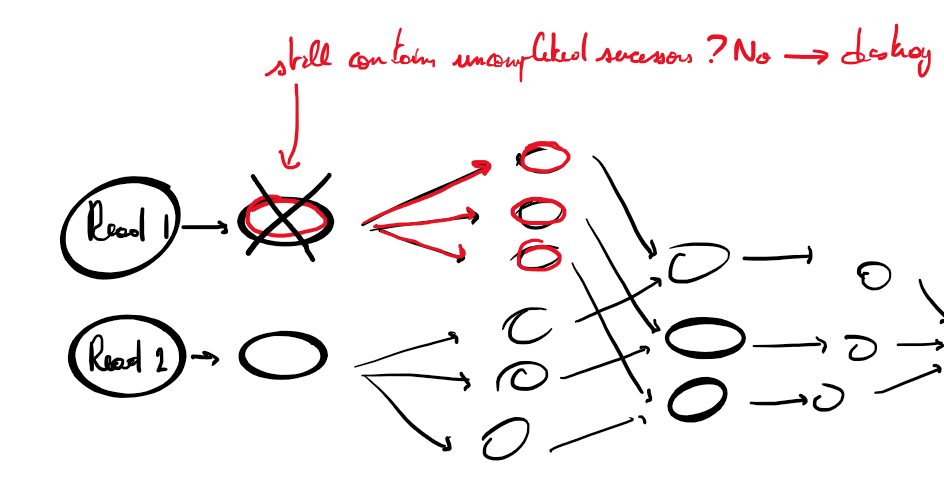
There is a simple way to prevent this issue. When a node is completed, you check if the predecessors still have successors that are not completed yet. If all sucessors are completed, then you can free the memory of the node. It exists different way to do this (graph theory).
If any question or if something is not clear, please ask
Thank you for your suggestion! SNAP has a pull-processing architecture where the reader starts “pulling” tiles through through the processing chain in a asynchronous multi-threaded manner. How does this affect your proposal?
Hi Quentin, thanks for the input. This is very welcome.
You are right. SNAP uses too much memory. Actually, the memory management should work as you say, but it doesn’t.
The main reason is that both cases, processing from the Desktop and from the command line are handled the same. In the desktop you don’t know which data will be necessary next and if you can throw it away. It is not deterministic. Because the processing order is defined by the user by panning in the image view.
Actually, data in memory should be replaced by new data when the limit is reached. This is similar to your approach. When once computed and not used anymore the data drops out of the cache. But this doesn’t work as expected. often the cache reaches its limit already, throws way data and then it needs to be recomputed. And this happens several times.
In SNAP 8 we added the so-called Tile Cache Operator.
Please see the Release notes. Release notes](SNAP 8.0 released)
More details about it’s usage is in the wiki: How to Use Tile Cache Operator to Improve Memory Consumption - SNAP - SNAP Wiki (atlassian.net)
For sure this is currently too complicated for an average user but we plan to integrate this into the graph execution. But we like to gain some more experience with it.
Thanks for your response. I now better understand the reasons why it is not so simple. Also, I totally missed the introduction of the Tile Cache Operator. I will definitely check that.
I think the Tile Cache operator is a temporary helper, hopefully we are able to evolve the architecture so that it will not longer be needed at some later point.
I find the discussion helpful. In practice, it can be more efficient to build a workflow in small sections so the intermediate results can be verified, but I end up using an edior to create the final graph. Many organizations provide user laptops with limited memory and mass storage, and use a remote data centre “cloud” for batch processing.
At my work in the 1990’s we used Stardent’s Application Visualization System (AVS) software. Since then there have been many attempts to provide graphical tools for processing workflows. So far all those I have encountered run into difficulties with the complexities of real-world workflows. One common issue is the need to introduce a few parameters at some intermediate step. With BEAM GPT (before parameter files were avaiIable) often ended up with a template for a large graph that gets tweaked (automatically) for each calculation.
It might be useful to have tools to first make small graphs into components that can be combined into a full workflow for use in batch processing.
If you are using a small system that may be the best you can do, but what could be useful is a tool to merge your smaller graphs into a graph for the complete workflow that would be run on a large system. So far I’ve done that manually with an editor.
I did the same preprocessing of the same SAR data one step at a time from UI in SNAP, then I did the same steps with graph builder, there is huge difference in time and memory that Graph Builder uses. I wonder why. In both case I am not writing the final product to the PC. Why would there be such difference?