Hi everyone,
I’m sharing a Python tool I made where you can visualize and export the Sentinel-1 S-1 TOPS SPLIT Data simply called S-1 TOPS SPLIT Analyzer. Simply input the path of the downloaded S1 image and choose which subswaths you want. Input image should still be a ZIP file. Then you can use the class methods to extract the data. This tool can be used in the command line and as an import.
Command line sample:
python stsa.py -zip S1_image.zip --swath iw2 iw3 -polar vv -shp out_shp.shp -csv out_csv.csv -json out_json.json
Python sample:
from stsa import TopsSplitAnalyzer
s1 = TopsSplitAnalyzer(image='S1_image.zip', target_subswaths=['iw1, iw2'], polarization='vh')
s1.to_shapefile('out_shp.shp')
Files and documentation are available here:
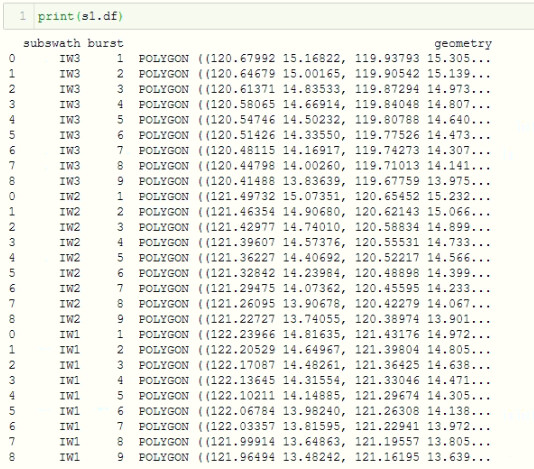
You can specify specific subswaths and polarizations to extract. You can export it as a shapefile, csv, or JSON. You can also view it on a webmap (You need Jupyter Notebook).
In addition, you can specify one custom shapefile to add to the map. For me this is useful because I can quickly view which subswaths and bursts I need to use for any type of work. In the image below, it shows the output of the webmap function and the custom shapefile is marked as red.
I welcome any feedback or issues. Hope it helps!
Sample output:
s1.visualize_webmap(polygon='aoi.shp')
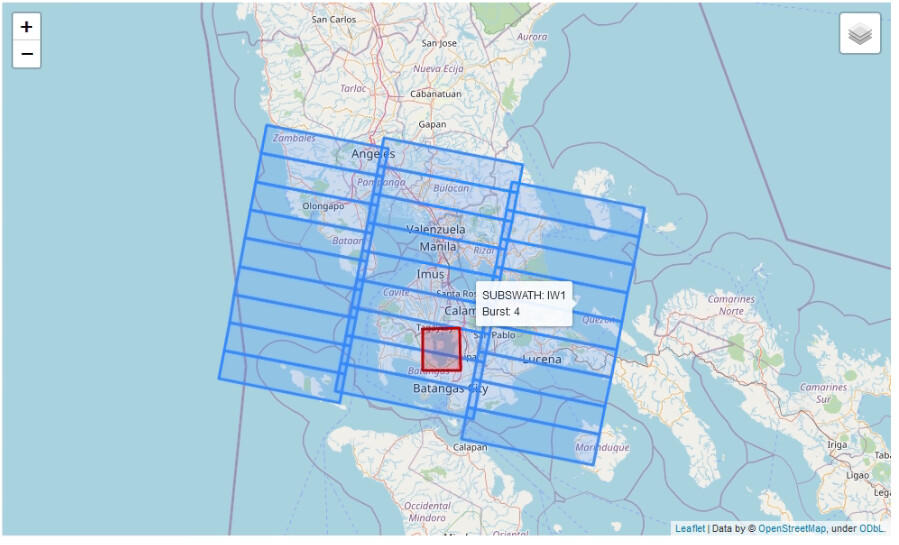
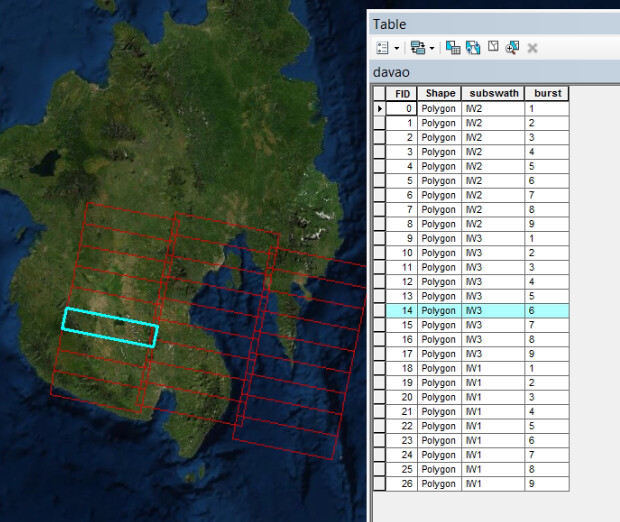
Exported shapefile:
s1.to_shapefile('subswaths.shp')
EDIT: added codeblock and some instructions for clarity.
 . I renamed the input so that it matches the reference in the documentation
. I renamed the input so that it matches the reference in the documentation 

 sorry - being a bit exaggerate here…
sorry - being a bit exaggerate here…  I kind of formed a wrong misconception of where things should go and didn’t bother to read the current category descriptions.
I kind of formed a wrong misconception of where things should go and didn’t bother to read the current category descriptions.