Which one is better to merge S1+S2 images? Stack from radar tools or collocation from raster tools?
I have found that both methods allow me to create a single file with S1 and S2 data.
Now i’m wondering if there’s any difference and eventually which one is better for this purpose.
I think they exist in parallel because they were initially developed separately: Collocation was developed for optical data (source) while the stack tools were made for geocoded radar images.
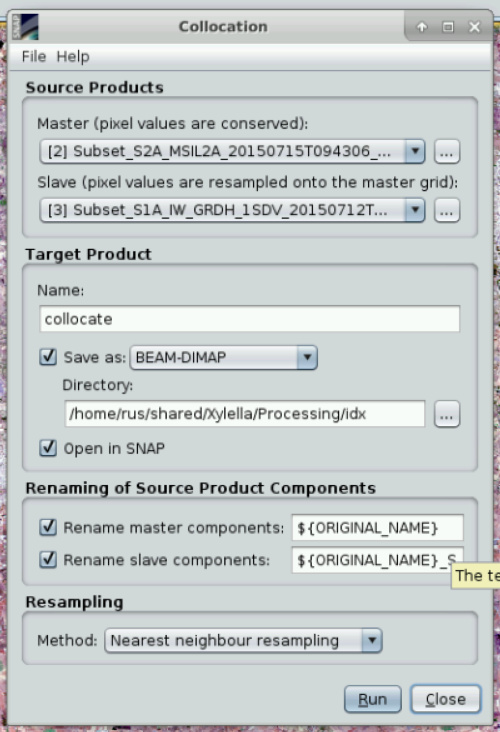
The settings are slightly different: Collocation features 5 different forms of pixel resampling and was originally designed to merge exactly two products. It was updated recently to feature multiple slave images. It also allows to define the output names in case you need to specify it.
Create Stack features 6 different forms of resampling and allows to use the orbit information of radar images as initial offset (instead of the geocoding of the image). This usually cannot be done with optical images.
Basically, if the geocoding of the S1 image is bad (e.g. because of inaccurate terrain correction) both methods will give you a bad result, because neither of them estimates the offset of the images to adjust the slaves against the master. This can only be achieved by coregistration.
Did you compute a stack with both methods? Maybe you can shortly report if you experience differences in the results.
Thanks a lot for your detailed explanation.
Yes, i did make a stack with both methods.
In the radar stack tool i used the geolocation instead of orbit to allign the images and in both cases i used nearest neighour for resampling (which resampling do you think is the most proper one?)
Apparently they both seem to work properly and the only difference i can find is exactly about the names since collocation has a different naming rules.
This feature can be useful in case to run a pretrained classifier on different images for example from different times and avoid the different names’ problem.
In the stack method is not possible to find the be optimal master image because i got an error about “centroids” so i suppose it simply uses the loading images’ order.
The resampling types depend a bit on what is needed. If you investigate fine features which might only be one or two pixels wide (e.g. roads), it is better to use nearest neighbor to preserve the characteristics of these pixels, because the others calculate averages based on different approaches.
Besides that, I think if both images are geocoded, there is no large difference, because none of the adjustments include rotation, stretching or resizing of the slave images. Accordingly, the different resampling types will largely be the same. They get more important when the spatial resolutions of the images differ strongly or the images are distorted.
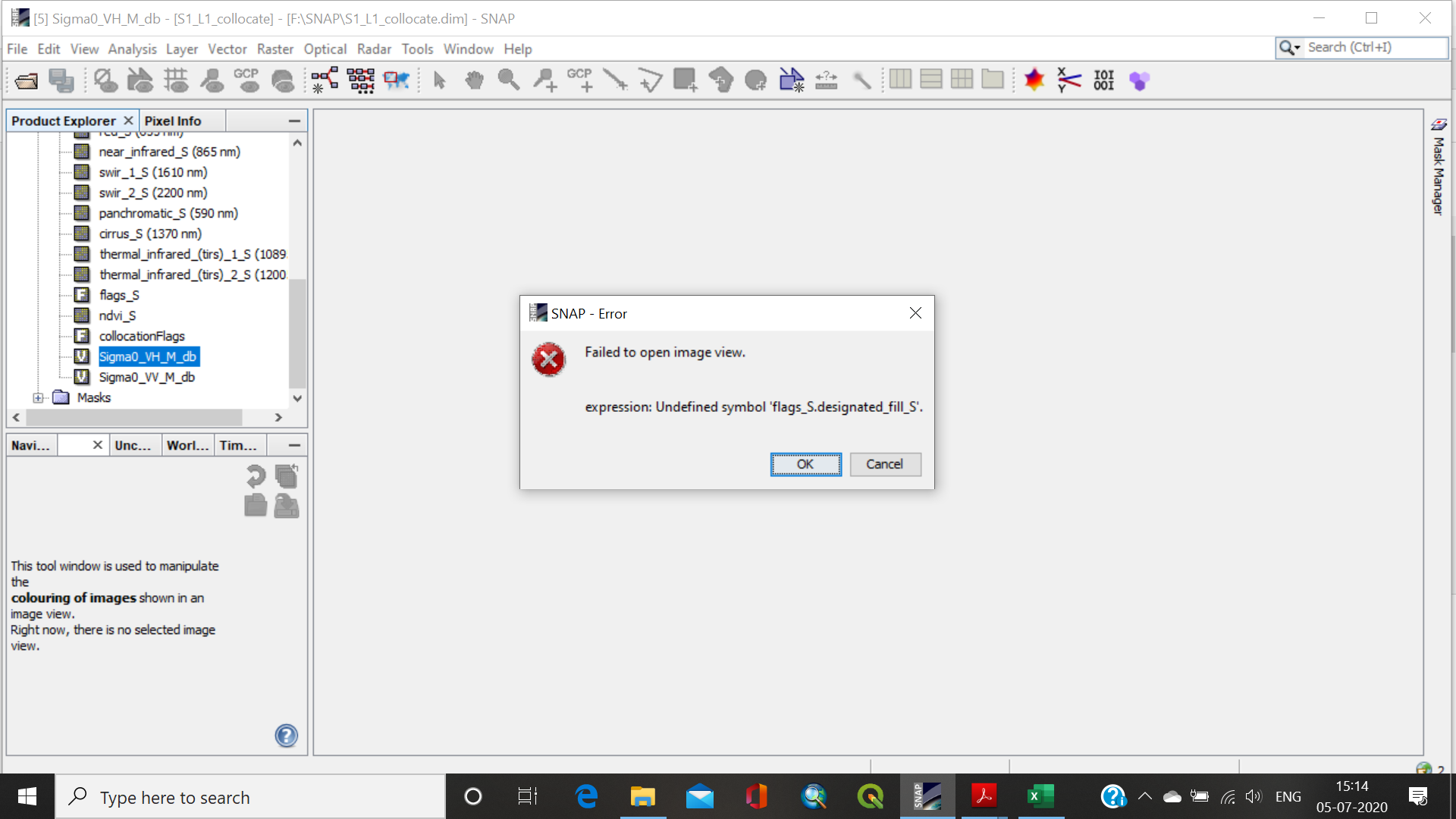
That’s a known issue. Unfortunately it exists already for quite some time. https://senbox.atlassian.net/browse/SNAP-662
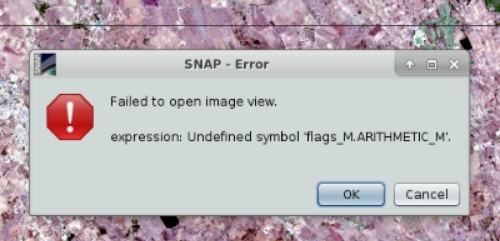
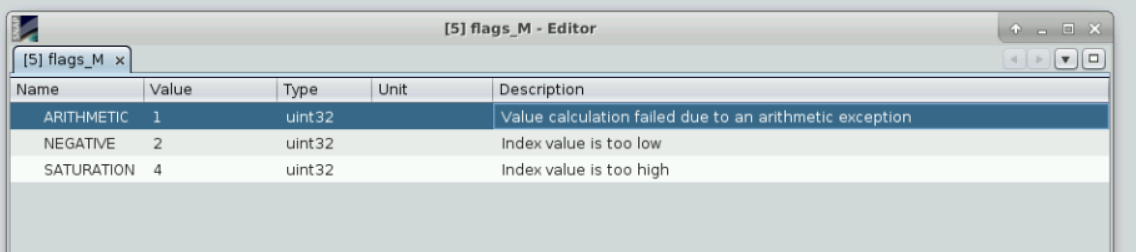
In your case @wincenzo, removing the trailing ‘_M’ from the valid-pixel expression should fix it.