Dear all
I am working with snappy and tried to do below steps in it over one example of GRD data:
Subset
Apply orbit removal
Thermal noise removal
Calibration to beta
Speckle filtering
Radiometric terrain flattering
Terrain correction
Convert to db
In subset, I used:
def do_subset(source, wkt):
print('\tSubsetting...')
parameters = HashMap()
geom = WKTReader().read(wkt)
parameters.put('copyMetadata', True)
parameters.put('geoRegion',geom)
output = GPF.createProduct('Subset', parameters, source)
return output
and then,
## well-known-text (WKT) file for subsetting (can be obtained from SNAP by drawing a polygon)
LONMIN=str(28.329)
LATMIN=str(65.336)
LONMAX=str(29.264)
LATMAX=str(65.841)
wkt='POLYGON(('+LONMIN+' '+LATMIN+','+LONMAX+' '+LATMIN+','+LONMAX+' '+LATMAX+','+LONMIN+' '+LATMAX+','+LONMIN+' '+LATMIN+'))'
Then I did same steps in SNAP software because I wanted to compare both results.
I exactly used same geo information in SNAP software. I mean in subset from raster tool:
North latitude bound: 65.336
West longitude bound: 28.329
South latitude bound: 65.841
East longitude bound: 29.264
But I do not know why my result from SNAP are smaller than snappy. Please look at below images in SNAP (figure 1) and also QGIS (figure 2) that I put both. I would be thankful, if someone can help me.
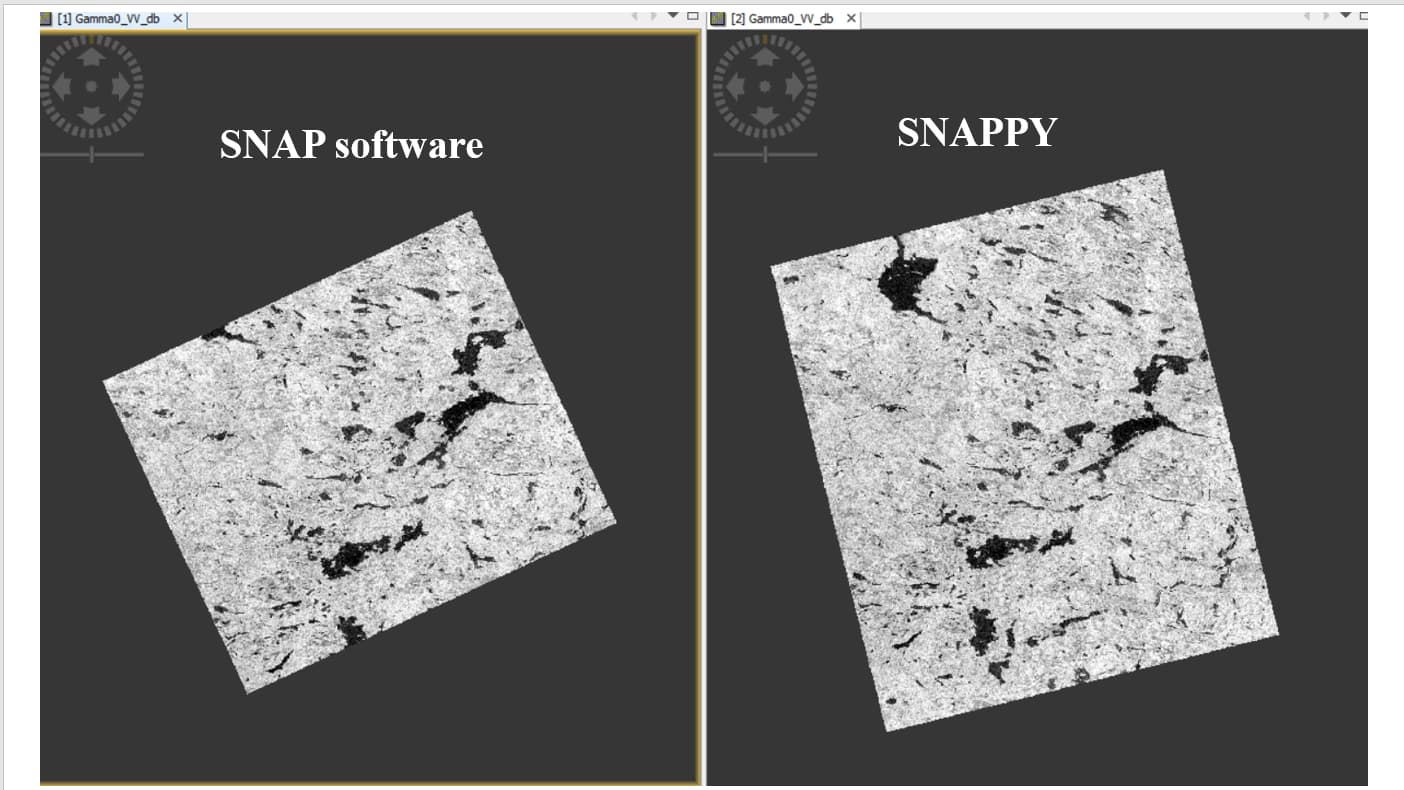
Figure1.

Figure 2.