I am trying to run a supervised classification in SNAP. Every time I run the random forest classifier with vector trainning sites it classifies evrything as one class. I perform my classification as follows:
atmospheric correction using Sen2cor stand alone processor
load corrected image into snap and resample everything to 10m (using resampling tool under raster)
I create a spatial subset to minimise the extent of the image
I load trainning vectors and study site vector
create a land/sea mask to isolate just my study site
run a random forest supervised classifiction
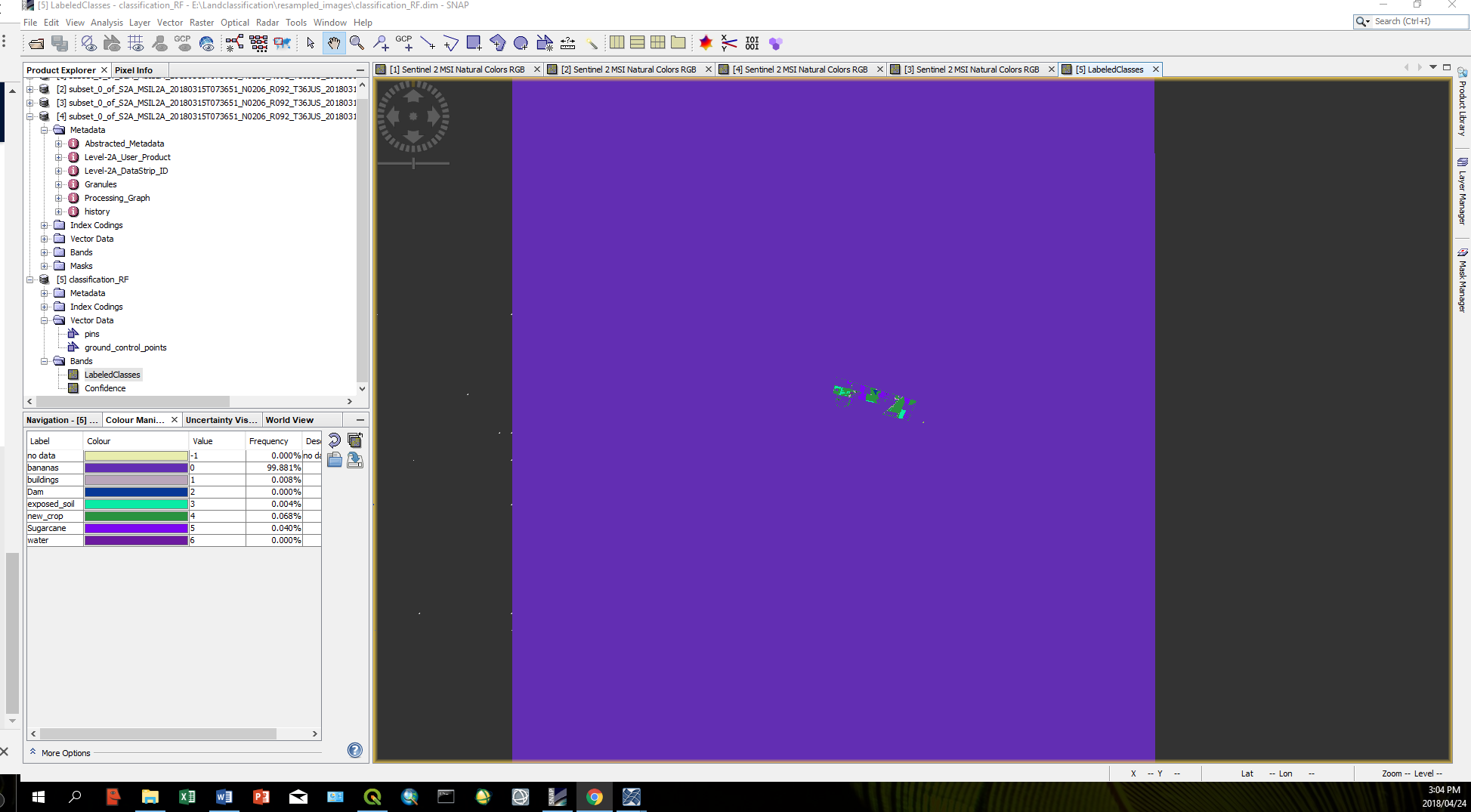
After running the random forest supervised classification, I then changed the confidence>=0. It then shows that one class has a frequency of 100%. I have tried multiple times and each time it generates an output with a different class contaning a frequency of 100%. I have 7 classes each with varrying numbers of training vector shapefiles in it. I have seen people saying that you should reproject your sentinel 2 image however the projections on the image and the shapfiles is the same and when i do try to reproject the sentinel image, it does not work it just displays a grey screen with the odd pink/red, green or blue pixel.
Your procedure looks good but two main issues I see:
After importing your training data, did you save the product? If not, do so to make sure the new version containing the training is used as input for the classification.
While it does not make sense from a theoretical point of view, my experience is that you have to reproject. So, we may want to solve this issue first and the run the classification again. Can you provide more details about that specifc step?
In case it helps, check this webinar for crop mapping with Sentinel-2 data. They used Random Forest and they explain the procedure step by step
I also found that video. I followed the exact same steps as in the video. I did save the product after importing the training vectors.
The issue comes in when I try to run the reprojection. I have just read your issue as in the following thread: Reprojection problem and am trying the work around mentioned. it is however taking a while, If that does not work I will send more details regarding the reprojection output errors.
It has now run the classification however it is including the masked pixels with the class given the zero value.
I think this has something to do with how the mask is classifying the masked pixels. I will try this process again and check the results. have you encountered this before?
I did notice that visually the colour of the image changes each time you run a reprojection, do you know if it is distorting the data in any way that will effect the classification or is this change something superficial?
masking rasters with a polygon in SNAP creates a raster of same size (which is not ideal) so you should maybe make these outer areas an own class in the training step so it will not influence the pixel statistics of other classes.
I have also applied the classification with creating the vector container as new classes and those classes use for the classification. After the classification there is no image appear in the image window while in the colour manipulation section frequency coloum show the ? to me.
Your training areas look really small. As stated here and in the SNAP help, the standard number of input pixels per tree is 5000. That means if you have less than 5000 training pixels at all, each run is based on the same subset. That makes the random forest approach quite ineffective.
If I may use this thread for issues with Random Forest Classification, please let me expose this one I have with a recent classification I’m trying to do.
I’ve applyied a land/sea mask to an MSI I have to define ROI of an admnistrative region. I want to classify this region and I tested MLC and RFClassifier. The thing is, the results for the MLC came all inside the region of interest wiht no attibut/class outside, but it didn’t happen for the RF, when using the same image bands and training areas.
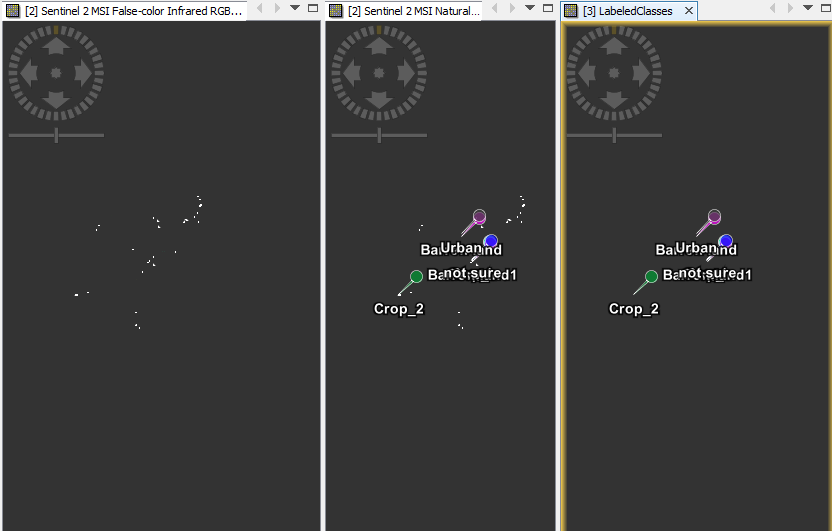
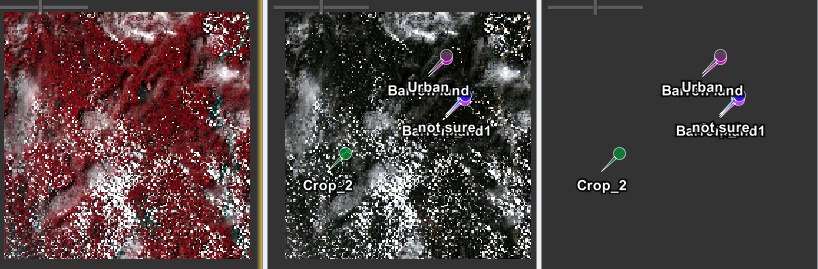
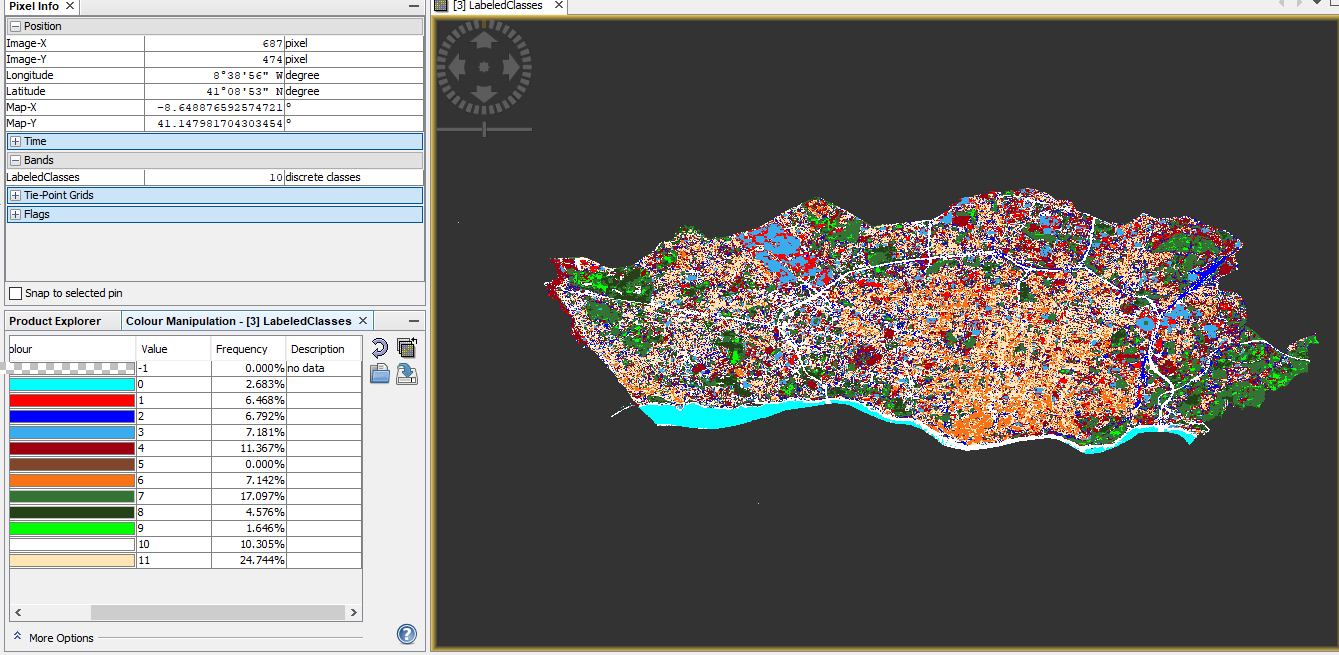
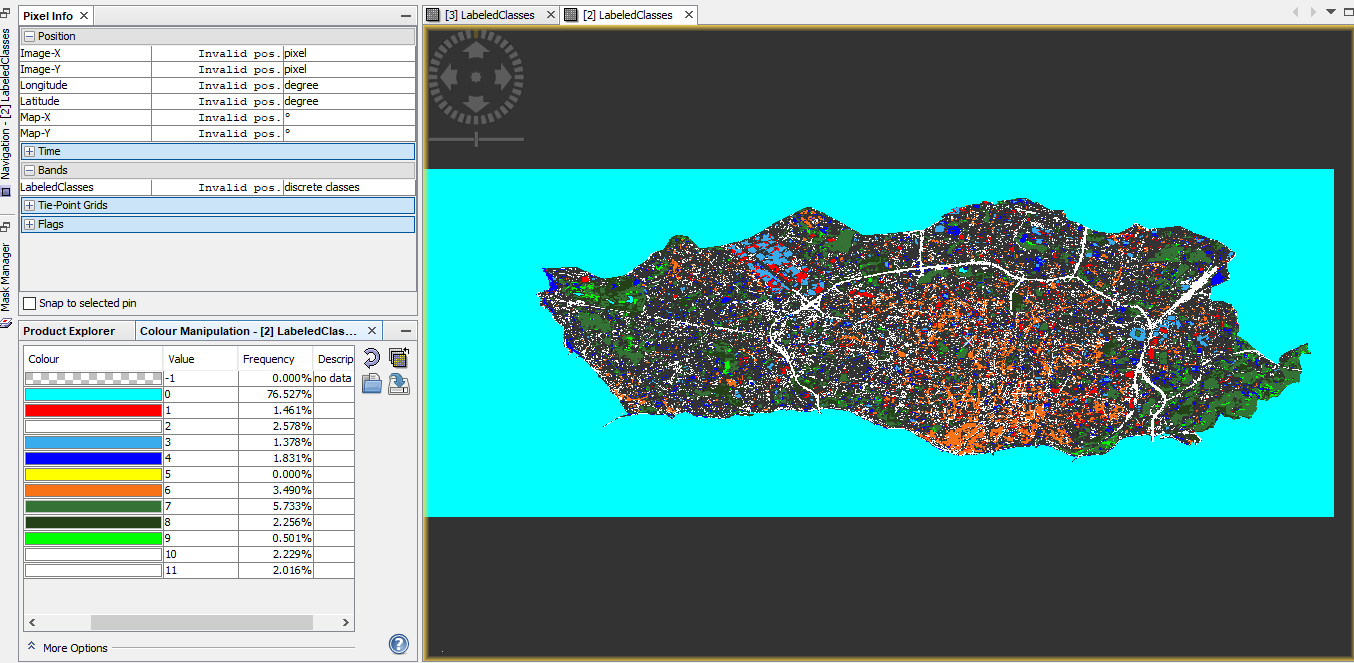
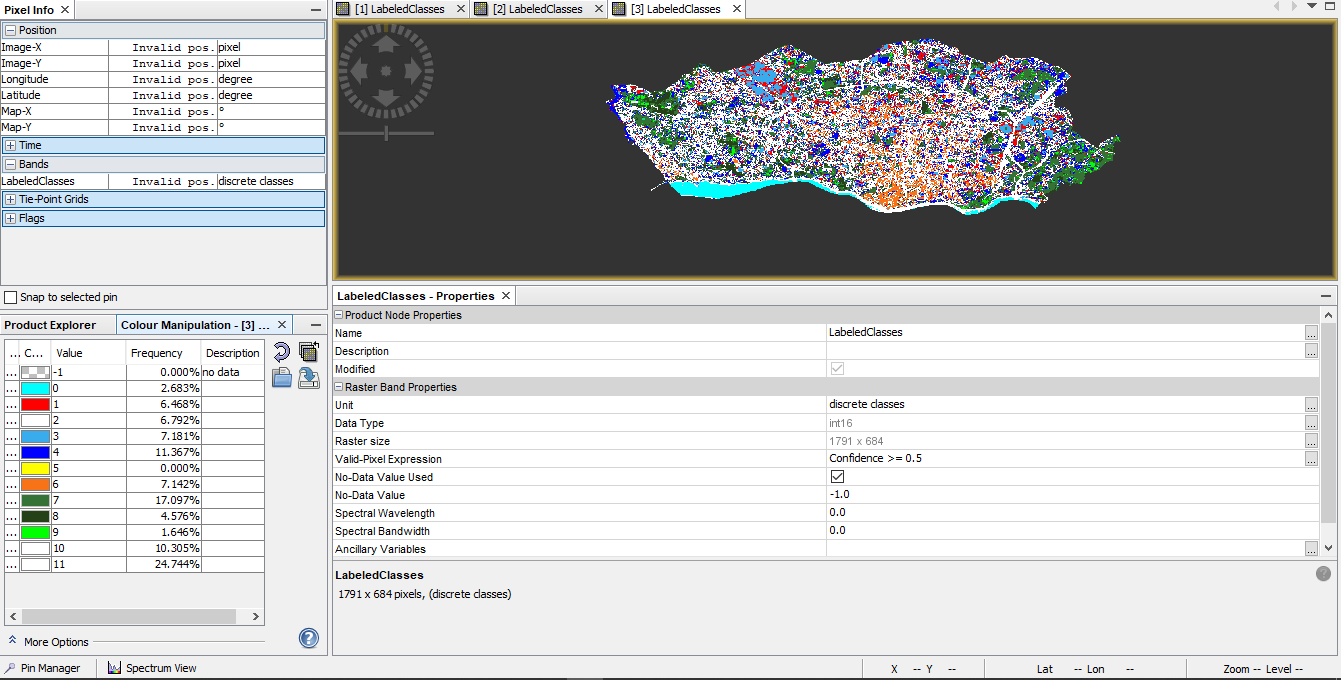
Here is two images, with the results for MLC and RF:
Is there any way to solve this issue? What could be happening with the results of RF or its inputs?
Another question I have and in this case it could be applied for the two classifiers, is why the percentages for the no data values are 0.000%? In the case of the RF labeled classes, there is a lot of pixels without any information (if you notice most of dark pixels are no information data).
Can any one please, help me, or know what is happenig with this results?
Thank you.
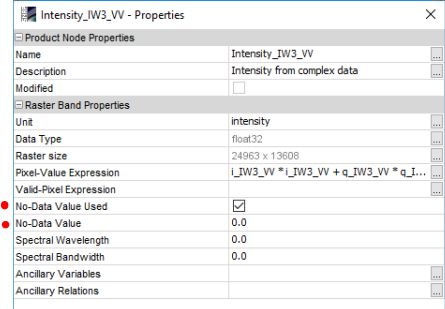
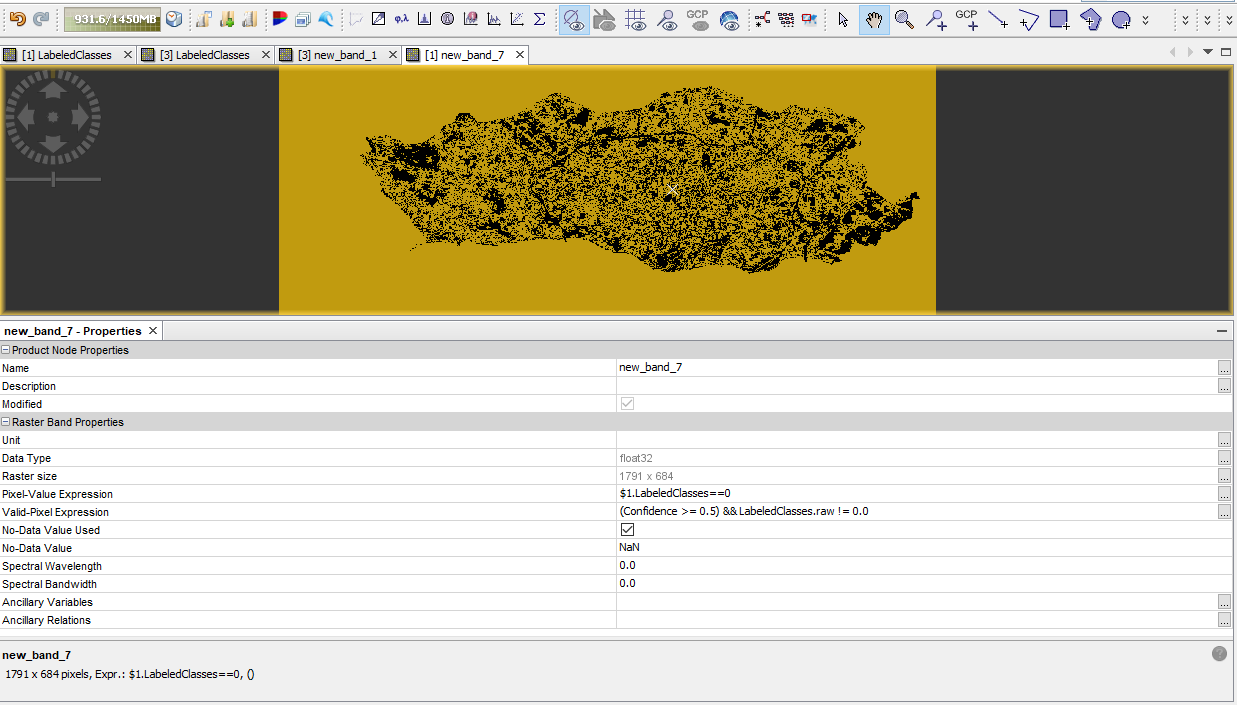
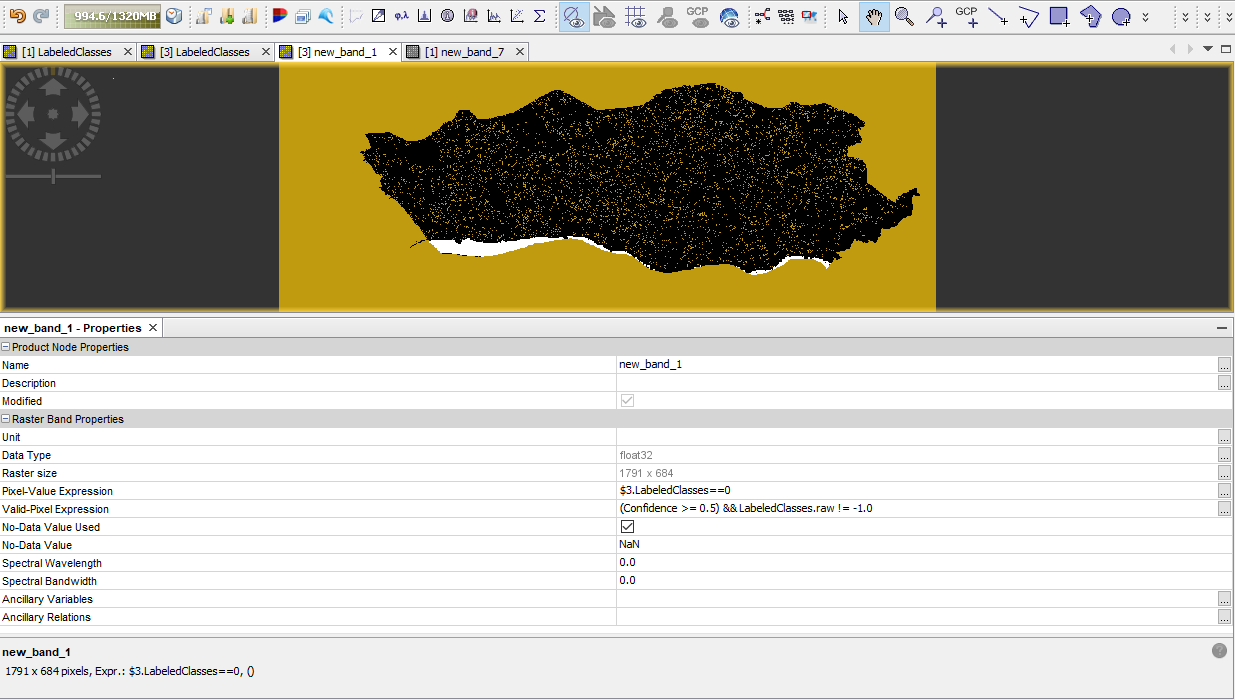
Hm, is it an option to just exclude the class? What happens when you open the band properties of the classified raster and check “No-Data value used” and define 0 as no data?
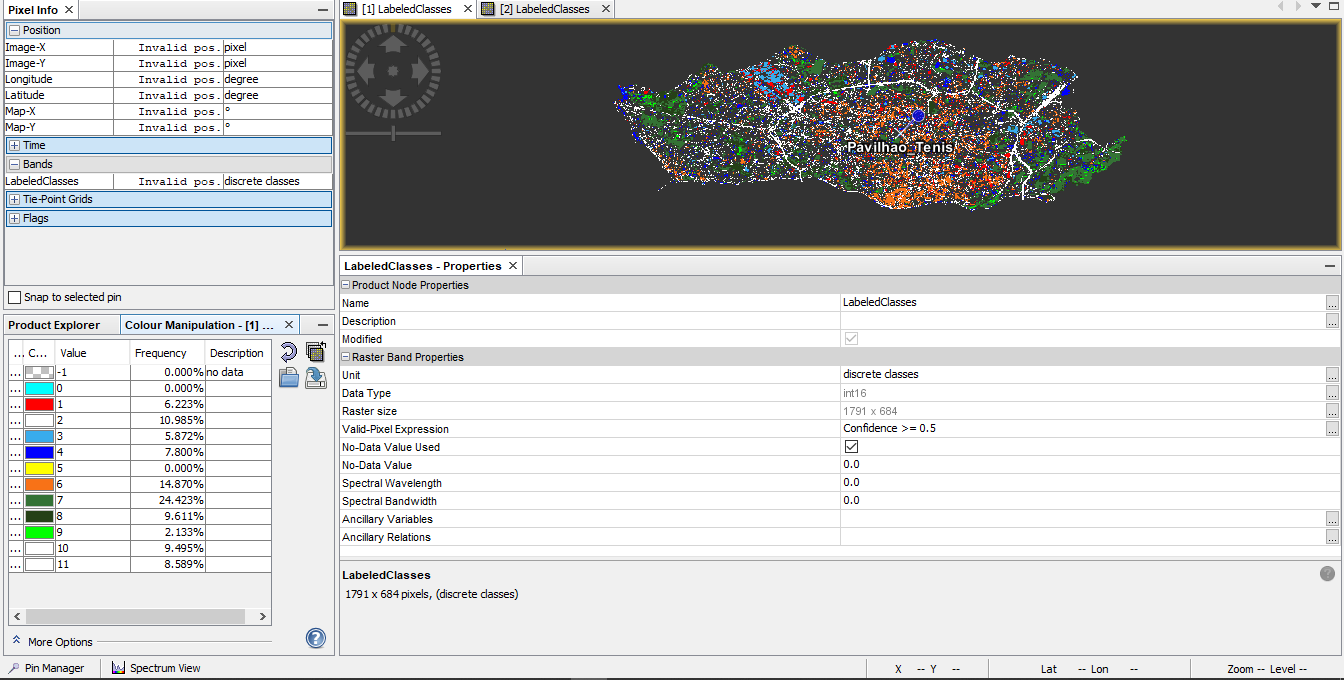
Wow!! Something really happened. I think you solve it!! Thank you a lot!! The results are similar to the MLC, I have to analyse this later , but comparing the percentages for both classifiers this seems to be the right direction (in the process though I have lost the water class representation at cyan colour, (value:0 for class) can it be done anyting about it ?)
Maybe the problem is just RF Classifier didn’t actual make it to classify the water from the start:
I just applied a band math expression, for class 0 to hightlight it between the two classifiers:
the random forest leaves 0 when the level of confidence is not reached (see links below). But of course, if water was in your training data, it should be included in the resulting classification. You can try masking out the water areas again, by creating a nodata mask before the classification and then apply it on the classified RF image.
I will take look to your advise and links to see how it works out.
Thank you so much ABraun for your time and attention.
You have been a helpful friend to me, I wich you all the best !!
The standard input pixels per tree is 5000 (For Random forest algorithm). Therefore, we couldn’t use single pixel for training data, right? I quite a bit confuse because the training data that I collected via GPS represent as point and I also 10-fold cross validation.
Should I make training data as polygon (base on field data collection)?
Is it okay for publication for doing that? (sorry some questions seem far from the forum)
you can use point samples, but as you say, if you have less than 5000, each tree is generated based on all available points and the advantage of permutation of a random forest classifier is partly lost (it also shuffles the input rasters).
You can create polygons around your samples to increase the number of potential samples. Your points collected in the field are a good base for this and I think it is scientifically correct to extend this points to representative area around.
If you have enough samples, you can also leave some of them out of the classification process and later use them for validation (did the classifier predict the correct class at the sampled location)?
if I have only 800 samples (points) and I decrease the input parameter: Number of training samples to 800 or 700, would it be enough for make classification ?
you either create polygons around your points (depending on the radius and pixel size, this already multiplies your input values) or you decrease the number of samples. To make it effective, I would reduce it to 2/3 of the whole data, so around 550.