I am new user of SNAP software, is there any way to generate kappa coefficient and accuracy directy while classification?
I don’t understand creafly the result given by SNAP when the classification is finish, many values that I don’t know how to interprete nor to use to calculate those parametres.
Thank you for your help
1 Like
can you please post a screenshot? What vfalues don’t you understand?
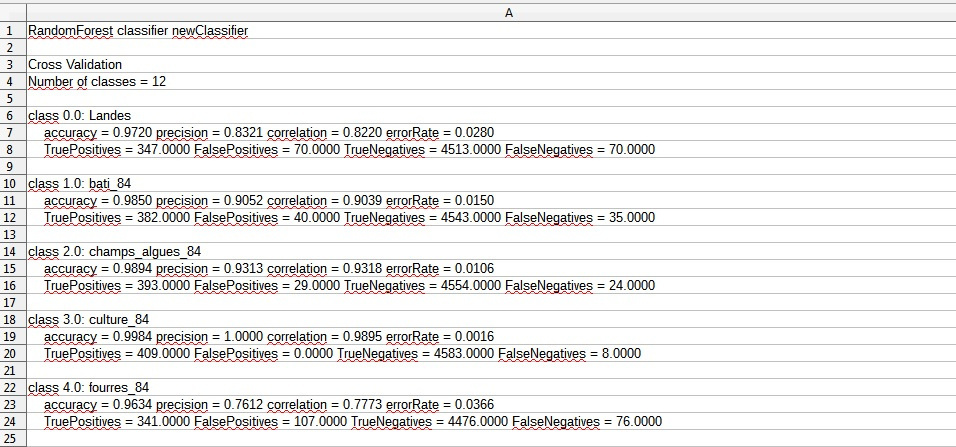

Just because the accuracy value of each class seems very high than normal I think, is the correct predection does mean the global accuraccy?
and I have to calculate kappa coefficient separately?
Thank you
you have to be careful about those values:
This document only assesses the accuracy of your classififer, that means how suitable it was to predict the training data. For example, how many of the sample data fit into the scheme which was built up by the Random Forest.
As you say, this does not mean the classification is correct in terms of actual landcover. As no information on validation is available in SNAP you cannot make predictions on how good the results actually are. For that, you would need to have samples showing the real landcover and validate your results based on them. With that statistics you can also calculate kappa. As far as I know, this is not possible in SNAP yet.
2 Likes
Now I can understand, because before I thought that are the true value of precision, thank you for your clarification
1 Like
Dear seniors,
For example, my correction prediction is 22.56%, Does it mean that I need to add more training data in order to improve classifier as well as accuracy of map, right?
-could u share me documents about how to interpret classifier evaluation ?
Thank in advance,
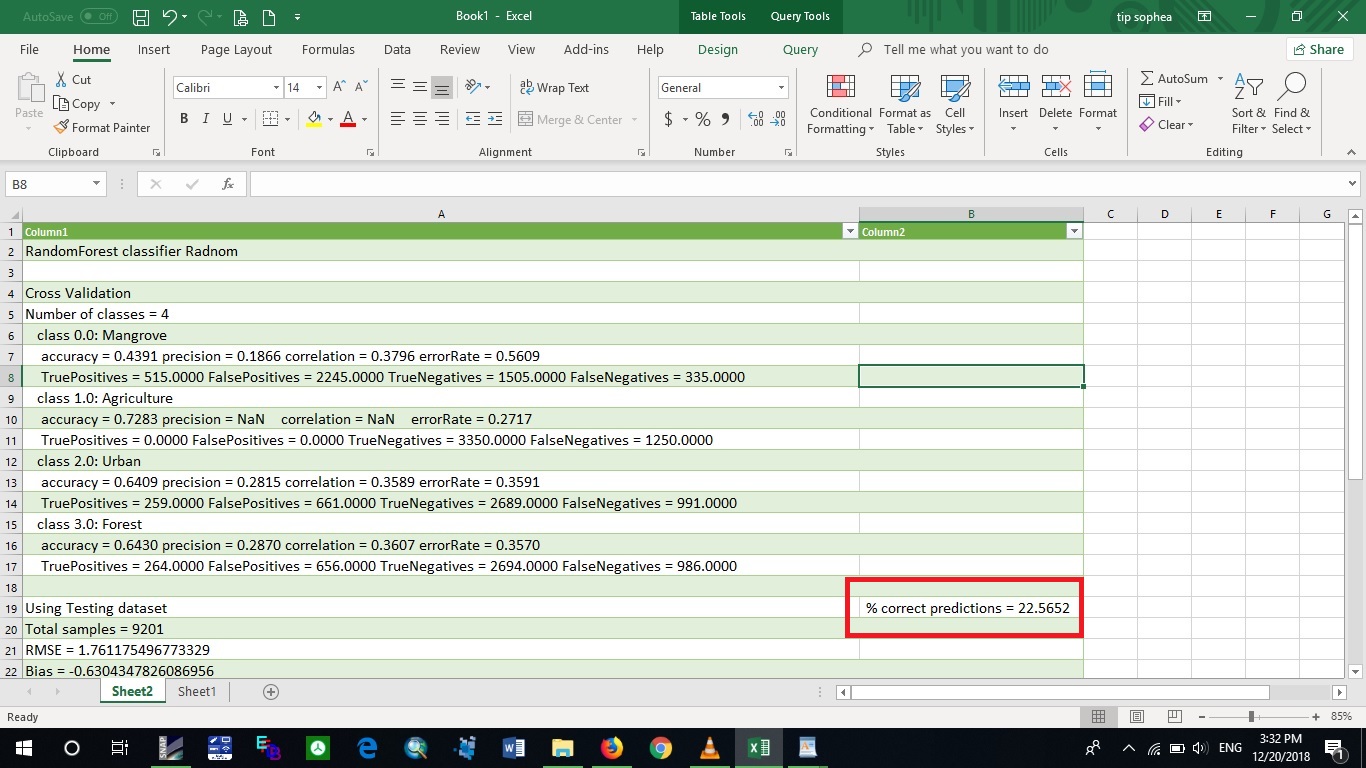
Training data is just one contributor to a successful classification. If your rasters are not representing the classes to be detected, increasing the number of training data won’t help.
Please have a look at this discussion on factors affecting the result of random forest classifications: Number of training samples at Random forest classifier
How much input rasters do you use?
Here are some suggestions on how to increase your feature space: Classification of GRD product - #2 by ABraun
About the interpretation:
This article gives a nice overview on the difference of accuracy and precision, as well as true positive/negative and false positive/negative: Sensitivity and specificity - Wikipedia
1 Like
Thank you very much Senior!
I have just started to study remote sensing. I follow the RUS Copernicus webinar video in order to make a land use classification for graduation (thesis). I have many challenges and I am very thank for your response.
- The input raster/layers I use are 5 layer, B2, B3,B4, B8,B11,B12.
- I think just understand about accuracy value of classifier from SNAP. I got one suggestion that after collect 500 samples, I need to do cross validation by splitting those 500samples as training and testing data… is that process same as Random forest works in SNAP, am I right? If so, in case the accuracy of classifier is acceptable (>85%), I dont need to do cross validation, is it correct?
Thank you very much!
The accuracy in SNAP determines how well the Random Forest classifier matches your training data. Even if it would be 95%, there could be lots of errors in your map when the training data were not representing all of the available classes. It is therefore required to also perform an independent accuracy assessment of your classified data.
For this, you need to digitize further points (independently from the output) and compare how well the classes match. e.g. how many of 100 points of the class wetland were classified correctly?
SNAP is not able to do this at the moment, but I explained it here at more detail: GLCM worsening accuracy results?
Thank you very much senior! I got the point. I have few more questions:
- For training data, could I use google map and digitize as polygon (will the publishers accept that case)?
- What happened if 10 classes have 50polygon for training data;however, 1class has only 10 polygon for training data? what would be a solution for that case?
I am very thankful for your valuable time and help!
independent training (and validation) sources are always better than digitizing on the used imagery.
this depends on the case. If a class is underrepresented in the training data but has a distinct signature (different from other classes), that is fine. But if two classes are alike and one has more training samples, it is likely to be preferred by the classifier.
1 Like
Dear sir ,I had the same prolem that I don’t know how to evaluate result accuracy in snap with the Sentinel-1.
as I explained it in the post you quoted: SNAP has no built-in accuracy assessment.
You can import the classified raster into QGIS and use one of the following for accuracy assessment:
- Semi automatic classification plugin: https://www.youtube.com/watch?v=MxBwMQnyZKw
- AcATaMa: https://smbyc.bitbucket.io/qgisplugins/acatama/how_to_use/
Hi there,
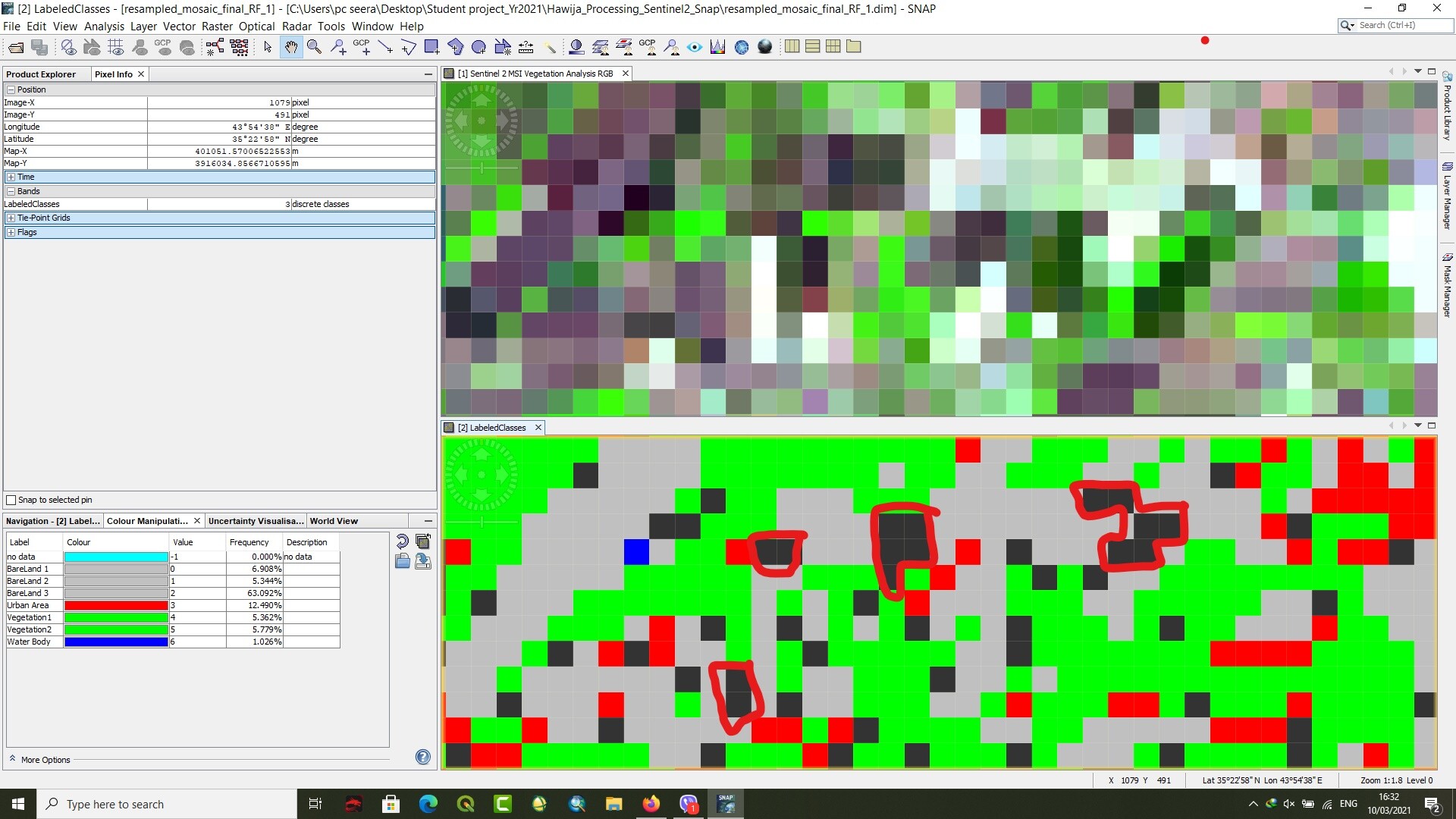
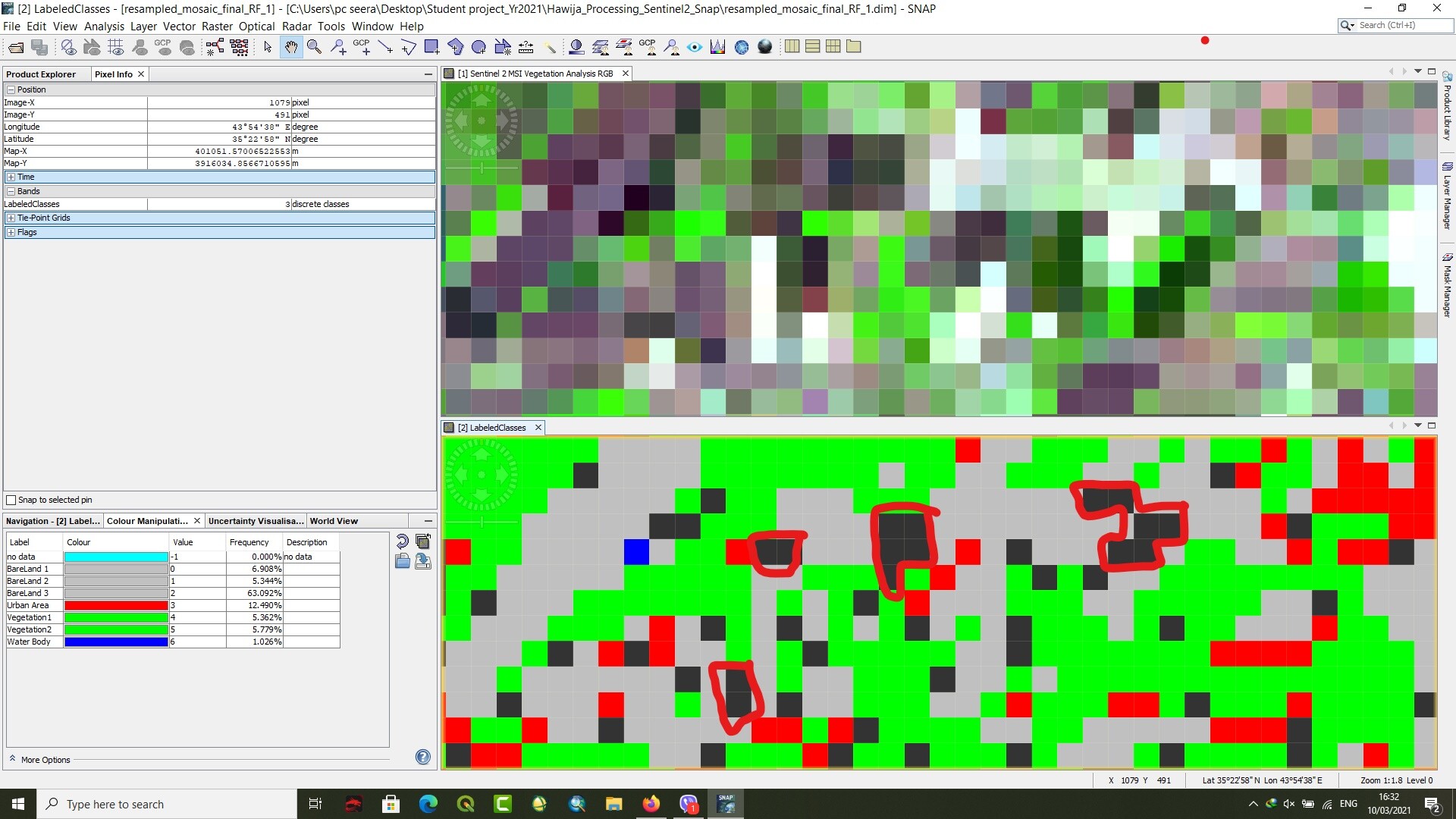
I have been going through a sen2 image classification in SNAP and I had got results using RF classification. However, I have some non value pixel (as it shown in black pixels)which I do not know the reason!
If anyone give me the reason for that and how I sort it out ?
Thanks in advance
{kind=link}
this can have two reasons:
- one of the input features is NoData at these pixels
- the confidence of these pixels is below 0.5 (please have a look at page 23/24 of this tutorial)
Thanks for your swift reply on my text, ABraun
I will go through the article
Dear ABraun,
I have sort it out based on the tutorial provided me with… Cheers
very good. What was the issue in your case? Just so others can learn in case they have a similar problem.
Dear ABraun,
So sorry, I did not see your last massage
The issue was related to the confidence of the pixels in the classification AOI. Changing the Confidence from >= 0.5 to >= 0.2 in the valid pixel expression has sort out the issue. And this can be done by right click on the Labelled classes , then choose properties from the menu, them edit the confidence to >= 0.2
Many thanks for your tips…Farman
1 Like
thank you for sharing your experience.