Hi @CiaranEvans,
sure thing, the forum is really the place to be for us SAR enthusiasts  .
.
Whether you can benefit from pyroSAR of course largely depends on your needs and the way you’d like to work with the data. Calling GPT via subprocesses sure works fine, pyroSAR also does that in the background.
However, pyroSAR goes further so that the whole data processing pipeline becomes easier to use. There are several things to it, but for now I’ll stick to those that might be relevant for your use case, i.e. Sentinel-1 GRD processing with SNAP. I assume that you have the S1 raw data storage figured out and have a working processing chain so I won’t go into raw data management. The question is, how flexible do you need your workflow to be in the long run?
For example, do you always process the whole scene or are you sometimes only interested in a small area? pyroSAR makes it quite easy to load your existing workflow and insert a Subset node with coordinates from some bounding box. Or are you interested in ancillary products like the local incident angle map from time to time and need to output them as well? These kinds of modifications to existing workflows are quite easy to do on the fly with pyroSAR’s SNAP API.
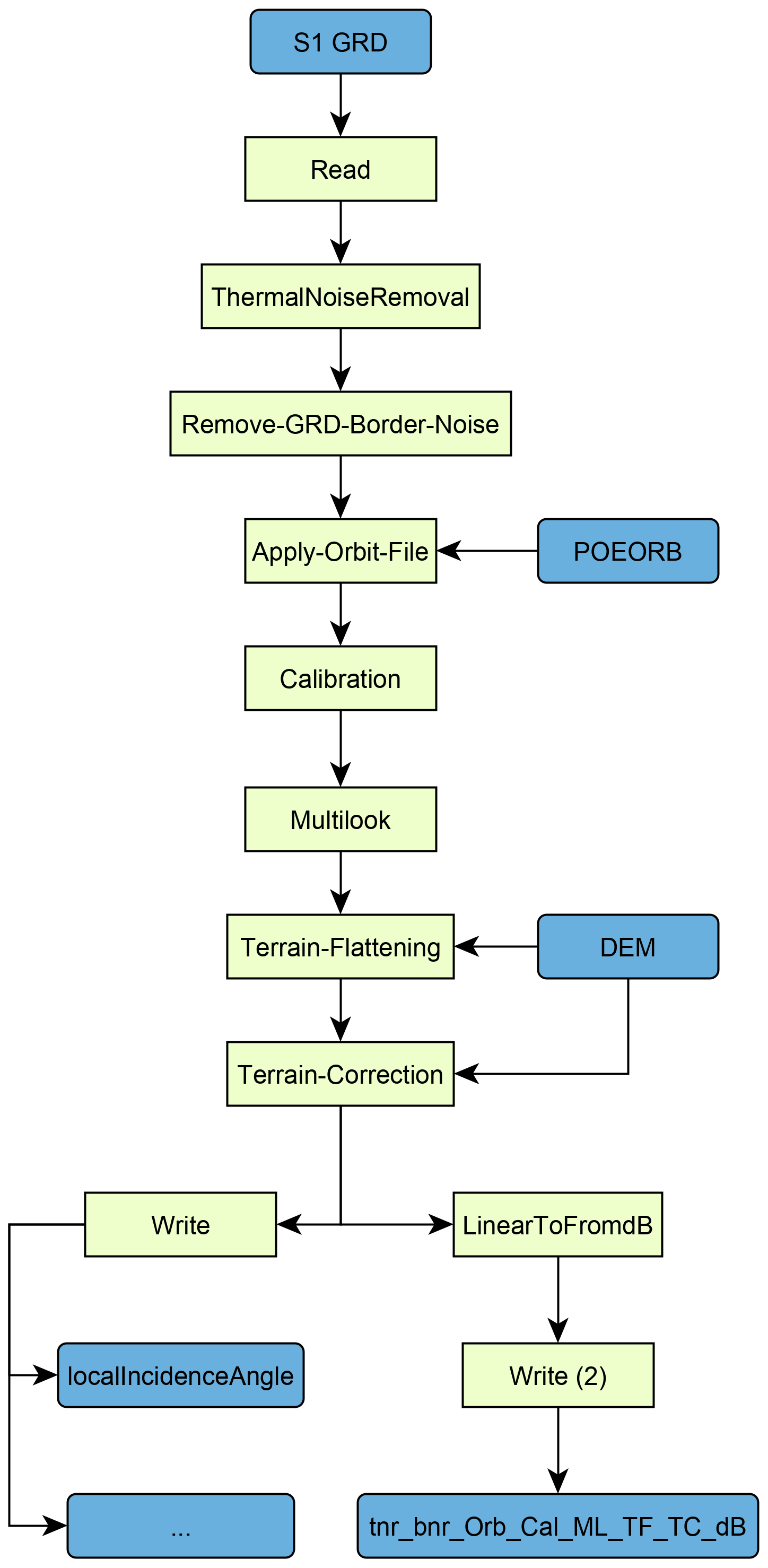
On the performance side, the ability to split workflows can significantly speed up processing. Instead of executing the whole workflow at once, pyroSAR can split it and execute the sub-workflows in sequence. In your case this could look like this:
Read > Radiometric Calibration > Write
Read > Terrain Correction > Write
This way the processing is faster and needs less memory. I agree though that this should not be necessary and SNAP will eventually be just as efficient for long workflows as it is for short ones.
On top of that, I occasionally discovered some output formatting issues. For example, SNAP does not properly write the nodata values to the GeoTiff files. Also, I found that the pixel ordering in the GeoTiffs is quite unusual and cumbersome to read in other software. I had addressed this here. Those issues might be fixed by now but sure saved my day some time ago.
One feature that really gets me excited lately is the ability to directly connect it to my analysis environment. I do a lot of time series analyses and want to treat all processed images of an area as one 3D cube. For this I am developing spatialist, which is pyroSAR’s spatial data handling backend. Here’s a small example:
from pyroSAR.ancillary import find_datasets, seconds
from spatialist import Raster
# some directory containing processed data
directory = 'E:\\DATA'
# collect all files with the pyroSAR naming pattern
files = find_datasets(directory, polarization='VV')
# sort the files by their acquisition time
files = sorted(files, key=seconds)
# connect all files as a 3D object and read a subset into a numpy array
with Raster(files)[0:100, 0:100, :] as ras:
arr = ras.array()
Here pyroSAR’s consistent naming scheme comes into play making it easy to keep track of processed scenes. However, this really excels when using data from different sensors.
Okay, that’s already quite a long message so I’ll leave it here. I hope this sheds some light and you are still interested in using it. I’ll be around to answer more questions of course.
Cheers,
John

{kind=link}