Thanks for the suggestion. I tried that, but for_collocation is a python list and I get this error when I try to pass it into the HashMap,
"cannot convert a Python 'list' to a Java 'java.lang.Object'"
I’ve found a Java array example and tried this:
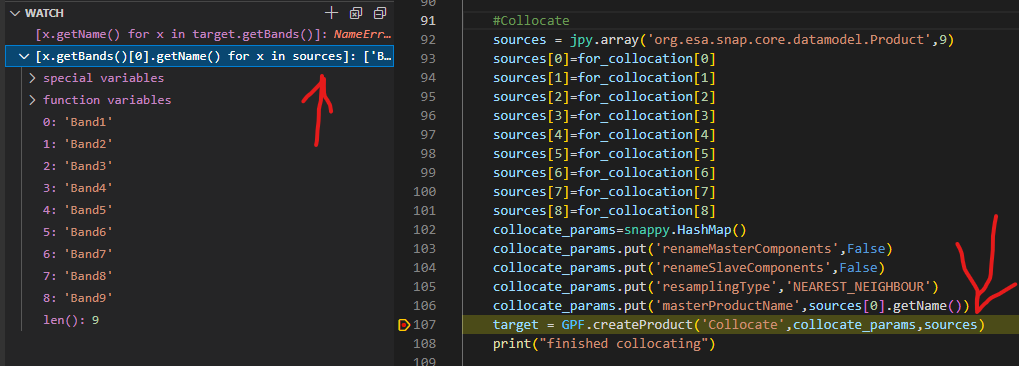
collocate_sources=snappy.HashMap()
collocate_sources.put('masterProduct', for_collocation[0])
slaves = jpy.array('org.esa.snap.core.datamodel.Product',8)
slaves[0]=for_collocation[1]
slaves[1]=for_collocation[2]
slaves[2]=for_collocation[3]
slaves[3]=for_collocation[4]
slaves[4]=for_collocation[5]
slaves[5]=for_collocation[6]
slaves[6]=for_collocation[7]
slaves[7]=for_collocation[8]
collocate_sources.put('sourceProducts', slaves)
collocate_params=snappy.HashMap()
collocate_params.put('renameMasterComponents',False)
collocate_params.put('renameSlaveComponents',False)
collocate_params.put('resamplingType','NEAREST_NEIGHBOR')
collocate_params.put('masterProductName',for_collocation[0].getName())
target = GPF.createProduct('Collocate',collocate_params,collocate_sources)
But then when the tool is run I get a java.lang.ClassCastException,
class [Lorg.esa.snap.core.datamodel.Product; cannot be cast to class org.esa.snap.core.datamodel.Product (they are in unnamed module of loader 'app')
I know that my product is correct by debugging,
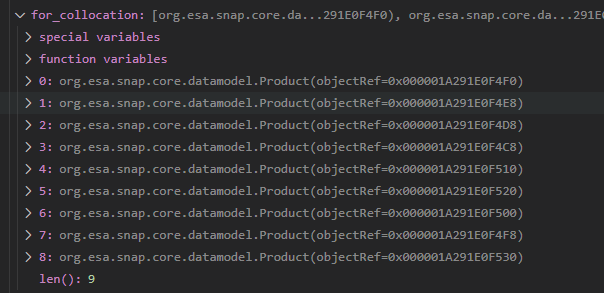
I think I know that ‘org.esa.snap.core.datamodel.Product’ is the right type to pass the java array, since it’s what I see when I look at the Java source code here.
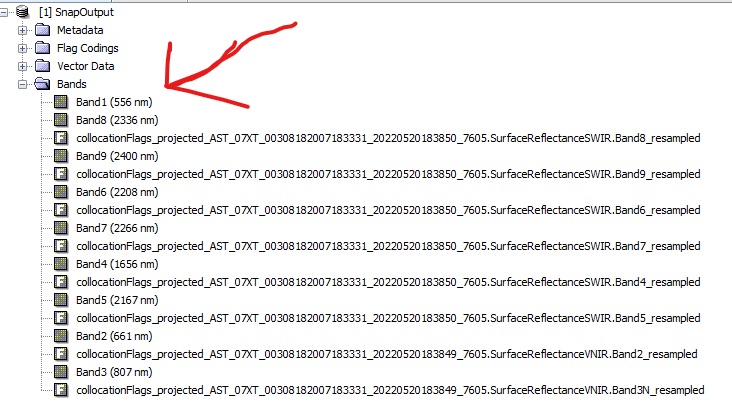
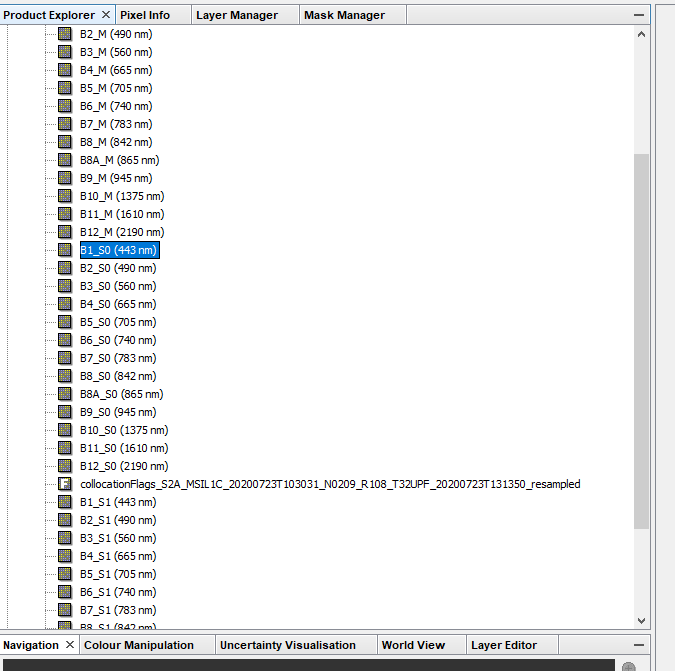
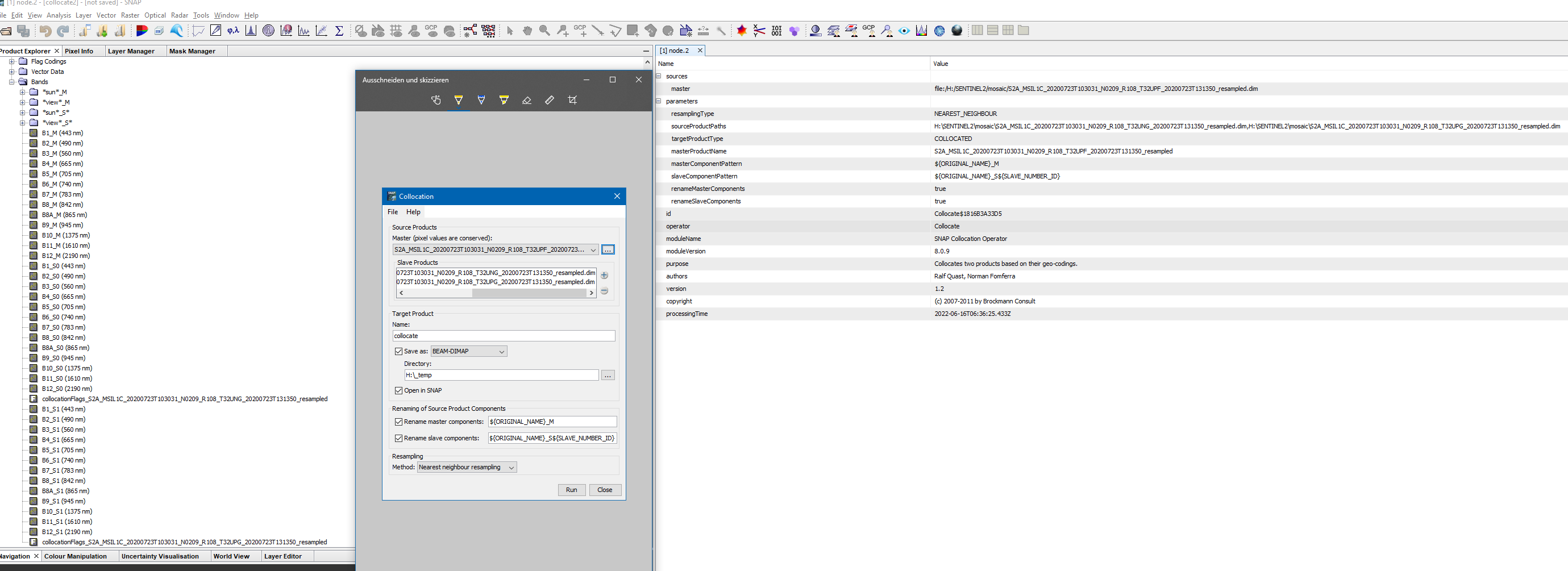
Am I barking up the wrong tree? I see now that GPT says ‘collocate’ is only for “two products based on their geo-codings”. Alternatively the ‘createstack’ tool “collocates two or more products based on their geo-codings.” The example I see here, from @janardanroy, seems to iteratively run the ‘createstack’ tool one at a time. When I run ‘collocate’ in SNAP the output is a single product with each slave as a band. How can I accomplish that with these tools? I’m just trying to re-create that output with Python. Do I need to collect the outputs of each iteration of ‘createstack’ and then run ‘bandmerge’? But then that leads me to a follow up question, the input for ‘bandmerge’ is string,string,string,…, how do I create that in Python?