I have a problem with processing S1 GRD products with SNAP. I believe there is an error in the way resampled DEM values are calculated in the Terrain-Flattening algorithm.
I did a simple test with the Terrain Flattening operator:
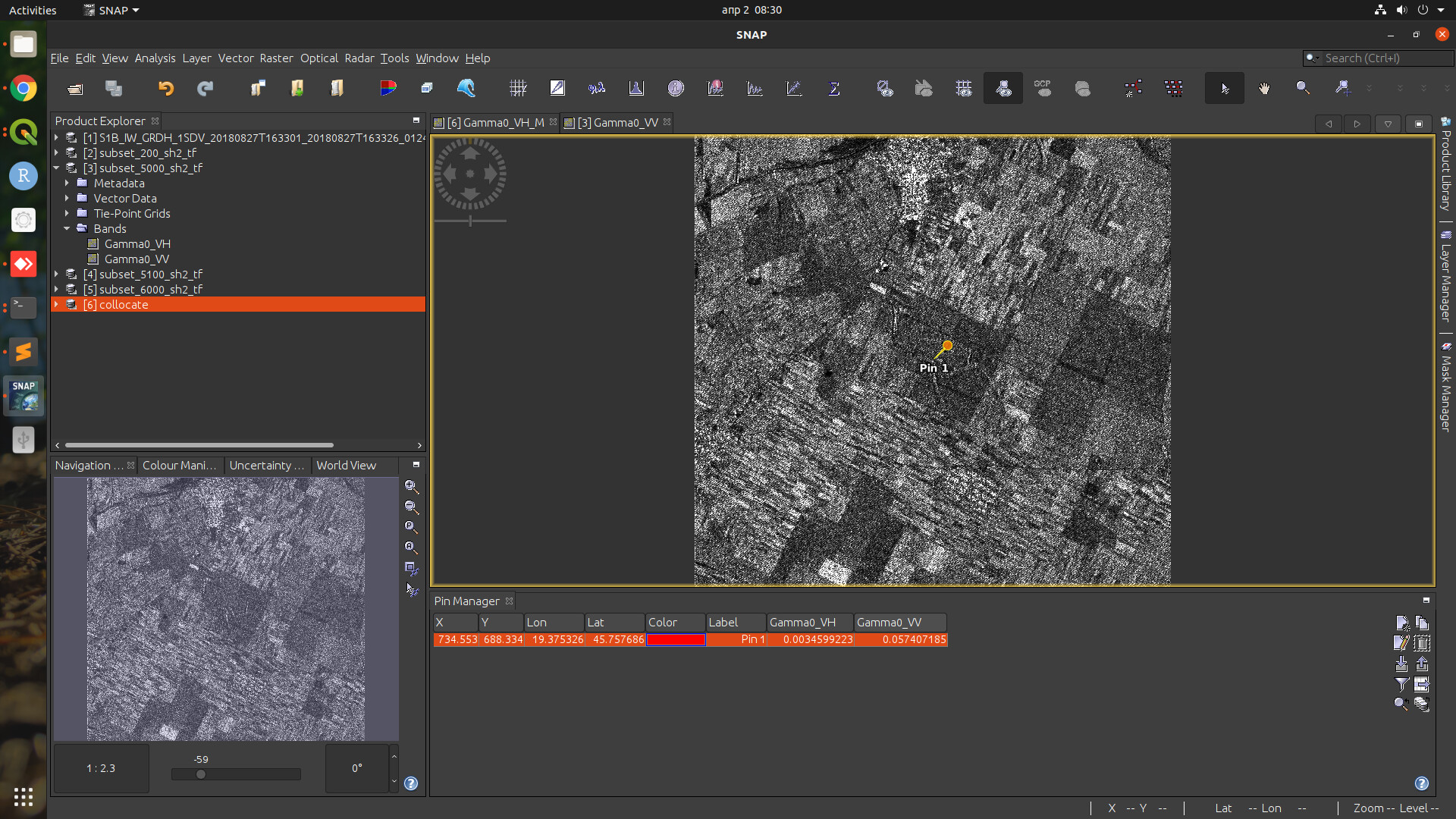
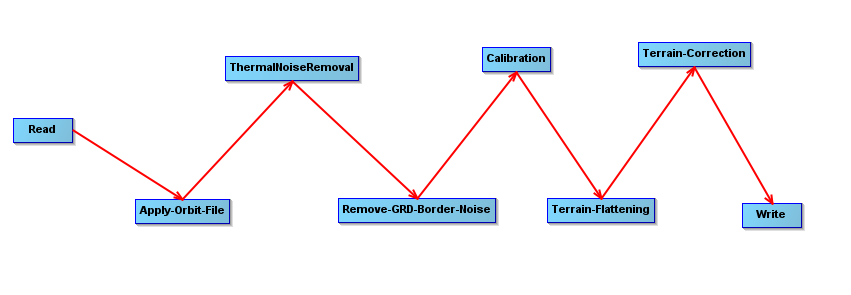
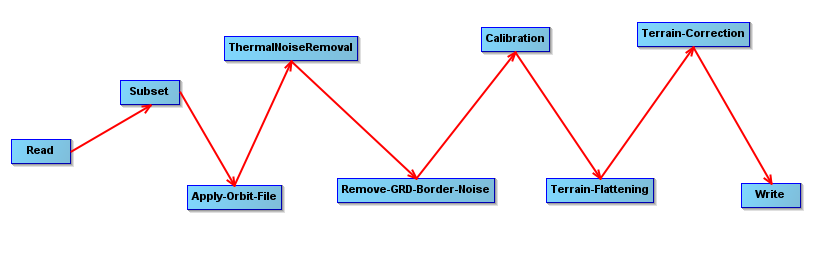
I preprocessed a whole S1 product, and some area inside that product with different bounding boxes around it (200m, 5 km, 5.1km, and 6km).
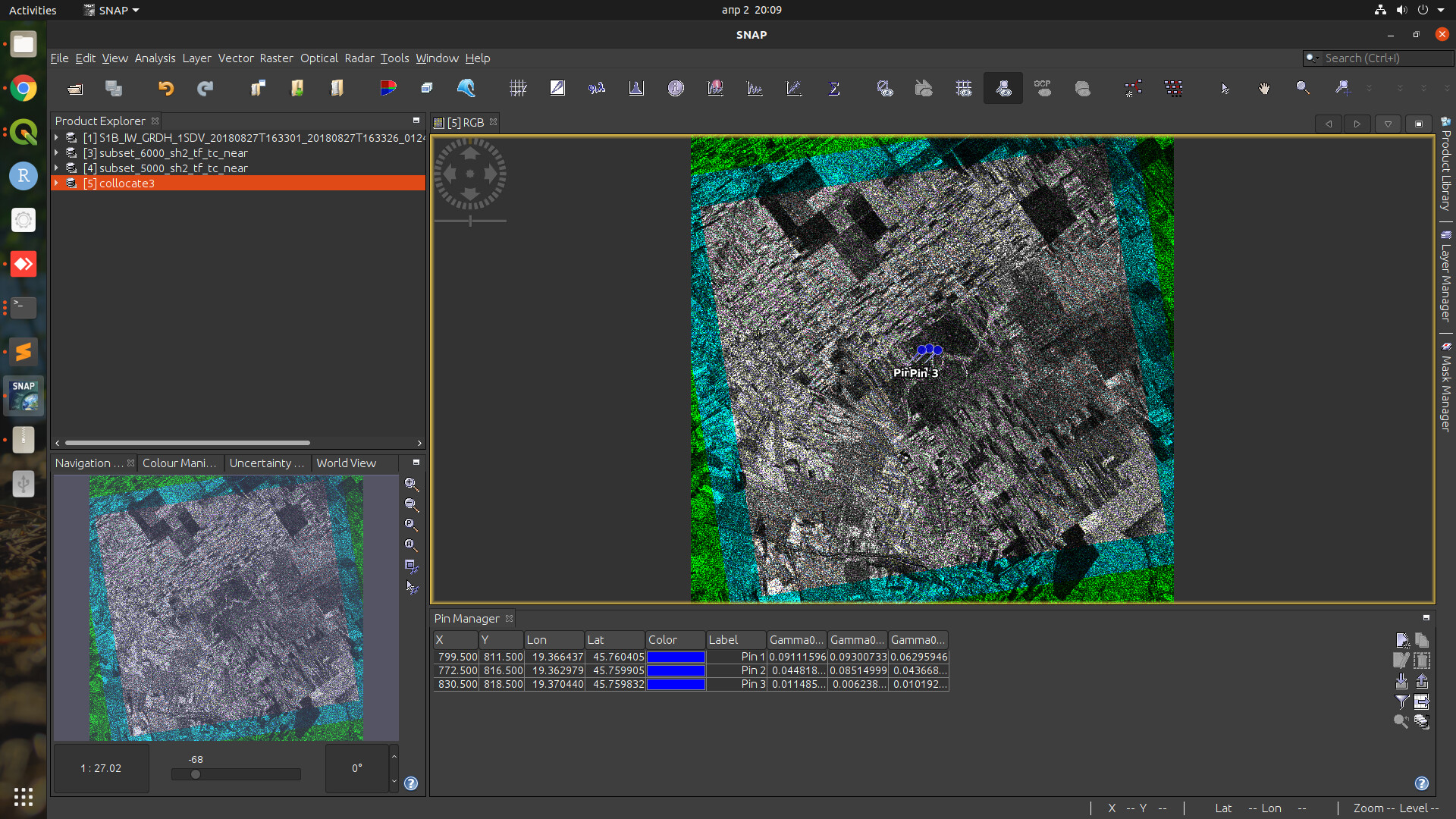
After that, I collocated these terrain-flattened products and checked the value of gamma0 for some pixels in the center of the selected area. To my surprise, the pixel values were all different (for the whole product and for the subsets with different boxes).
I know that Terrain-Flattening operator is based on this paper:
, and that it uses bilinear DEM resampling (which is the default for TF operator also). So my question is - how is it possible that the gamma values for pixels in the center of the area are affected by the size of the image processed (different bounding boxes)?
Between 5km and 6km bounding box, nothing has changed for that pixel - it still corresponds to one or more( or less) pixels in the DEM, the same DEM pixels (should) influence the sigma0 output for that pixel. But surely pixels far away from that location shouldn’t affect the output value.
Is there a bug in the Terrain-Flattening algorithm or am I missing something?
You can see in the first image how the pixel value for gamma0_VH “jumps” up and down as the image size is changed. These bbox sizes that I’ve chosen are not important, I have experimented with many more sizes, but the result is always different (sometimes more sometimes less).
This is also true for the Thermal Noise Removal operator, tested the same way as above:
I can provide the code if needed (I used python and gpt command line commands).
I tested this because I want to be able to get the same results for a pixel when I apply preprocessing for the whole S1 image and for some subset of that image.
what makes you sure that you are retrieving data from exactly the same pixel? Especially for slant range products of different extens there can be shifts at this coordinate precision. So if you want to go sure you can terrain correct all of them and then collocate (always with nearest neighbor resampling) and then select one pixel.
Why do you think there would be shifts if exactly the same product is used and I haven’t done any transformations, I’ve just taken a subset of the product? I am using ground range product for this testing: S1B_IW_GRDH_1SDV_20180827T163301_20180827T163326_012451_016F5C_7360
I have tried what you suggested (for two subsets), the result is still different. This is the code I’ve used for Terrain Correction (I have tried both nearest neighbour and the deafult-bilinear interpolation for radar image resampling):
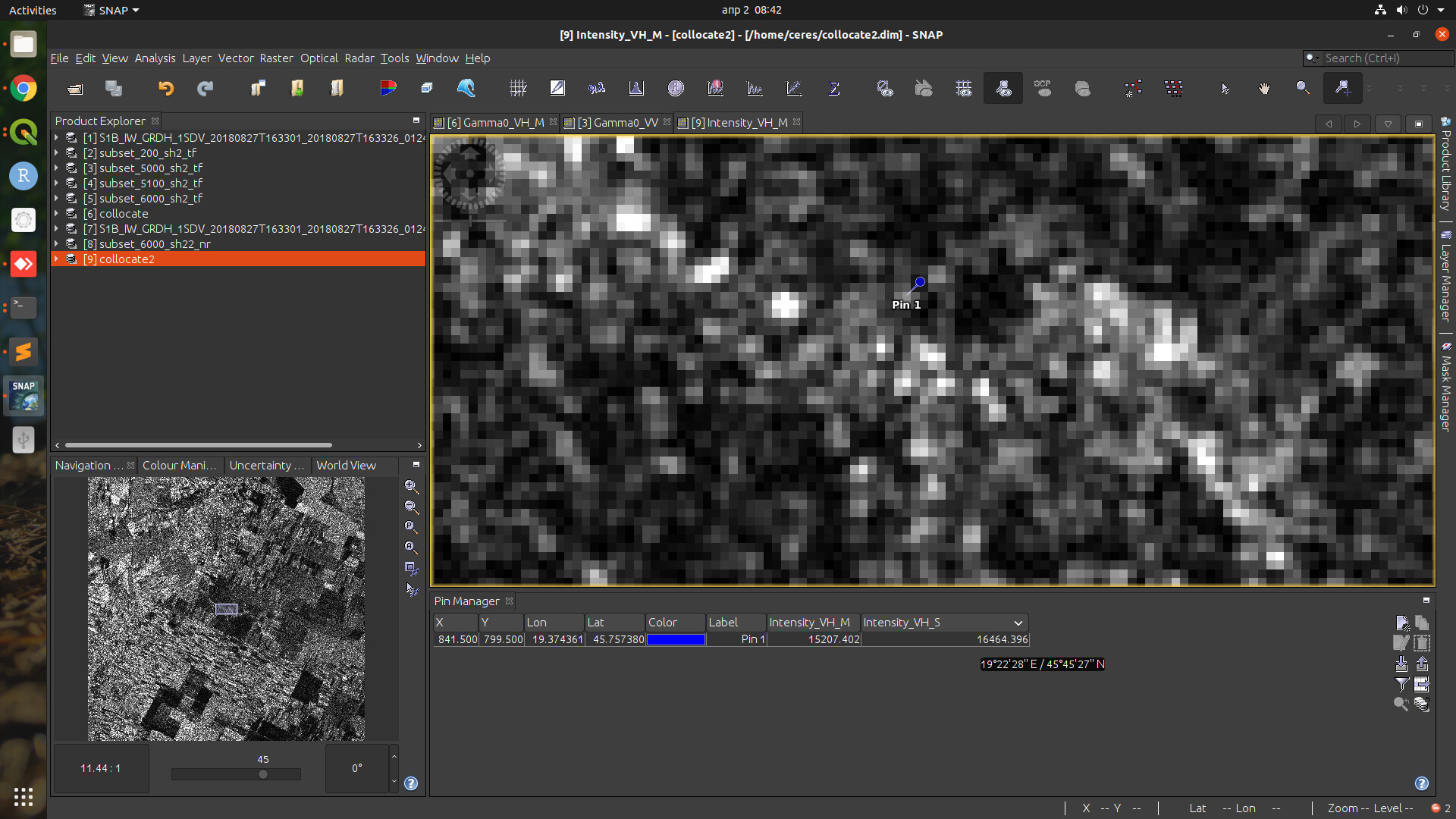
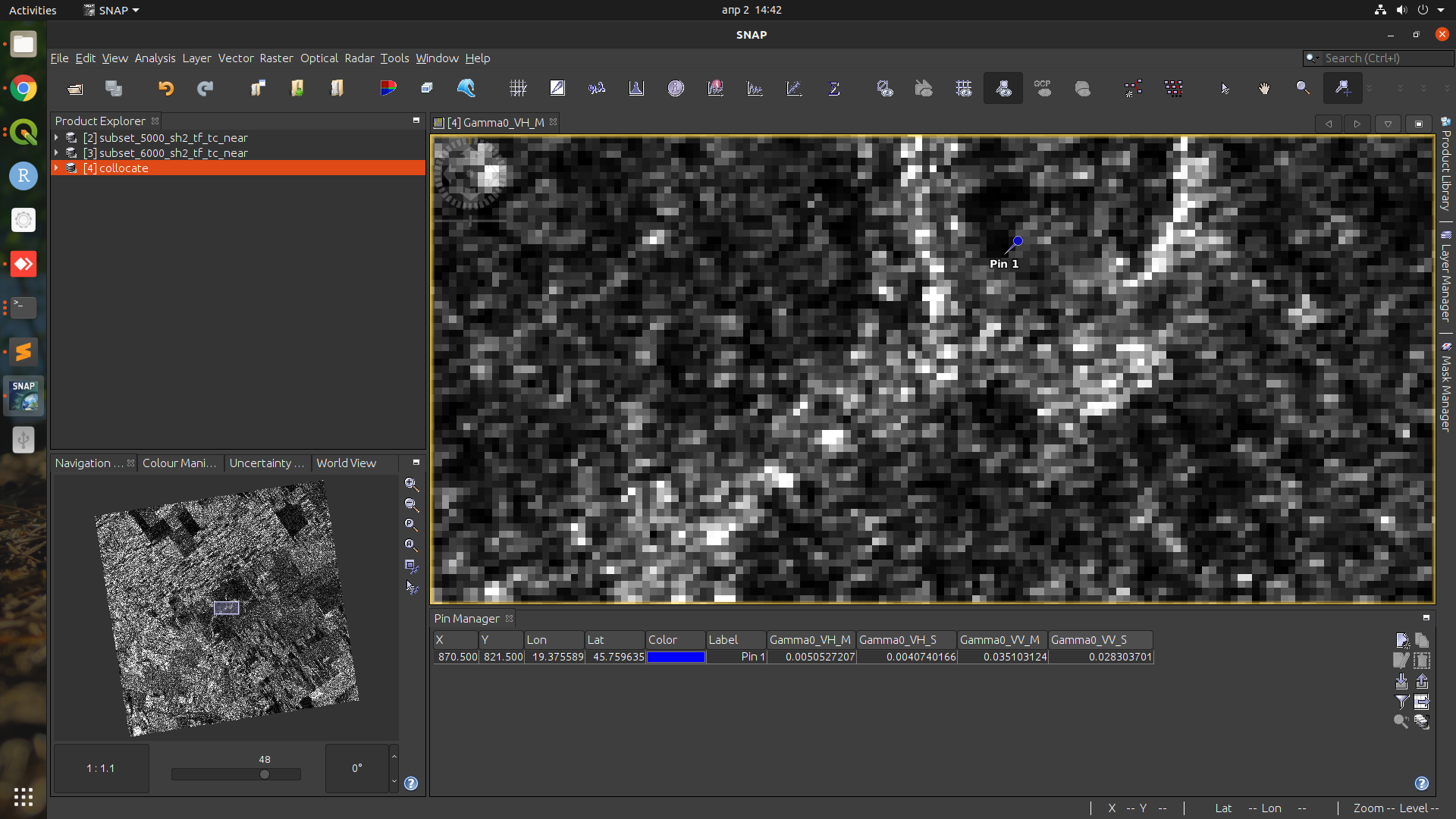
One more thing, only some tools are dependent of the input image size. For example Terrain Correction (Range Doppler, geometric correction) is returning the same pixel values. I tested this by creating subsets from Terrain Flattened product and then correcting them separately, and finally collocating them - the pixel values are the same for all rasters.
I did the same test with Terrain Flattening and Thermal Noise Removal operators (subsetting from original product and applying these operators to subsets) - and they yield different values for each pixel (as I mentioned above). So it seems that these two operators are dependent on the input image size. I think this shouldn’t be the case.
If I’m correct, this should be the code for these two operators:
I’m not great with Java, but I’ll try to look through the code. It would be nice is one of the developers who wrote the code could chime in on the disscussion (“Cecilia Wong, Jun Lu, Luis Veci”), or at least someone who is proficient in Java…
thank you, the fact that the RGB is grey in the overlapping area indicates that the products are well aligned.
Yet, there are smaller color differences between them which support your indication that the same product results in slightly different pixel values (still not sure if the extent is the reason).
Maybe @jun_lu and @lveci can comment here?
The only two things that cross my mind are that there are two pairs of class methods with the same name (lines 683 and 709, and lines 773 and 818), or that I’m not sure if the correct noise vectors are taken for each image row. I guess when retrieving noise vectors for scene subset, the image rows (and columns also) need to be assigned row numbers with respect to the whole scene.
But these are just wild guesses, I hope the developers will figure it out…
We have looked into the issue. Actually there are two issues here. Both the thermal noise removal operator and the terrain flattening operator have problem with subset. But the causes of the problem are different. For the thermal noise removal, the cause was that the subset was not properly handled. We have fixed the problem and it now produces identical result for both subset and the whole image.
For terrain flattening however, we believe that there could be some difference between the gamma0 output for a subset and the gamma0 output for the whole image. We know that the kernel of the algorithm is to simulate the projected illuminated area for each pixel and “normalize” beta0 using the simulated image. If, for different bounding boxes of the image, the simulated images are different, then the output gamma0 will be different. We believe this is the case. Given a bounding box of the image, we will first get the max and min of the latitude and longitude based on the geo-positions of the corner points. Then a latitude/longitude grid is created within the area bounded by latitude/longitude min/max in the map domain and the projected illuminate area is computed for each grid. The computed illuminate area is finally mapped back to the 4 pixels in the image domain using the bilinear distribution method. Here we can see that different bounding box will lead to different latitude/longitude grid, and hence different simulated result for each pixel. Now the question is how much difference is reasonable. We are currently reviewing the code to make sure there is no loose end.
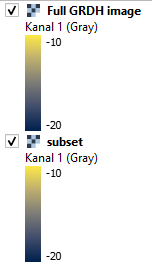
I just encountered the same, having different VH and VV backscatter values depending on using a subset or processing the full GRDH image. On the one hand, the backscatter values of the subset are around 1 dB lower across the whole subset area, on the other hand the simulated area values are around 0.5 higher in the subset across the whole area. These higher simulated area values in the subset might also be the reason for the lower backscatter values.
I applied the following processing steps with S1TBX 9.0.3 using the internal Copernicus 30 m DEM for terrain flattening and correction:
To make it more illustrative you find the VH polarisation with the same colour bar range (-20 to -10 dB) of the full GRDH and the subset image of S1A_IW_GRDH_1SDV_20170401T161416_20170401T161441_015953_01A4E4_0A10:
Would clipping the bounding box limits here to the input DEM grid - i.e, a multiple of the demResolution not help address the discrepancy to a large degree here:
By aligning it, the subset should still iterate over the same oversampled DEM locations? This should also help processing across different images to iterate over the same oversampled DEM locations? This jitter effect of the bounding boxes in our opinion definitely impacts results significantly in steep terrain.
What is the latest on this issue @jun_lu ? Any solution to it planned? As mentioned in the post above from the 23th of March, the differences in resulting backscatter values are quite substantial!
Hi,
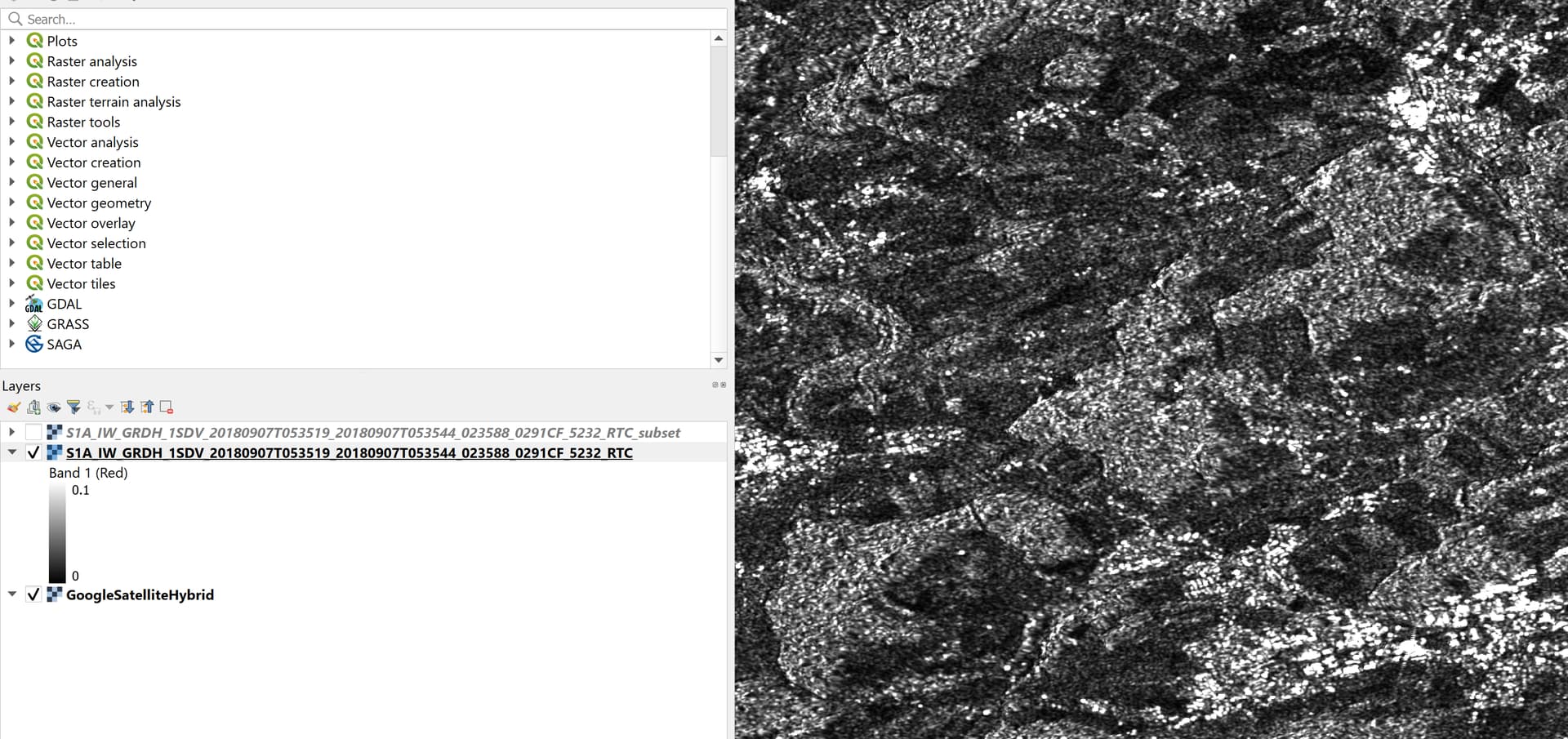
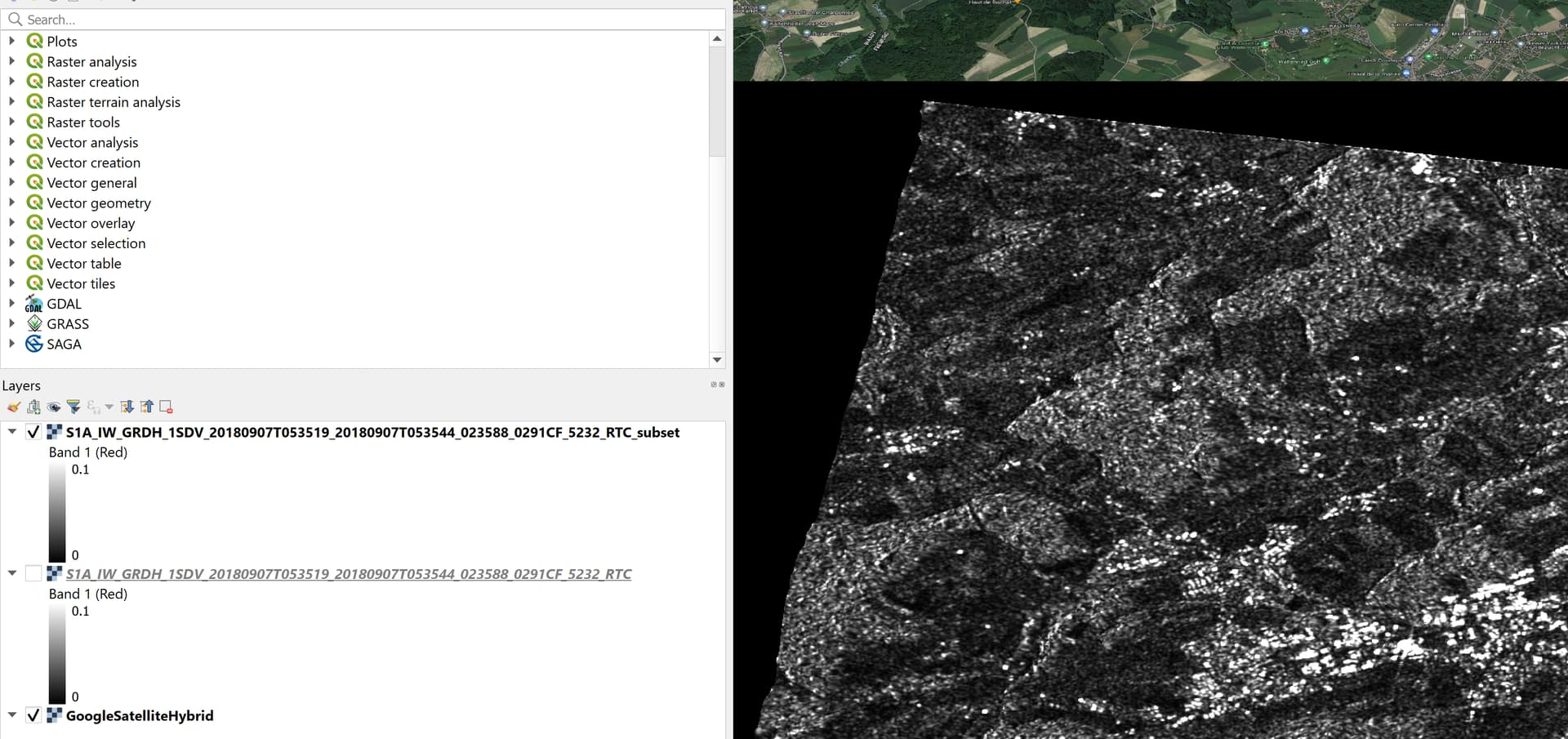
I am facing the same challenge in my research site! Also in my case the data value drops when creating the subset (I added two screenshots one using subset and one without). Would be great if we could solve this!