Indeed you are right, I need to correct that. Actually this timing was with 2 bursts.
I will gather your comments and introduce them in the next release.
Do not hesitate of tell me or asking useful things and finding situations which might be changed in future releases!
One more question: Does it make sense to include the data of the master image in the slaves folder or can I simply leave it out? As expected, it produces no interferogram, but by now I always had it included (don’t know why actually).
Well, in fact I never put the master image in the slaves folder, otherwise indeed the script produces an empty interferogram that later during the stamps export is not considered.
For the moment this is on user’s hands to decide where to put the master. As I have mentioned, normally I put the master image in a separated folder as it is logical that in the slaves folder you only let there the slaves, otherwise it could had been named SLC folder for example
I could include a check on the acquisition date to avoid that interferogram computation, that is always an option. But it is not a real problem let the master inside, I guess, even if it makes no sense.
me again, sorry. Do you suggest a specific name for the master. I noticed that the products in ifg and coreg are called “b.dim_201800101_IW1.dim” which probably comes from my master named “20171208_split_Orb.dim” and there might be some false string addressing. This later causes problems, when the output files are not named as expected.
Edit: I noted that if I add anything in the MASTER= tag before the coregistration step, the script tries to produce weird output names, such as name_of_split_product_full_path_of_master.dim.dim
Maybe this is Windows only but some of the strings appear where they shouldn’t.
It must be somewhere around line 87-90. I couldn’t find why the name of the master appears as an output name for the split process.
Mmm I see…
Indeed I thought that the master image will keep the master image name + _Orb_Split.dim or _split_Orb.dim or similar that SNAP adds at the end.
Could you please keep the master splitted name similar to:
My script in fact takes 8 characters starting from 19th character in the master string’s name. It might seem a bit weird that decision, but it seem to be quite logical and intuitive to get the master acquisition time for the master name after splitting and apply orbit step, assuming you do so using SNAP, and hence following its naming convention. Next time I will just get it from the metadata itself, whatever name the master may have.
CPU=5 * From a total of 6
CACHE=80G * I have 112G
##################################
Nevertheless, when I run the python script, this error appears
pmatuser@DataScienceSAR3:/media/datadrive/SAR/PSI_SBAS/CABILDO$ python slaves_prep.py project.conf
python: can’t open file ‘slaves_prep.py’: [Errno 2] No such file or directory
Is there a path structure for snap2tamps to be installed properly? *It can be an improvement for the manual, which is kind of cryptic.
did you navigate to the directory where the python scripts are located?
Second, it should be: IW1=IW2
Besides that, you need to prepare the master as defined here (TOPS Split and Apply Orbit) and name it as described here. Use the full path to the prepared master product in the MASTER= tag.
I guess I will copy a snap2stamps folder for each project I run in the future, so I would be able of keep the files in the same directory as the files. So, I understand from your answer that I need to run the python scripts from snap2stamps bin/ folder in the terminal.
About the slaves folder, where is the option to fulfill the path?
You need to install the python module pathlib,
It should work with : pip install pathlib
For what I see in your project.conf, your GRAPH variable should point to the folder with the graphs provided by snap2stamps so maybe you need to ensure that.
Regarding the slaves, that folder should be created inside your projectfolder with the already downloaded sentinel1 images all there together in the same folder being each of them a zip file.
That script will sorter them to be able to run the splitting correctly.
Why? I mean, I believe you, but if you explain me more, I’ll learn. Since I have 112G, I´ve used less than 80% of RAM. Please answer only if you have time.
Maybe the explanation is quite similar to the explanation I have for the DEM, amplitude and lat/lon images that SNAP created when I’ve used it in High Priority, tho!
Well, the memory specified in the CACHE is the memory allocated for the processing to write temporally files (I believe, here the developers could add more precise details), and it is different that the memory allocated for the Java Virtual Machine memory needed to run SNAP/GPT.
From my experience, I would add more memory to GPT on the maximum memory parameter -Xmx defined inside of the gpt.vmoptions file found on the ${SNAPHOME}/bin folder. This memory needs to be higher than the internally required by GPT, otherwise you may have problems during the processing such as Java Heap Memory and similar (please anyone correct me if I am wrong).
Hence, I believe it is more important to have higher the Xmx than the CACHE used as -c parameter using gpt command. So my suggestion is not to use the 80 % for the CACHE, but for the Xmx.
Hi mdelgado and all STEP community,
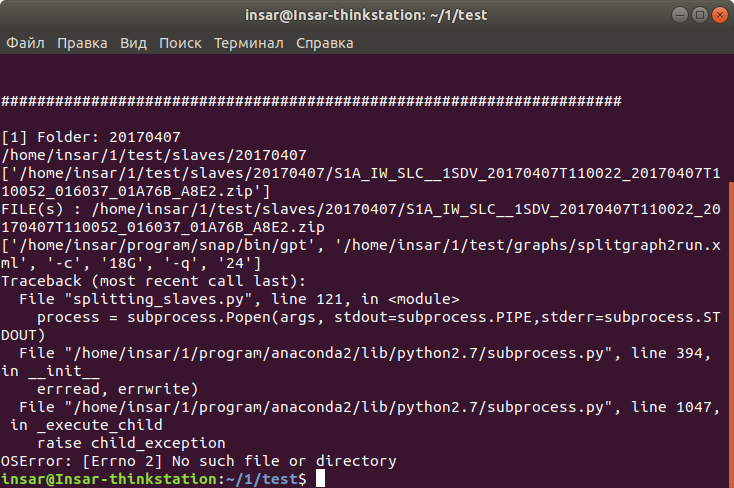
I successfully used the snap2stamps until I needed to reinstall my ubuntu system. After that, the scripts began to work incorrectly. Now only the slaves_prep.py works normally. Other scripts produce the following errors (screens). I used Python 2.7.15 installed from standard repositories as well as installed an Anaconda package separately.
Please help with ideas how can I fix it?
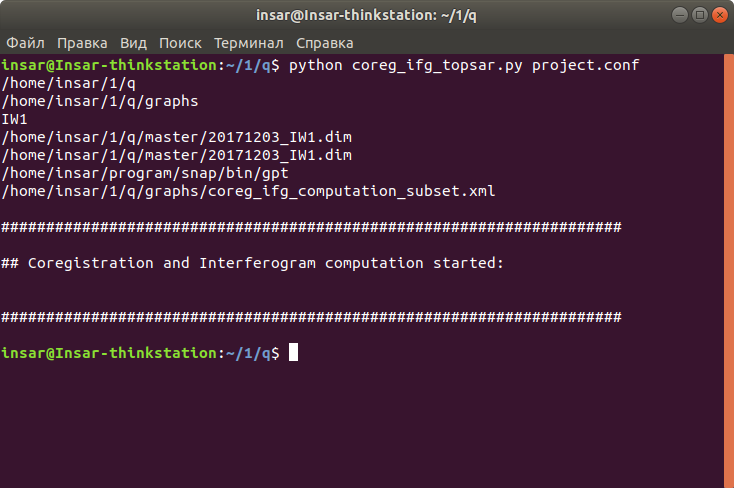
if the paths and data names in the conf file are not correct, the Coregistration exits without any error message. Can you exclude that something in the directory structure or data naming has changed?
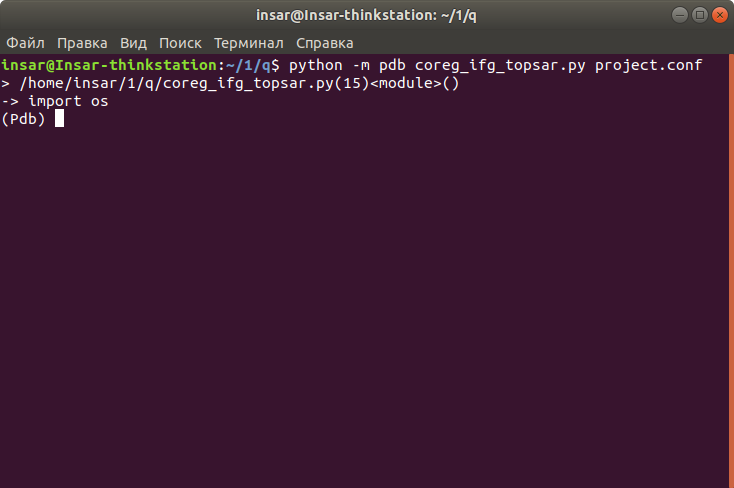
I checked the path in the project.conf and everything looks fine there . Very strange, but when i run the coreg_ifg_topsar.py the path to the master is displayed twice. Is it normal? If I run the script in debug mode (pdb), the process stops on the “import os”. If I remove the path to the master, the process stops at the “subprocess.Popen”.
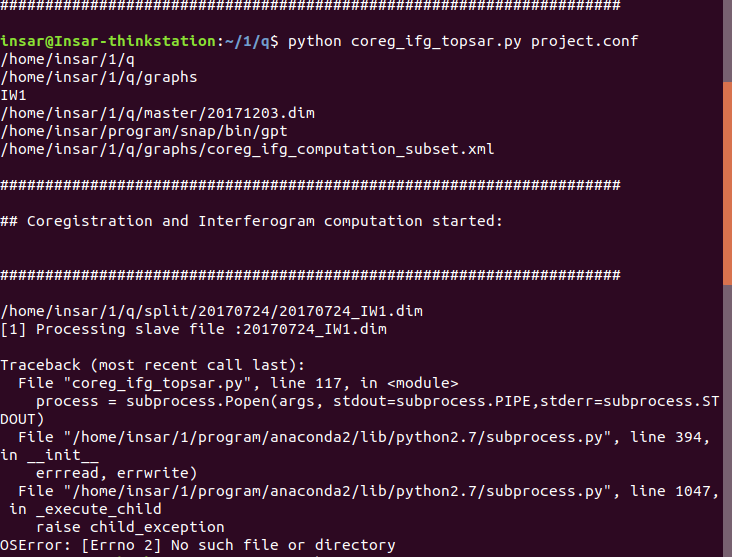
Indeed the problem is on the master name, as for the subswath to process the software gets the IW1 parameter, try to avoid to include that on the Master full name.
Well, there could be several reasons, for which I need to understand what you are doing now different than before you were doing correctly:
Are you processing the entire subwath now? The scripts provided has been tested with few burst on the master, and hence, it is possible the memory requirements should be increased for your full subswath processing
Which are the cache parameters you have defined on your conf file? I need to know to undestand what is happening…
Could you post the coreg_ifg2run.xml file produced to be run with the gpt? Maybe also the log file coreg_ifg_proc_stdout.log ?
I process the full subswath data with AOI in project.conf. My workstation has 24GB of RAM but when I processed the full coverage data in SNAP GUI I had no difficulty with this configuration.