I have used Snap 8.0 to run a random forest (RF) classification.
In my testing, each input sample has 50 features.
When the RF Classification is finished, the output features of each sample are missed. It only kept 27 features.
To check this automatically ignored operation for features, we have tested and checked that the RF in SNAP can only receive a maximum of 20 features for each input sample.
Is it true for only 20 features? And how to process train lots of features (>20) by RF-SNAP?
Thanks.
For machine learning approaches such as RF, a feature is defined as an explanatory variable that is used to predict the target variable. In SNAP this means that all raster bands used for the training and prediction considered features.
Maybe you can clarify what is your input product (and the features it contains) and how you use training samples for the RF classifier. I’m not quite clear about how the input features are lost or discarded in your example. Maybe you can share screenshots to illustrate the problem.
Thanks for your kindly help and reply.
I want to use RF in Snap to accomplish the feature selection.
The input is 10000 features, where each feature vector has 50 variables.
When reviewing the generated features’ importance score, there are only 27 variables, and the other 23 variables are not listed.
However, if each input feature contains less than 20 variables for RF-SNap, we can obtain the importance scores of 20 variables.
Can RF-Snap only handle a feature with a maximum of 20 variables?

just to get this right: You use 1000 polygons and 50 raster bands for training?
How many trees did you compute? As you see in rank 27: the last feature already has an importance of 0.0. So anything beyond that is also 0.0 - I guess that is why the remaining features are not listed.
Thanks for your help.
There are 10,000 polygons and 50 raster bands for RF training, and the number of trees is set to 500. and It seems that variables with 0.0 importance score are not listed.
To achieve the feature selection, we have tested lots of times with 10,000 polygons and 50 raster bands. However, the final output variables are different after each RF training. Thus, I cannot obtain stable and useful variables by RF-SNAP.
Results on feature importance score from two experiments are shown below, where the left 24 variables and 26 variables are different.
Can I have a chance to output all the variables by RF-SNAP even though the importance score is 0?
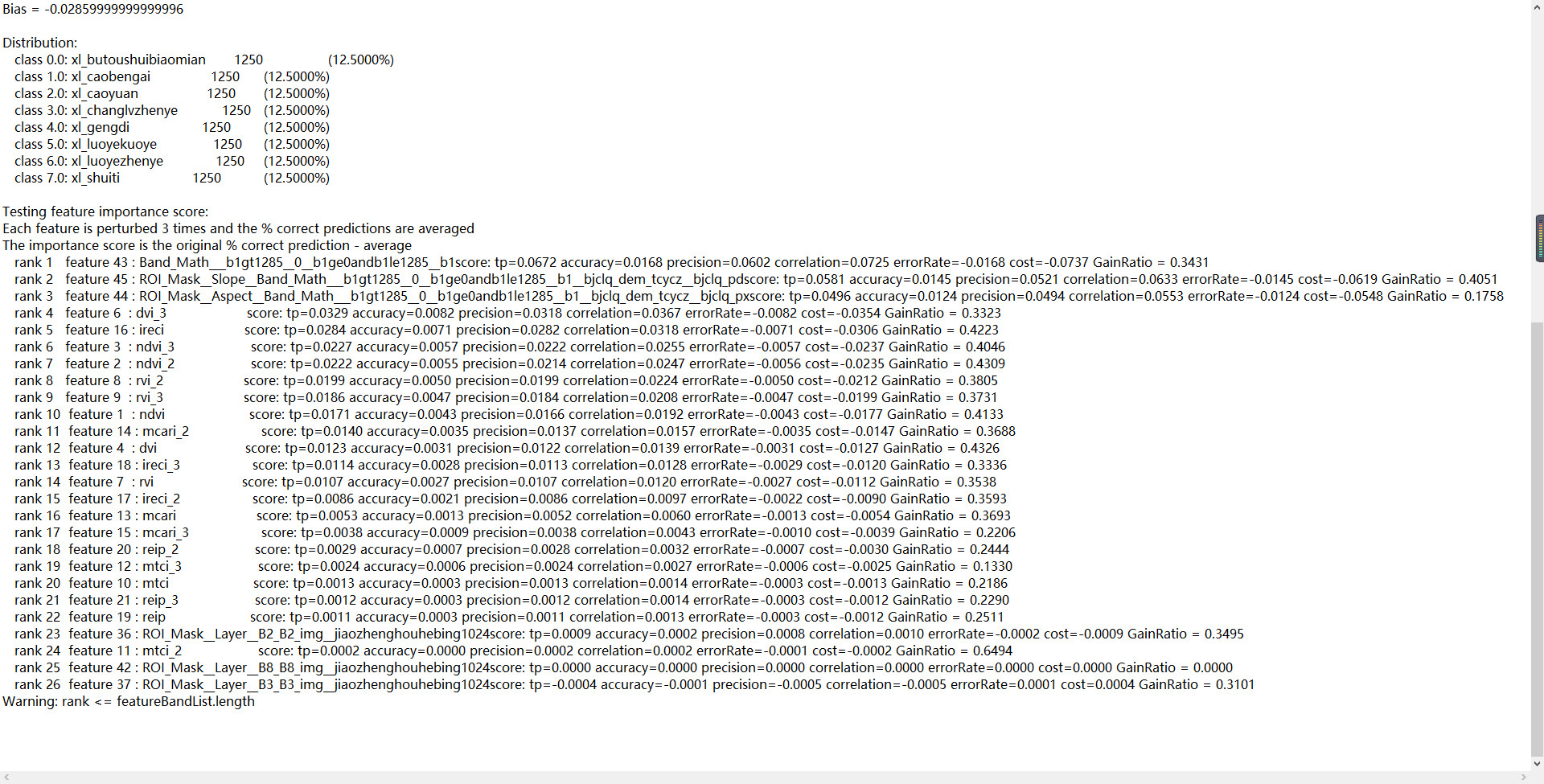

I see the problem that the list is not complete, but I don’t understand why this is important.
Random Forest classifiers are based on multiple interations of classification trees, each with a random subset of the input features (500 trees based on 7 randomly selected out of the 50 you used as input). Within these trees, only a random fraction of the 10000 polygons is used. This double random component helps to make the tree robust towards outliers in the training data and also to systematically find the features which are most helpful for the classification.
So it is not surprising that the feature ranking of two experiments are different (but quite similar).
So as you know the entire list of input features, and you know that the remaining features have 0.0 importance, why would you need to have a complete list displayed by SNAP?
Also, in terms of feature selection, the idea of the RF classifier is to systematically identify the most contributing variables and use them for the prediction.
If your aim is only the ranking of features, I rather recommend to extact the raster values under the training samples to a table and have the feature ranking done in a more specialized environment, such as scikit-learn or orange. Especially if you need repeatable results, the feature ranking within a random forest is not the best choice.
Thanks for your kindly help with my problem.
The reason to obtain all variables is that I hope to view all the importance scores and judge their importance. And now I have known that the missed variables have an importance score of 0.
In addition, I have also understood that RF can not achieve the same variables between different testing, and now I will try other classification methods.
Thanks and regards.
Then I recommend a more specialized algorithm. Random Forest ranks the features based on how strong each were used in the construction of the (n=500) trees. But this is rather an estimate and there are better ways to assess the feature scores.