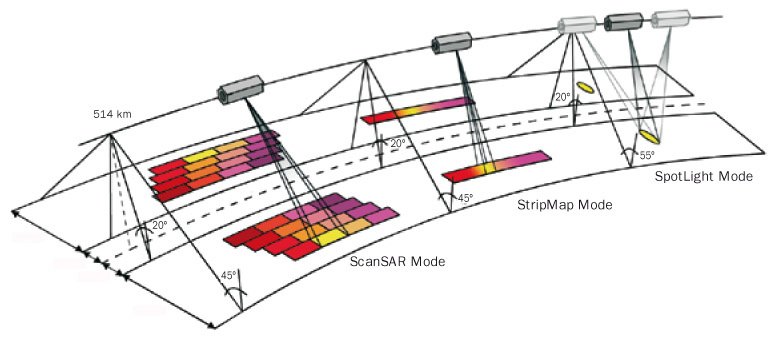
ERS (and most other SAR sensors) are primarily acquired in StripMap mode. It is generated line by line.
Sentinel-1 is acquired in TOPS mode (illustrated as ScanSAR principle below). Neighboring pixels are of different acquisition phases. That is why Sentinel-1 data needs some more calibration and corretion steps.
ERS, ENVISAT and Sentinel-1 are C-band satellites at quite similar spatial resolution. This makes them potentially comparable and usable within the same scope.
However, most classification approches need a multi-dimensional feature space. Optical satellites acquire information at multiple wavelengths (visible, infrared, thermal), but SAR data is restricted to one wavelength. Its potential for classification purposes is therefore limited.
Have a look at the possibilities to increase feature space for SAR data:
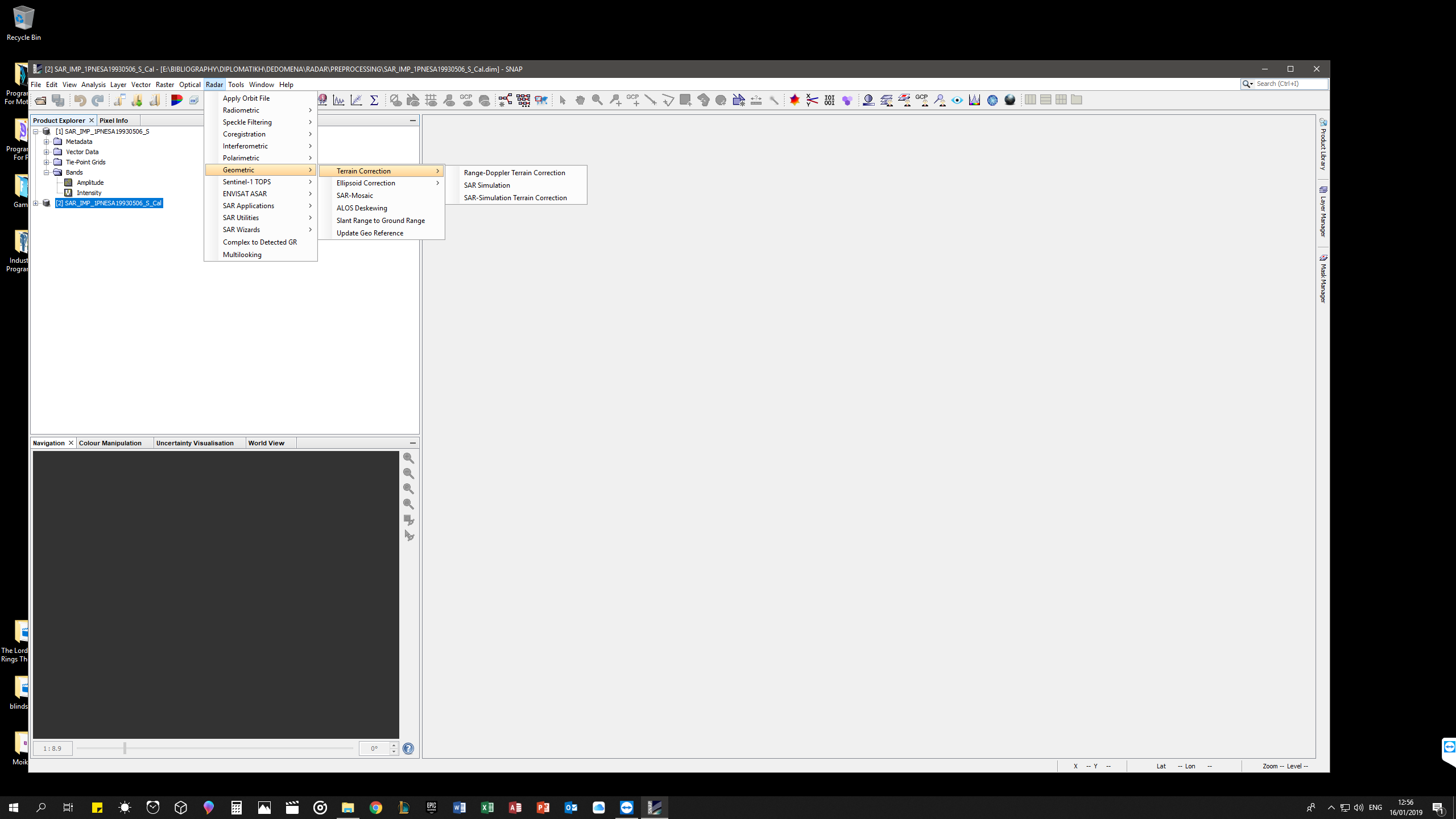
For terrain correction i must do SAR Simulation or SAR-Simulation Terrain Correction? (I think Range-Doppler TC you must do only for Sentinel SAR… Am I right?)
Both sensors need to be calibrated, but it is better to select no band in the calibration tab.
Range Doppler Terrain Correction and SAR Simulation Terrain Correction do the same task and can be applied to both sensors. It’s just different methods to place the pixels at the correct location.
I have GRD S1 product. I follow all the workflow.
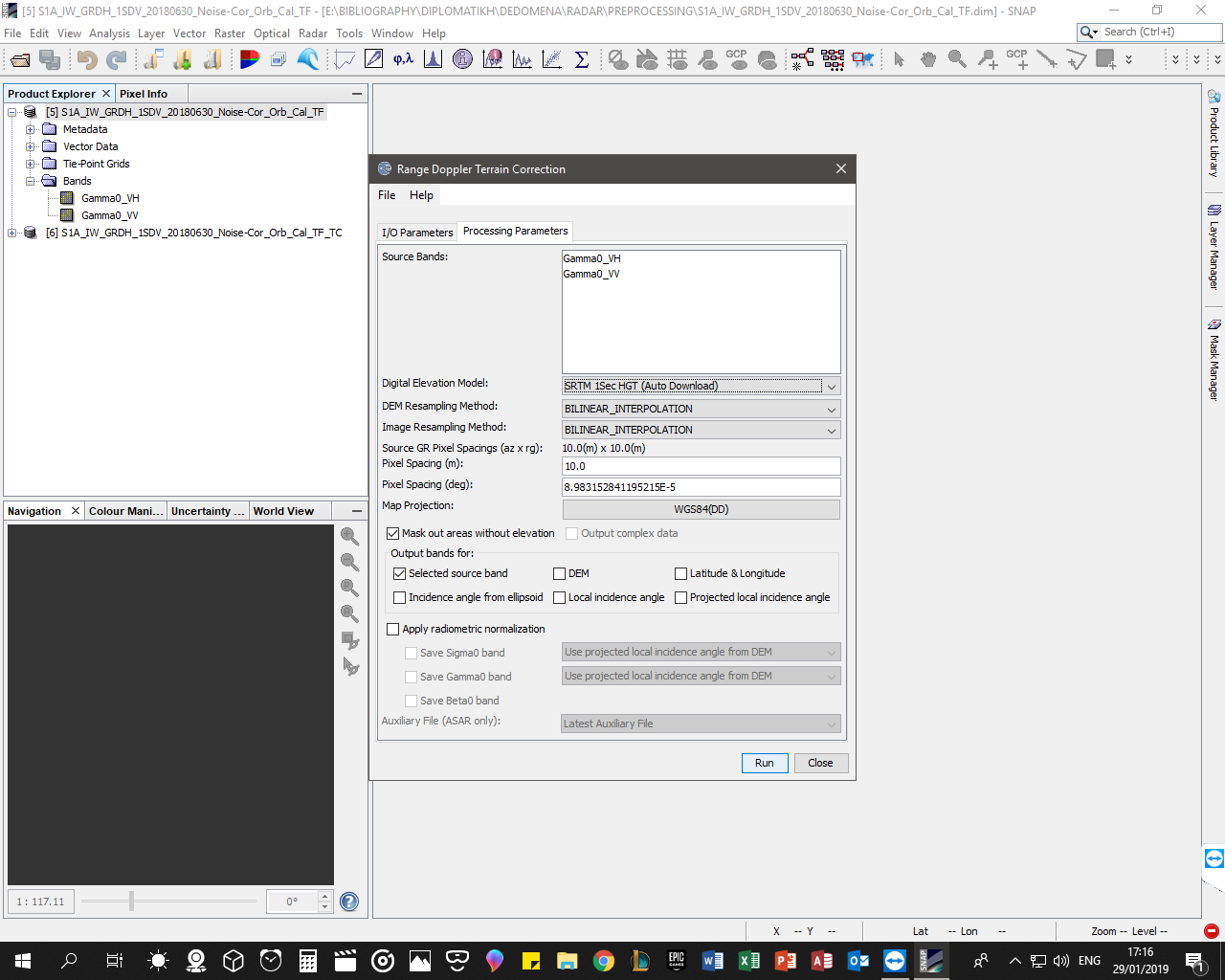
If I write “30” at pixel spacing(m)( at Range Doppler Terrain Correction), I resampling my product to 30X30 meters pixel size?
I need after this to do registration between S1 and L8. And ERS with L5, so I need all the final products at the same resolution (30 m).
Instead of resampling at the Terrain Correction step, you can also apply Multi-Looking to your data before it. The result is slightly different - I suggest to compare which output produces the better image quality at 30 meters pixel size.
The results should not have a large difference. Bilinear should be the minimum number of samples to look at giving the best performance. Bicubic will use more of the neighbouring samples without a much larger performance hit. The sinc interpolators have a lot more to calculate and therefore will be slowest.
Hello! I need to extract the backscatter coficiente of ERS1 and ERS2 to work with Landsat TM (30 meters). What would be your flow of radiometric and geometric correction?
Thank you very much for the help
I am performing classification of sentinal-1 data to a binary image in to water and non-water by thresholding. Can I do terrain correction after classification of data(ie. on binary image) ?
That is possible and should be no problem. Just make sure you select nearest neighbor resampling for your binary image in the terrain correction step so that the values will not be recalculated or averaged.
Ok. Thank You @ABraun.
One more thing, out of gamma naught and sigmma naught product which one would give better result for water binary classification using thresholding teq.
You are saying they differ in topographic features and volume scattering. But these factors will have lot to do on the final backscattered values . Ultimately, the classified images obtained from these two different inputs will give different outputs. So, how can you say that their wont be any difference if I am not wrong.
Thank you for the detailed steps for products processing. From the other hand, I have assumed some controversial with @lveci answer
That is, you missed the Thermal Noise Removal (TNR) step for SLC products, but from the @lveci answer I understand that this step is required.
Than, you recommend the TNR for GRD products, but @lveci told that TNR is already applied.
Sure, your answer partially explains the relevance of this step here
But how can I check the presence of Thermal noise in products I need?
Dear @ABraun,I didn’t want to confuse you. It is just to clarify some issues with the Sentinel-1 products processing.
I don’t insist on the TNR irrelevance for the GRD processing.
The trouble is that I still can’t find out how to check the Thermal noise presence in my products.
And would you mind to explain, whether users should apply the TNR for SLC?