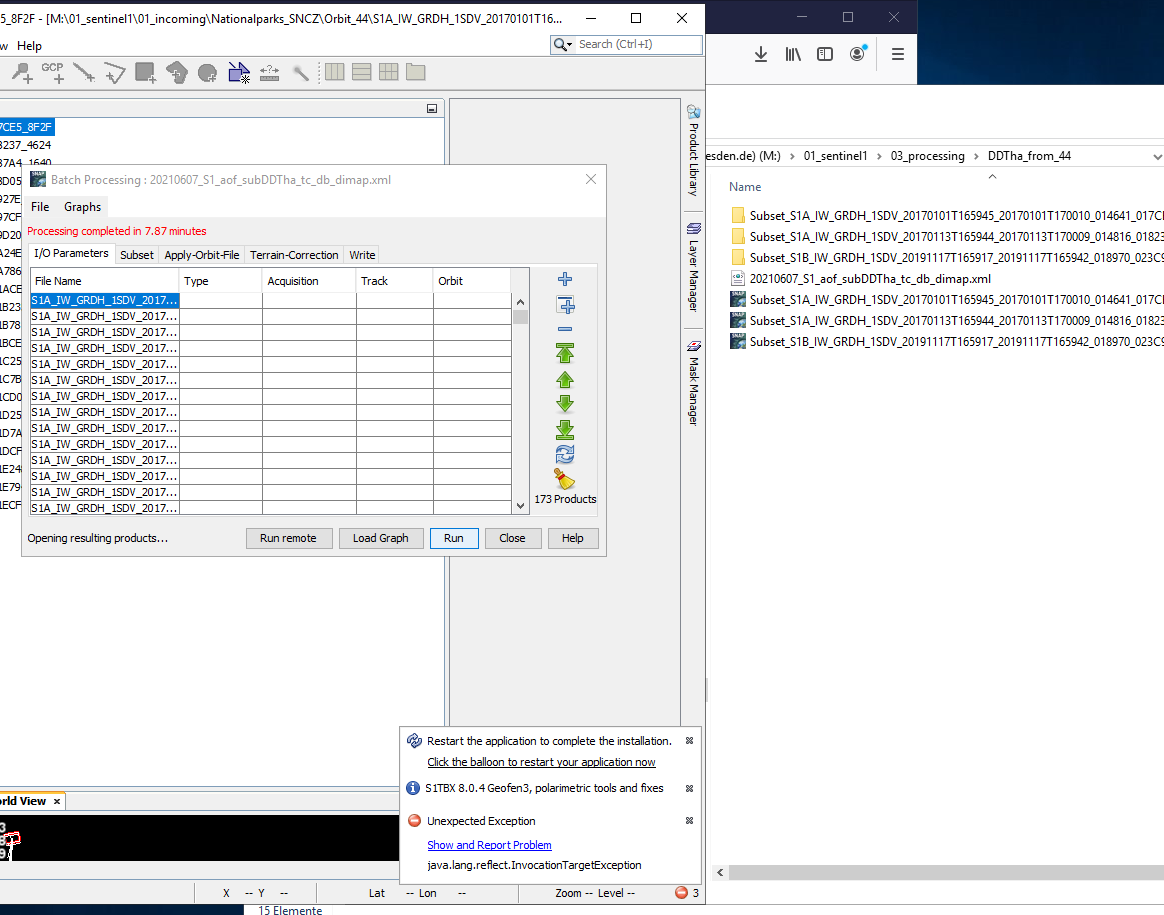
I have this abovementioned NullPointer error when processing a S1 Image on a Windows Server 2019 VM. I attach the error log as a textfile.
Can someone tell me what this means and how I can fix it?
Despite the error a product is created but it seems to be corrupted. RAM on both machines is 32 GB.
Ah sure, sorry. I am just applying orbit file, subsetting and terrain correcting (Outputting additional Incidence angle bands) and saving to *.dim.
I attache the graph: 20210607_S1_aof_subDDTha_tc_db_dimap.xml (4.4 KB)
I am quite certain that it has somehow to do with my VM (software) setup. Despite enough resources (48GB of RAM now) which is not fully used during the abovementioned processing steps, SNAP keeps crashing, which is not often the case on my local machine.
On a VM it might be necessary that latest, or better said not too old CPU instructions are available. The type of CPU can often be configured. Recently I had also issues with a VM recently and I noticed that a CPU from ~2005 was emulated.
In addition to this I had to install the Microsoft C++ redistributable package on the VM. Never noticed that it was necessary, because it was available on my local machine. may use case was the TensorFlow library maybe for you it is a similar cause.
Thank you I installed the Microsoft C++ redistributable and for a single image it works now.
The CPU is fine it is a Xeon from 2014. Since the machine is hosted on our universities Central Computing Center I also cannot influence the hardware much.
However I still do not manage to start the batch processing of 100+ images on this VM.
It seems to process a single image and stops then:
This is the error message: java_error.txt (3.4 KB)
Can this also be related to the VM or am I overseeing another mistake here?
I never had an issue with batch processing stopping at my local machine.
Ah. I was not aware, that the VM virtualizes a CPU. How Can I check on it? In the Windows System Infortmation I see the CPU of the Host system (Or at least I guess it is that one because it is the same as for our Linux VM´s on the same host system).
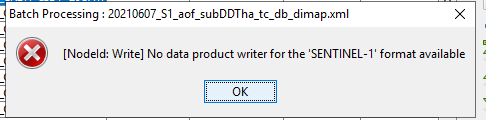
I now replaced format name in the graph.xml that I was using and now I get this error:
Same issue in the reader:
Is indenting crucial in *.xml files?
I have attached my altered graph (inserted your suggestion in line8)20210607_S1_aof_subDDTha_tc_db_dimap.xml (4.4 KB)
but the batch processing chain seems to continue this time and for the first time shows a more realistic estimate for the time it will take (almost 7 hours from now). I will see if the VM stands it and if it completes. Thank you Marco for your help so far!
If I wanted to do the same thing on a Linux machine in the command line, what would be the steps that I would have to take?
I think it is fixed with the latest updated from last week.
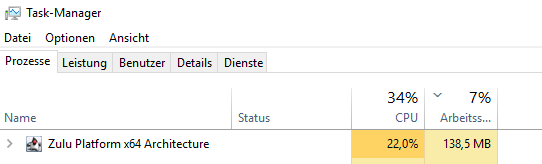
Yes, Zulu Platform is Java OpenJDK distribution we use.
For running your graph on a Linux machine no special preparation is usually needed. You just need SNAP. But some Linux distros which need special treatment. Especially when you use CephFS.