my issue is, that I am working with the statistical output-files of each supervised classification, located at .snap\auxdata\classifiers.
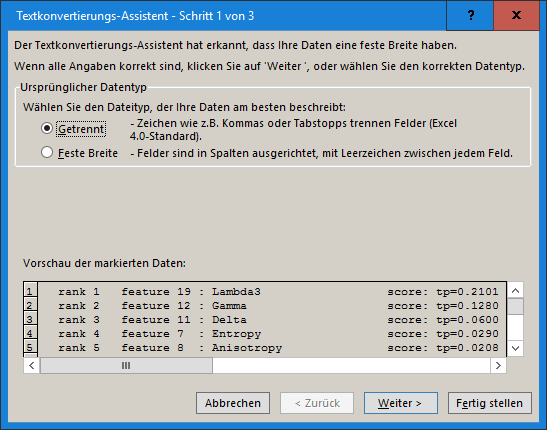
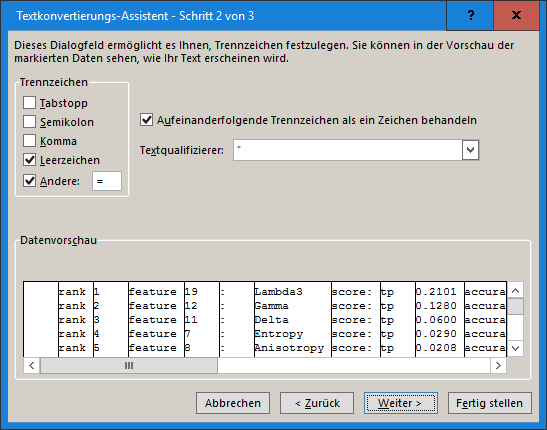
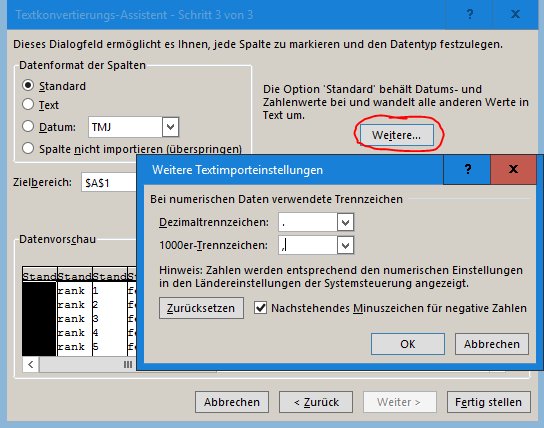
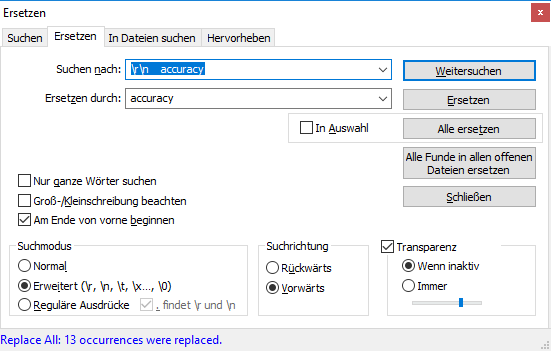
The problem is, that the files do not have clear delimiters in order to transform the data in a spreadsheet. Maybe there is an easy way but at the moment I am using notepad++ and e.g. transform blank spaces as well as a few carriage returns to semikolons.
If there is currently no better way maybe you could consider it in the next update.
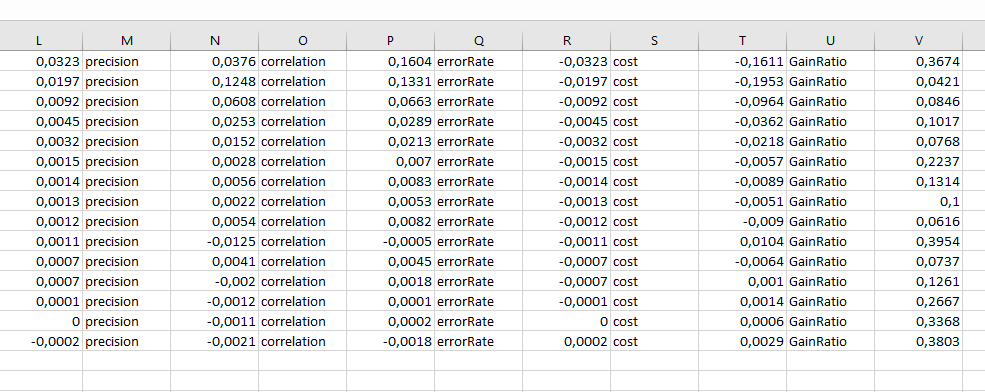
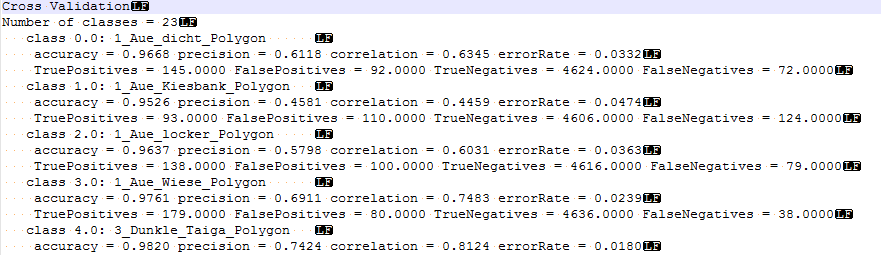
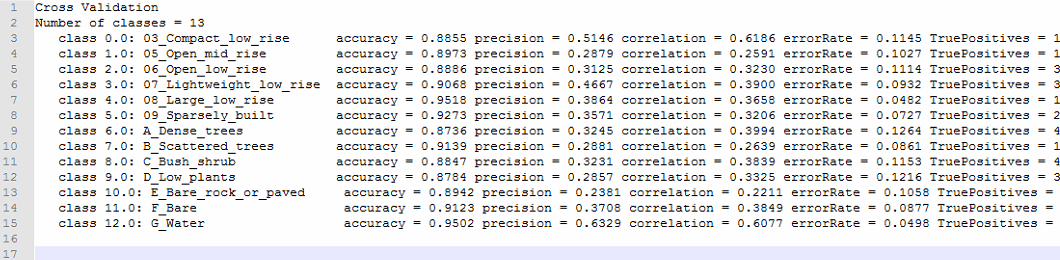
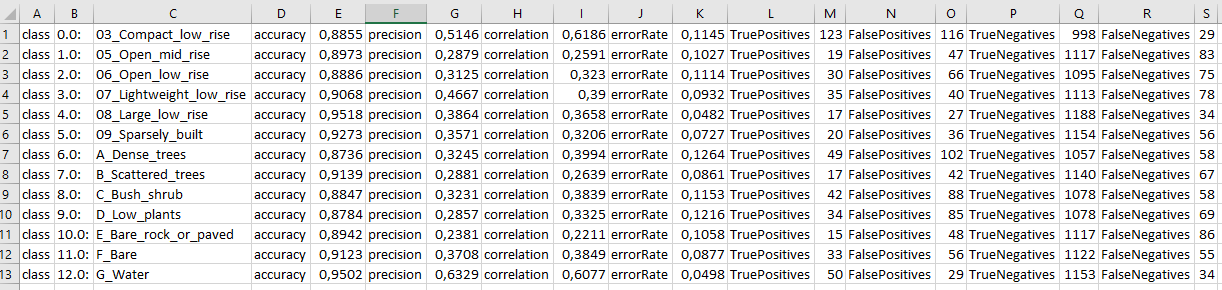
Thank you @ABraun this works good for the section “Testing feature importance score” and I will keep it in mind. But it does not work for the cross validation (the upper section of this text-file) because there are 3 line breaks for each class [1]. Tell me if im wrong but MS Excel is not able to determine which line break defines a new row and which stands for a new column [2]. I think search and replace could be a solution for a few classes but for many classes and many classifications (for comparisons) this is quite time expensive.
@ABraun,
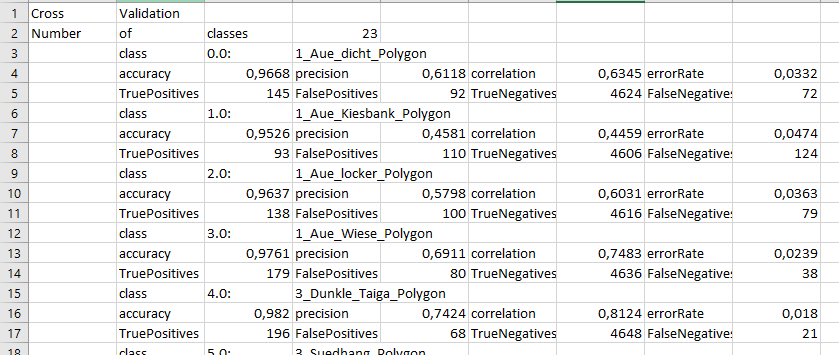
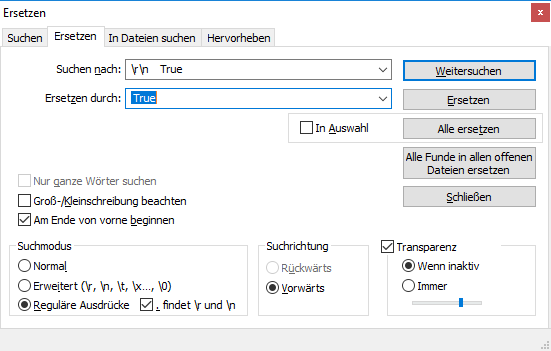
Can you help me to try with this table too. I followed your instruction but it doesn’t work in this case.
By the way, do you know how to upgrade from SNAP 6 to SNAP 7 without uninstall the previous version?
I think you can retrieve the values for the two classes without the automation.
Did you only use one band for the classification? This is critical for random forest classifiers, please have a look here: Random Forest Classifier: SNAP VS sklearn - #2 by ABraun
there is no need to uninstall the previous version, but you need to download version 7 and run it to overwrite the previous one.
Dear @ABraun, I am running Random Forest on [VV, VH, VV/VH] dataset (dB value) and this dataset plus GLCM texture bands. The idea was to evaluate the training accuracy and feature importance. I am following your implement in this article (Table 4, Figure 5), however it was not clear to me how to make it.
I’ve already uninstalled SNAP6 and reinstall SNAP7 before having your reply. Now, I am trying to configure some parameters to optimize the SNAP performance on my computer.
I didn’t use SNAP for this article, but technically, the classification modes in SNAP allow the computation of a feature ranking and training accuracy.