sorry for the questions , but does wyx means ? 
just a spelling error - *why not 
hehe sorry!!
i have tried filtering the original callibrated image. I considered the image improved a lot.
On the other hand with the texture images i have seen that the filtering does not bring much . I actually like more the image without filtering. my questions is if there is a problem if I use the intensities with filtering and the textures without filtering?
no. You can consider calibrating before calculating the textures.
I have calibrated before . I mean can I use these 2 datasets together?
- original --> callibrated -> filtering --> terrain correction
- original --> callibrated -> glcm --> terrain correction
or should I do :
- original --> callibrated -> filtering --> terrain correction
- original --> callibrated -> glcm --> filtering – > terrain correction
Sorry for all the asking … And thnk you for all your attention
1 Like
sounds totally legit to me.
1 Like
Hi. I have looked at your paper in the link above. How did you compute the feature importance of the prediction layers?
I computed my rasters in Python using the scikit-learn module. But SNAP should be able to do the same.
1 Like
Thanks. Any idea which module in SNAP can do that?
as stated in the other thread, the Random Forest module has a built-in evaluation.
I just tested it with a multi-spectral dataset and received the following:
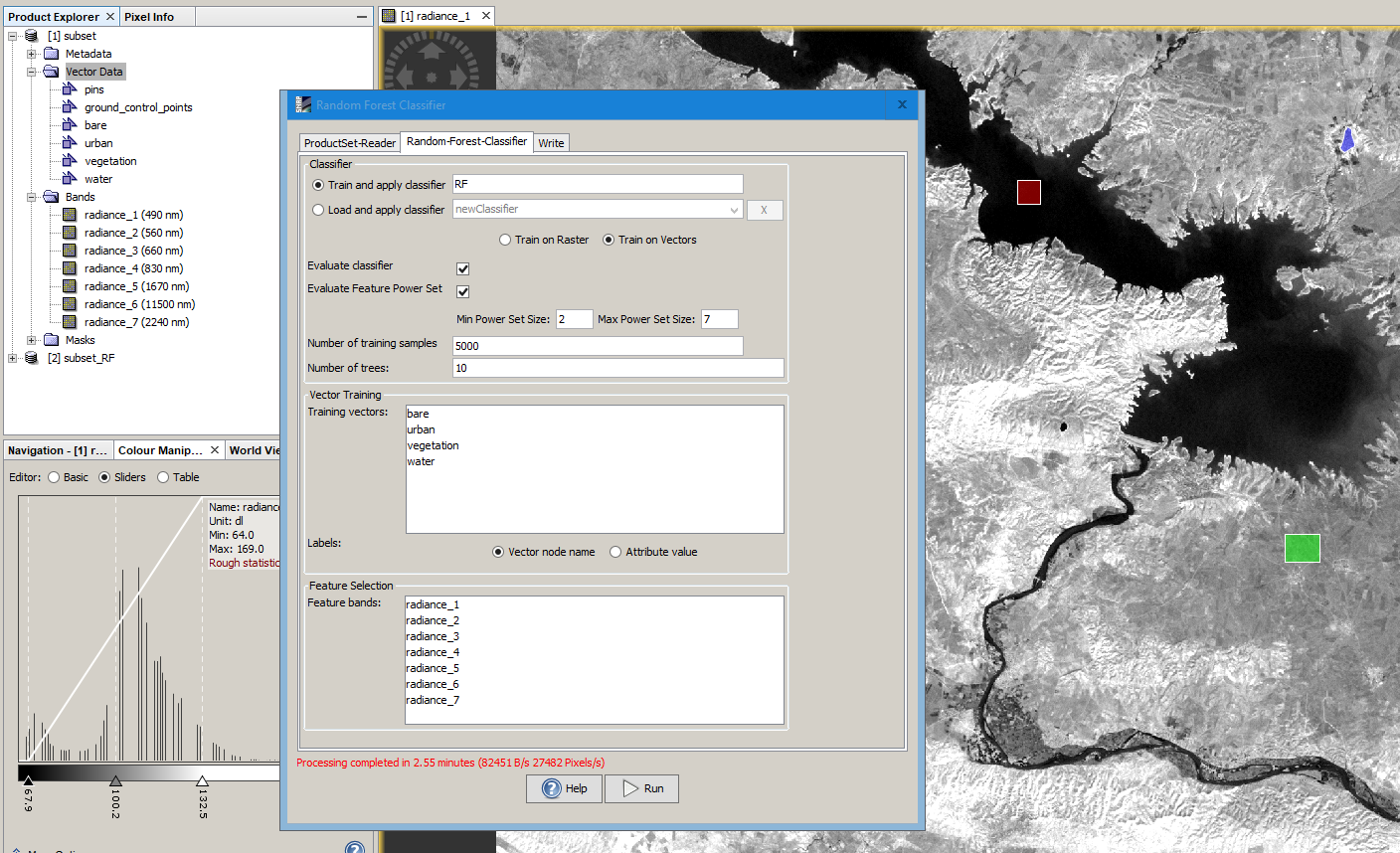
Testing feature importance score:
Each feature is perturbed 3 times and the correct predictions are averaged The importance score is the original correct prediction - average
rank 1 feature 3 : radiance_6 score: tp=0.6524 accuracy=0.3262 precision=0.4585 correlation=0.6345 errorRate=-0.3262 cost=-2.4227 GainRatio = 0.6792
rank 2 feature 2 : radiance_2 score: tp=0.4077 accuracy=0.2039 precision=0.4113 correlation=0.5493 errorRate=-0.2039 cost=-2.6315 GainRatio = 0.6649
rank 3 feature 1 : radiance_1 score: tp=0.0059 accuracy=0.0030 precision=0.0219 correlation=0.0199 errorRate=-0.0030 cost=-0.0238 GainRatio = 0.6634
I don’t know which exactly is the feature importance in percent, but maybe one of the developers can answer that.
Thanks! Let me try this. I wonder what ‘tp’ could mean? I guess one can graph the figures?
tp is usually true positive in this context.
Yes, you can use those numbers in MS excel in order to create graphs or bar charts. I explained it here: Supervised Classification output file of the "Train and apply classifier"
Thanks. Let me figure out which one could be the percentage contribution.
Hi. I carried out the evaluation, with 14 variables (bands) and 9 training classes. It took all night to run and produced a long report! I have copied small sections of the report below so you can help me interpret, particularly, the section on power set evaluation which has a total of 9,893 records with different band combinations and CVs.
Testing feature importance score:
Each feature is perturbed 3 times and the % correct predictions are averaged
The importance score is the original % correct prediction - average
rank 1 feature 6 : B12_M score: tp=0.2922 accuracy=0.0584 precision=0.2534 correlation=0.3171 errorRate=-0.0584 cost=-1.4091 GainRatio = 0.5773
rank 2 feature 4 : B7_M score: tp=0.2393 accuracy=0.0479 precision=0.1230 correlation=0.2290 errorRate=-0.0479 cost=-0.2455 GainRatio = 0.5918
rank 3 feature 5 : B11_M score: tp=0.1770 accuracy=0.0354 precision=0.1624 correlation=0.1898 errorRate=-0.0354 cost=-0.6646 GainRatio = 0.6477
rank 4 feature 1 : B2_M score: tp=0.0976 accuracy=0.0195 precision=0.2340 correlation=0.3374 errorRate=-0.0195 cost=-Infinity GainRatio = 0.6089
rank 5 feature 3 : B6_M score: tp=0.0345 accuracy=0.0069 precision=0.0806 correlation=0.1010 errorRate=-0.0069 cost=-0.1398 GainRatio = 0.6096
rank 6 feature 7 : Sigma0_VH_slv1_09Dec2016_db_Sscore: tp=0.0177 accuracy=0.0035 precision=0.1272 correlation=0.1406 errorRate=-0.0035 cost=-0.2286 GainRatio = 0.2520
rank 7 feature 2 : B5_M score: tp=0.0117 accuracy=0.0023 precision=0.0524 correlation=0.0671 errorRate=-0.0023 cost=-0.0724 GainRatio = 0.6235
Power set evaluation:
newClassifier.1: cv 95.07 % B2_M, B3_M,
newClassifier.2: cv 77.46 % B2_M, B4_M,
newClassifier.3: cv 94.00 % B3_M, B4_M,
newClassifier.4: cv 95.53 % B2_M, B3_M, B4_M,
newClassifier.5: cv 95.92 % B2_M, B5_M,
newClassifier.6: cv 94.05 % B3_M, B5_M,
newClassifier.7: cv 95.36 % B2_M, B3_M, B5_M,
newClassifier.8: cv 95.36 % B4_M, B5_M,
newClassifier.9: cv 95.98 % B2_M, B4_M, B5_M,
newClassifier.10: cv 95.13 % B3_M, B4_M, B5_M,
newClassifier.11: cv 96.66 % B2_M, B3_M, B4_M, B5_M
…
TOP Classifier = newClassifier.4028 at 98.19 %
Was lazy to read it all all values for classification can be differentiated more easily via conversion into [db], basic radar observation technique.
For under standing try to get sigma0[db] values for a dual pol S1 GRD product and look at RGB composite where:
Red band: -5 to -20 [db] SigmaVV[db]
Green band: -10 to -25[db] SigmaVH[db]
Blue Band: 0 to +15[db] SigmaVV[db]-SigmaVH[db]
Than you can define proper functions/values/thresholds for classification or difference for surface change detection.
Example of some radar composites can be found here used for additional flood detection (Link to my website I have the images on my HDD and I will not reach it for couple of days):
It should provide some insight into the radar imagery if you have any trouble with visualizing the products @annakisara
Good Luck
Petr
Dear @ABraun
I read your paper and I have some questions about it:
- Did you do whole processes in SNAP software?
- as I saw in your paper, you used different resolutions (10m,30m and 90 m) but as you was working with ‘random forest classification’, you got automatically classification result map in 10 meter resolution. Am I right?
But how about other classification methods like KNN, Maximum likelihood and others in SNAP? I think we should make them in same resolution and then do classification? - Did you get ‘accuracy assessment’ and Tables 3,4,5 and figure 5 in SNAP?
Cheers,
Marjan
answers according to your numbers:
-
To this time, SNAP wasn’t developed that far so I processed the images in python using pyimpute of Matthew Perry: https://github.com/perrygeo/pyimpute
-
In order to train the classifier I had to resample the data to the common resolution of 10 meter but SNAP should be able to take inputs of different cell size. Edit: obviously that’s not the case as you reported here: Rndom forest classification steps
MaxLike and other classifiers need to have data of same range so if you want to use them you should first convert them to integer8 so all of them range between 0-255. Otherwise the classifiers are not effective. Random Forst is not affected by this because it works with threshols instead of feature space. -
no, also based on the python module and own excel calculations for the accuracy assessment.
Dear @ABraun
I am so interested in your paper. As I read in your paper, you used textures of the S1 images were calculated by applying a Grey Level Co-occurrence matrix (GLCM). You only used Contrast, Correlation, Energy and Heterogeneity while you can find more options in SNAP software. You can see them in below image.
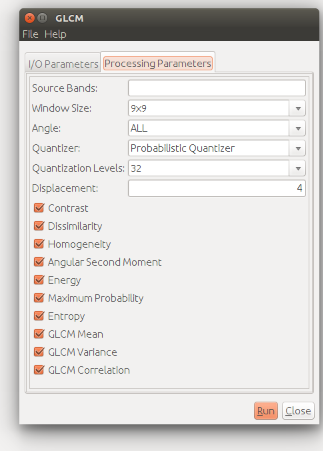
- Why do you did not use others?
- As I am working on another application (sea ice), how should I understand which of GLCMs texture features are better for using?
I saw in one paper
https://www.nersc.no/sites/www.nersc.no/files/Classification%20of%20Sea%20Ice%20Types.pdf
They mentioned that:
The analysis revealed that the most informative texture features for the classification of multiyear ice (MYI), deformed first-year ice (FYI) (DFYI), and level FYI (LFYI) and open water/nilas are correlation, inertia, cluster prominence, energy, homogeneity, and entropy, as well as third and fourth central statistical moments of image brightness.
Do you think it means that it is better that we use only ‘correlation, inertia, cluster prominence, energy, homogeneity, and entropy’ for sea ice application?
I didn’t use more because at the time when I wrote the paper SNAP wasn’t able to calculate these textures so I had to do it in Python.
About your second question: The good thing with random forest classifiers is that they select the layers which are most useful. You don’t need to know before which were suitable the most.